数据仓库-拉链表, 流水表, 全量表, 增量表, 切片表
1 增量表
1.1 概念

增量表:新增数据,增量数据是上次导出之后的新数据。比如说,从24号到25号新增了那些数据,改变了哪些数据,这些都会存储在增量表的25号分区里面。
记录每次增加的量,而不是总量;
增量表,只报变化量,无变化不用报
每天一个分区
1.2 例子
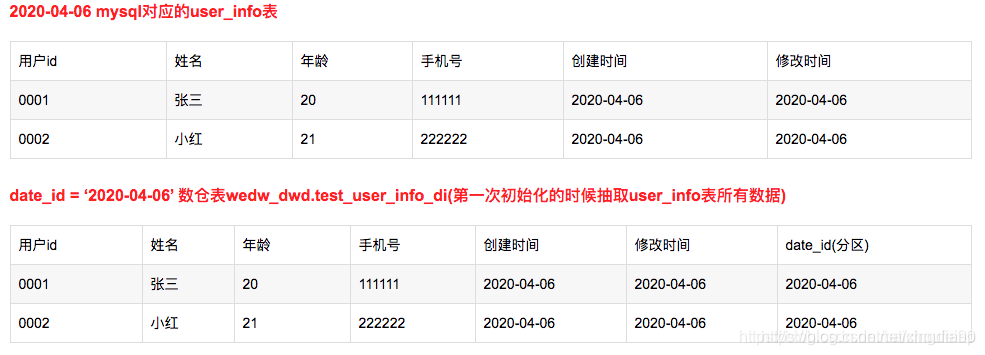
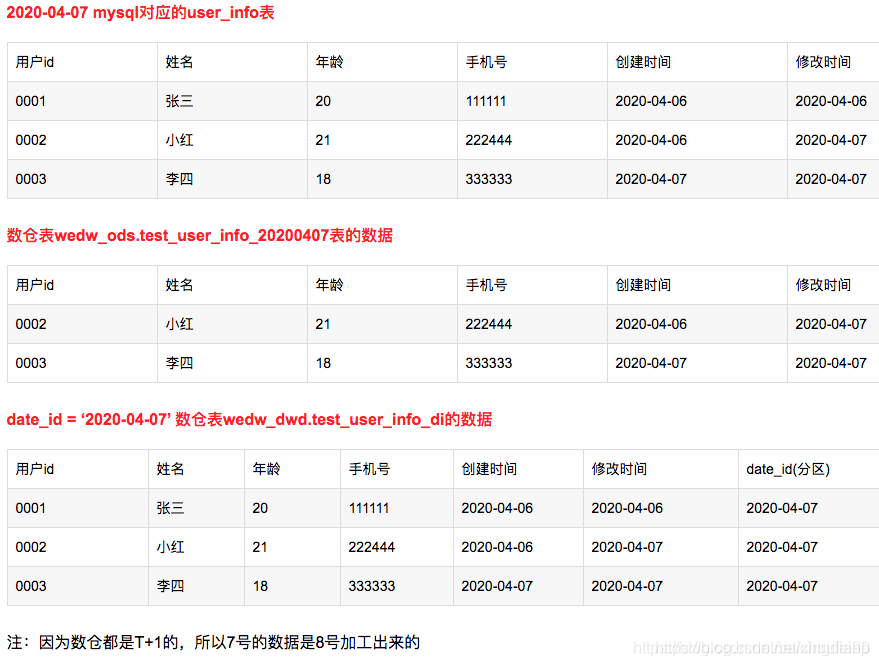
注:因为数仓都是T+1的,所以7号的数据是8号加工出来的
加工逻辑:
1.根据修改时间,把修改时间等于昨天(即7号)的数据抽取到ods层wedw_ods.test_user_info_20200407中
2.找出20200406未修改的数据放入20200407分区中
和数仓表wedw_dwd.test_user_info_di 分区date_id = ‘2020-04-06’通过主键用户id进行关联,先把wedw_dwd.test_user_info_di中存在且wedw_ods.test_user_info_20200407中不存在的数据插入到wedw_dwd.test_user_info_di分区date_id=2020-04-07中
3.最后把wedw_ods.test_user_info_20200407表的所有数据插入到wedw_dwd.test_user_info_di分区date_id=2020-04-07
insert overwrite table wedw_dwd.test_user_info_di PARTITION(date_id='2020-04-07')
select
a.user_id
,a.user_name
,a.user_age
,a.user_cellphone
,a.create_time
,a.update_time
from wedw_dwd.test_user_info_di a
left join wedw_ods.test_user_info_20200407 b
on b.user_id=a.user_id
where a.date_id = '2020-04-06'
and b.user_id is null;
insert into table wedw_dwd.test_user_info_di PARTITION(date_id='2020-04-07')
select
coalesce(user_id'-99') as user_id
,coalesce(user_name,'-99') as user_name
,coalesce(user_age,0) as user_age
