单机模式Hadoop环境搭建
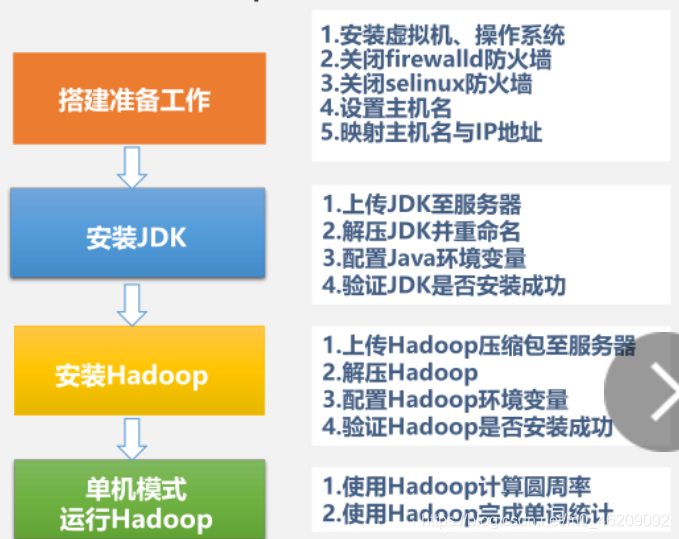
Hadoop环境搭建流程图
具体过程
文章目录
1.搭建准备工作
(1)关闭防火墙

systemctl stop firewalld //停止firewalld防火墙
systemctl disable firewalld //关闭防火墙开机自启
systemctl status firewalld //查看firewalld防火墙状态,看是否已关闭
(2)关闭selinux防火墙

vi /etc/sysconfig/selinux
SELINUX=disabled //将enforcing修改成disabled
(3)设置主机名

hostnamectl set-hostname ky002
hostname //显示主机名
(4)映射主机名与ip地址

ip add //查看ip地址
vi /etc/hosts //映射主机名与ip地址
//在最后一行加入ip地址及主机名
2.安装JDK
(1)下载jdk
在Oracle官网下载JDKlinux1.8以上的版本
(2)上传JDK至服务器
a.下载WinSCP软件
b.建立linux与windows之间文件互传
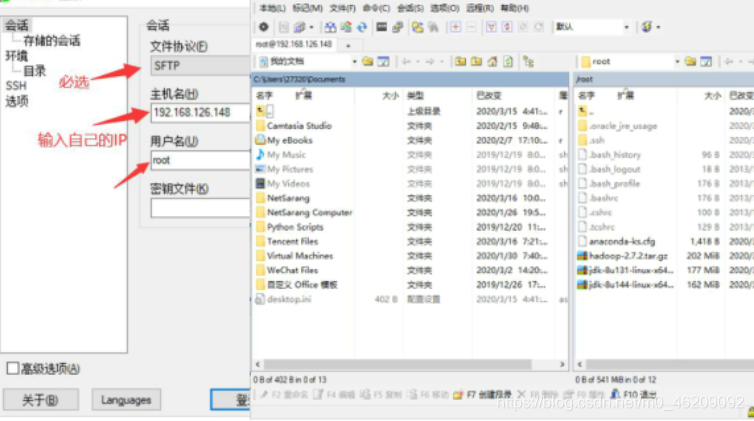
c.上传JDK至Linux
直接拖拽文件至Linux
(3)解压JDK并重命名
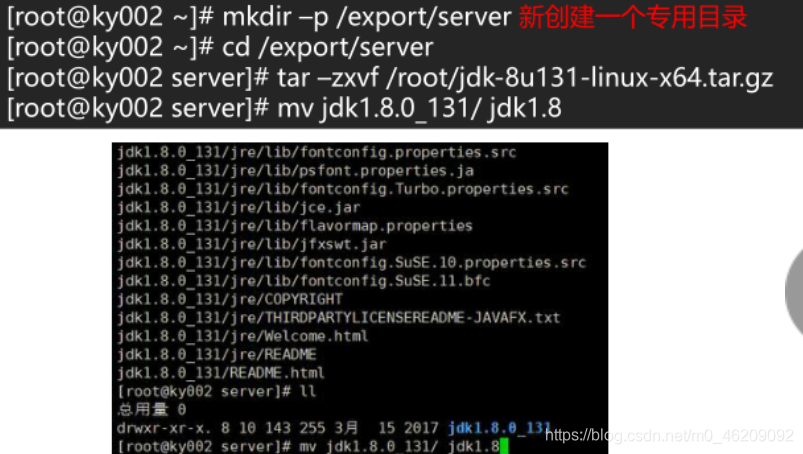
mkdir -p /export/server //创建一个专用目录
cd /export/server
tar -zxvf /root/jdk-8u131-liux-x64.tar.gz //解压jdk安装包 Tab键可以补全版本号
mv jdk1.8.0_131/ jdk1.8 //重命名jdk
(4)配置JAVA环境变量