,coalesce(user_cellphone,'-99') as user_cellphone
,coalesce(create_time,cast('1700-01-01 00:00:00' as timestamp )) as create_time
,coalesce(update_time,cast('1700-01-01 00:00:00' as timestamp )) as update_time
from wedw_ods.test_user_info_20200407 b ;
--仅保留近7天的分区
alter table wedw_dwd.test_user_info_di drop if EXISTS partition(date_id='2020-03-31');
特殊增量表:da表,每天的分区就是当天的数据,其数据特点就是数据产生后就不会发生变化,如日志表
2 全量表
2.1 概念

每天计算所有的数据,并覆盖写入全量表。
全量表,有无变化,都要报
每次上报的数据都是所有的数据(变化的 + 没有变化的)
只有一个分区(或者说没有分区)
每次往全量表里面写数据都会覆盖之前的数据,所以全量表不能记录数据历史变化,只有截止到当前最新的、全量的数据。
2.2 小结
缺点:
无法反映数据历史变化,只有截止到当天(t+1)最新的、全量的数据。
2.3 例子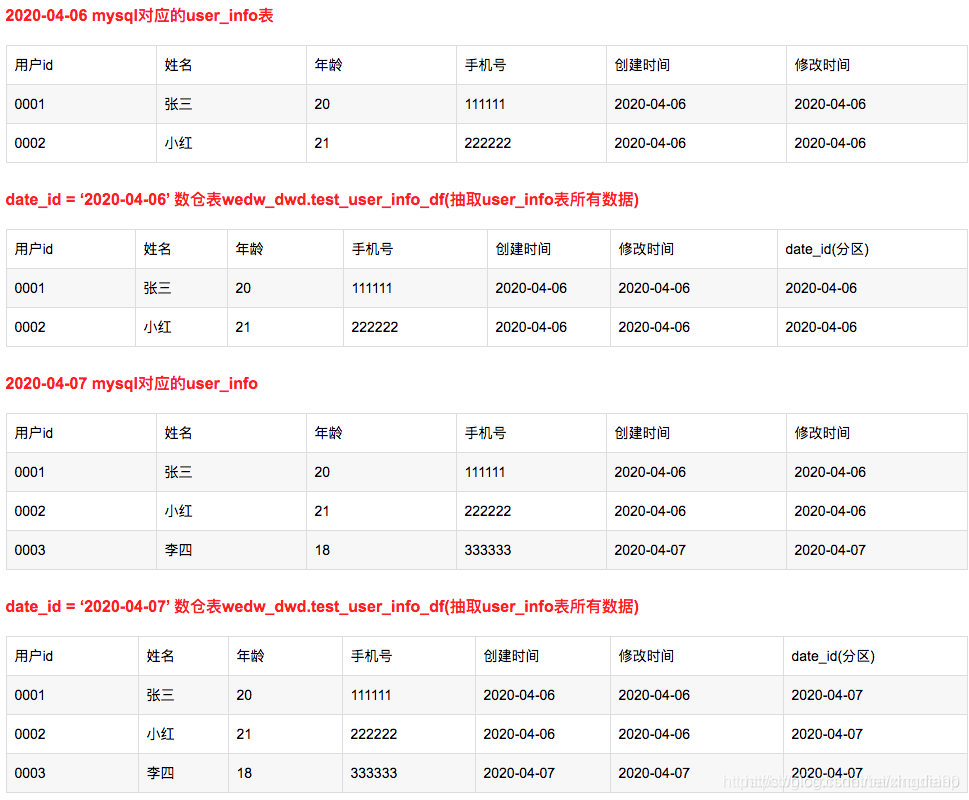
3 快照表
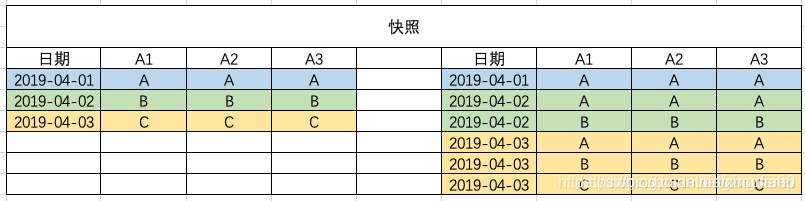
既然全量表无法反映历史,那么要能查到历史数据情况又该怎么办呢?这个时候快照表就派上用途了
按日分区,记录截止数据日期的全量数据(每个分区里面的数据都是分区时间对应的前一天的所有全量数据,t+1)
快照表,有无变化,都要报
每次上报的数据都是所有的数据(变化的 + 没有变化的)
每个分区里面的数据都是分区时间对应的前一天的所有全量数据,比如说当前数据表有3个分区,24号,25号,26号。其中,24号分区里面的数据就是从历史到23号的所有数据,25号分区里面的数据就是从历史到24号的所有数据,以此类推。
一天一个分区
快照表的25号分区和24号分区(都是t+1,实际时间分别对应26号和25号)的数据相减就是实际时间25号到26号有变化的、增加的数据,也就相当于增量表里面25号分区的数据。
缺点:
数据量大的时候,其实每个分区都存储了许多重复的数据,非常的浪费存储空间。
4 拉链表
4.1 概念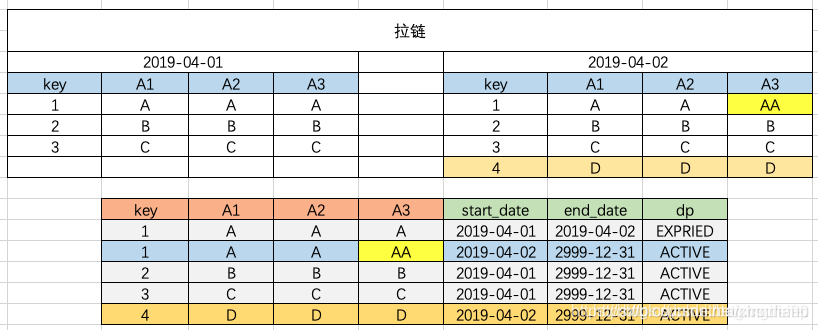
拉链表目的是解决快照表数据冗余问题,还能维护数据历史状态和最新状态。拉链表根据拉链粒度的不同,实际上相当于快照,只不过做了优化,去除了一部分不变的记录而已,通过拉链表可以很方便的还原出拉链时点的客户记录。
拉链表记录截止数据日期的全量数据
记录一个事物从开始,一直到当前状态的所有变化的信息;
拉链表每次上报的都是历史记录的最终状态,是记录在当前时刻的历史总量;
当前记录存的是当前时间之前的所有历史记录的最后变化量(总量);
一般只有一个分区
也可以有分区表,有些不变的数据或者是已经达到状态终点的数据就会放在分区里面,分区字段一般为开始时间:start_date和结束时间:end_date。一般在该天有效的数据,它的end_date是大于等于该天的日期的。
获取某一天全量的数据,可以通过表中的start_date和end_date来做筛选,选出固定某一天的数据。例如我想取截止到20190813的全量数据,其where过滤条件就是where start_date<=‘20190813’ and end_date>=20190813。
4.2 小结
适用情况:
数据量比较大
表中的部分字段会被更新
需要查看某一个时间点或者时间段的历史快照信息
查看某一个订单在历史某一个时间点的状态
某一个用户在过去某一段时间,下单次数
更新的比例和频率不是很大
如果表中信息变化不是很大,每天都保留一份全量,那么每次全量中会保存很多不变的信息,对存储是极大的浪费。此时可以用拉链表。
优点
满足反应数据的历史状态
最大程度节省存储
4.3 例子
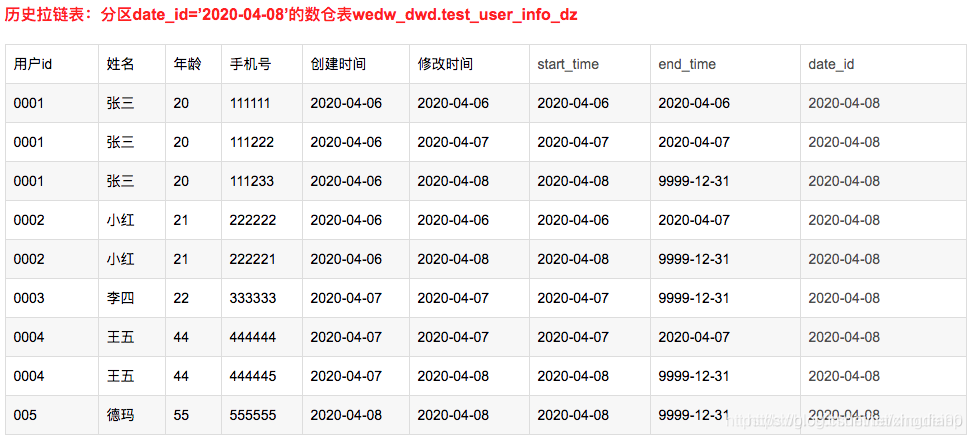
增加两个字段:
start_time
表示该条记录的生命周期开始时间——周期快照时的状态
end_time
该条记录的生命周期结束时间
end_time= ‘9999-12-31’ 表示该条记录目前处于有效状态
查询4月8日的所有有效的记录:
select * from wedw_dwd.test_user_info_dz where date_id = ‘2020-04-08’ and end_time = ‘9999-12-31’;
结果如下
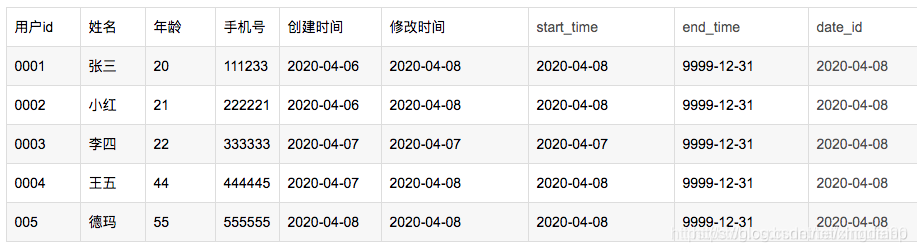
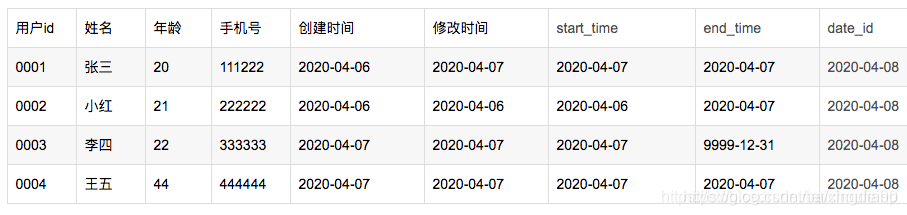
查询2020-04-07的历史快照:
select * from wedw_dwd.test_user_info_dz where date_id = ‘2020-04-08’ and start_time <= ‘2020-04-07’ and end_time >= ‘2020-04-07’;
结果如下:
加工逻辑:
注:第一次加工的时候需要初始化所有数据,start_time设置为数据日期2020-04-06 ,end_time设置为9999-12-31