pwd //显示java安装路径
vi /etc/profile //使用vi编辑器编辑配置文件 按i进入编辑
JAVA_HOME=/export/server/jdk1.8 //JAVA_HOME=jdk路径
export PATH=$PATH:$JAVA_HOME/bin //统一这么写
//按Esc退出编辑 shift+wq保存并退出
source /etc/profile //使设置的环境变量生效
(5)检查JDK是否安装成功
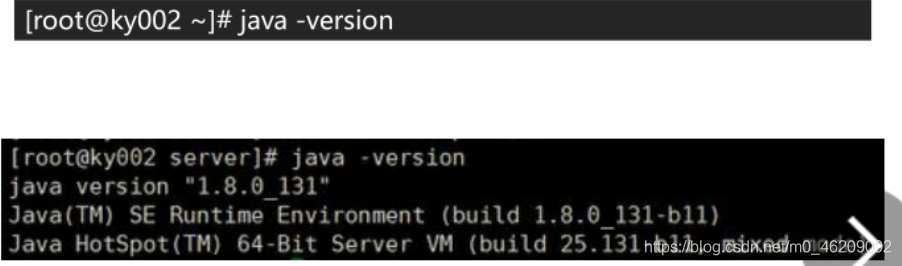
java -version //若成功则会出现jdk版本号信息
3.安装Hadoop
(1)上传Hadoop安装包至Linux
过程与上传jdk类似
a.进入官网下载安装包:[hadoop官网](http://hadoop.apache.org/)
b.使用WinSCP软件上传
(2)解压Hadoop安装包
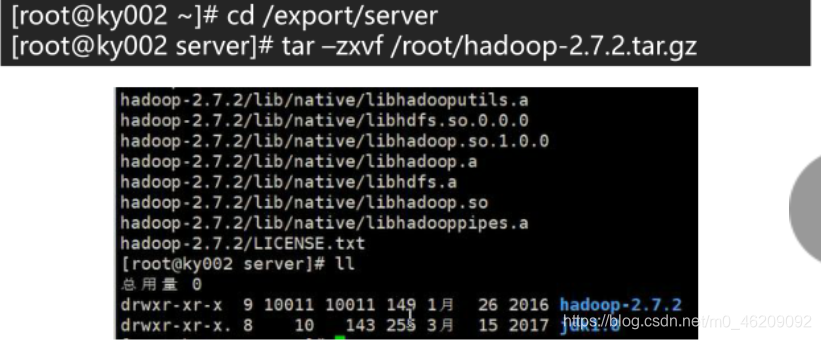
cd /export/server //进入专用目录
tar -zxvf /root/hadoop-2.7.2.tar.gz
(3)配置Hadoop环境变量

cd hadoop-2.7.2/
pwd //显示hadoop安装路径
vi /etc/profile //按i进入编辑
JAVA_HOME=/export/server/jdk1.8 //已有不用写
HADOOP_HOME=/export/server/hadoop-2.7.2 //HADOOP_HOME=hadoop安装路径
PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export JAVA_HOME HADOOP_HOME PATH
//按Esc退出编辑 shift+wq保存并退出
source /etc/profile //使设置的环境变量生效
(4)检查Hadoop是否安装成功

hadoop version //若成功则会出现hadoop版本号信息
4.单机模式运行Hadoop
Hadoop自带了一些MapReduce示例程序,这些程序代码都在hadoop-example.jar包内,jar包的安装目录在Hadoop下
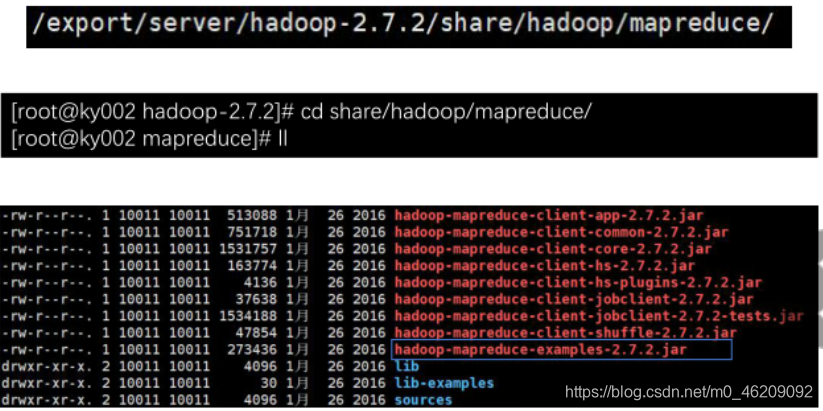
(1)计算圆周率

pi:程序名称
第一个参数:运行多少次map任务
第二个参数:每个map任务投掷多少次
二个参数之积即总投掷数(pi代码就是以投掷来计算值)
hadoop jar hadoop-mapreduce-examples-2.7.2.jar pi 5 5 //Tab键可以补全版本号
(2)完成单词统计

数据准备
cd /export/server/hadoop-2.7.2 //进入Hadoop安装目录
mkdir wcinput //创建wcinput
cd wcinput
vi word.txt //将单词数据存放到word.txt文件中

执行程序
cd /export/server/hadoop-2.7.2/
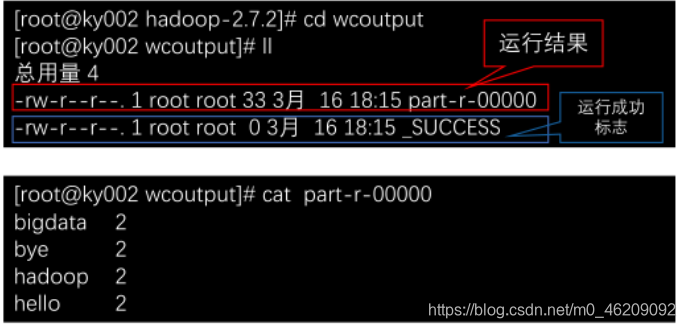
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount wcinput wcoutput
查看结果