--分桶
set hive.enforce.bucketing=FALSE;
--分区
set hive.exec.dynamic.partition=FALSE;
set hive.exec.dynamic.partition.mode=nostrick;
set hive.exec.compress.output=true;
set mapred.output.compress=true;
set mapred.output.compression.type=BLOCK;
set mapred.output.compression.codec=org.apache.hadoop.io.compress.SnappyCodec;
alter table wedw_dwd.test_user_info_dz drop if EXISTS PARTITION(date_id='${HIVE_DATA_DATE}');
-- wedw_dwd.test_user_info_dz 存在, wedw_ods.test_user_info_${DATA_DATE} 不存在的
--或者都存在的闭链的 插入到 wedw_dwd.test_user_info_dz 下一个分区
insert overwrite table wedw_dwd.test_user_info_dz PARTITION(date_id='${HIVE_DATA_DATE}')
select
a.user_id
,a.user_name
,a.user_age
,a.user_cellphone
,a.create_time
,a.update_time
,a.start_time
,a.end_time
from wedw_dwd.test_user_info_dz a
left join wedw_ods.test_user_info_${DATA_DATE} b on b.user_id=a.user_id and b.create_time < '${HIVE_DATA_DATE+1}'
where a.date_id = '${HIVE_DATA_DATE-1}'
and (b.user_id is null
or (b.user_id is not null and a.end_time <='${HIVE_DATA_DATE-1}')
)
;
-- 把wedw_dwd.test_user_info_dz, wedw_ods.test_user_info_${DATA_DATE} 都存在的开链的 全部闭链 插入到 wedw_dwd.test_user_info_dz 下一个分区
insert into table wedw_dwd.test_user_info_dz PARTITION(date_id='${HIVE_DATA_DATE}')
select
a.user_id
,a.user_name
,a.user_age
,a.user_cellphone
,a.create_time
,a.update_time
,a.start_time
,'${HIVE_DATA_DATE-1}' end_time
from wedw_dwd.test_user_info_dz a
inner join wedw_ods.test_user_info_${DATA_DATE} b on b.user_id=a.user_id and b.create_time < '${HIVE_DATA_DATE+1}'
where a.date_id = '${HIVE_DATA_DATE-1}'
and a.end_time >'${HIVE_DATA_DATE-1}'
;
-- 把wedw_ods.test_user_info_${DATA_DATE}, 插入到 wedw_dwd.test_user_info_dz 下一个分区
insert into table wedw_dwd.test_user_info_dz PARTITION(date_id='${HIVE_DATA_DATE}')
select
a.user_id
,a.user_name
,a.user_age
,a.user_cellphone
,a.create_time
,a.update_time
,'${HIVE_DATA_DATE}' start_time,
,'9999-12-31' end_time
from wedw_ods.test_user_info_${DATA_DATE} b
where b.create_time < '${HIVE_DATA_DATE+1}';
--仅保留近7天的数据
alter table wedw_dwd.test_user_info_dz drop if EXISTS partition(date_id='${HIVE_DATA_DATE-7}');
5 流水表
5.1 概念
对于表的每一个修改都会记录,可以用于反映实际记录的变更。
5.2 流水表与拉链表区别
拉链表通常是对账户信息的历史变动进行处理保留的结果,流水表是每天的交易形成的历史;
流水表用于统计业务相关情况,拉链表用于统计账户及客户的情况
6 切片表
切片表根据基础表,往往只反映某一个维度的相应数据。其表结构与基础表结构相同,但数据往往只有某一维度,或者某一个事实条件的数据
转自https://blog.csdn.net/xingdianp/article/details/110307783