反射
反射指的是程序可以访问、检测和修改它本身状态或行为的一种能力(自省)
python面向对象中的反射:通过字符串的形式操作对象相关的属性。python中的一切事物都是对象(都可以使用反射)
我们先来看对实例化对象的示例:
class Foo: f='类的静态变量' def __init__(self,name,age): self.name=name self.age=age def say_hi(self): print('hi,%s'%self.name) obj=Foo('凝宝',21) #检测是否含有某种属性 print(hasattr(obj,'name')) #True print(hasattr(obj,'say_hi')) #True #获取属性 n=getattr(obj,'name') print(n) #凝宝 func=getattr(obj,'say_hi') func() #hi,凝宝 # print(getattr(obj,'aaa','不存在')) #报错 #设置属性 setattr(obj,'hobby',True) setattr(obj,'show_name',lambda self:self.name+'hobby') print(obj.__dict__) #{'name': '凝宝', 'age': 21, 'hobby': True, 'show_name': <function <lambda> at 0x0000019356C9C378>} print(obj.show_name(obj)) #凝宝hobby #删除属性 delattr(obj,'age') delattr(obj,'show_name') # delattr(obj,'show_name11') #报错 print(obj.__dict__) #{'name': '凝宝', 'hobby': True}
对类的反射示例:
class Foo(object): staticField='ningbao' def __init__(self): self.name='凝宝' def func(self): return 'func' @staticmethod def bar(): return 'bar' print(getattr(Foo,'staticField')) #ningbao print(getattr(Foo,'func')) #<function Foo.func at 0x00000244A43EA9D8> print(getattr(Foo,'bar')) #<function Foo.bar at 0x00000244A43EAA60>
当前模块的反射:
import sys def s1(): print('s1') def s2(): print('s2') this_module=sys.modules[__name__] print(hasattr(this_module,'s1')) #True print(hasattr(this_module,'s2')) #True
其他模块的示例:
#一个模块中的代码 def test(): print('from the test') """ 程序目录: module_test.py index.py 当前文件: index.py """ # 另一个模块中的代码 import module_test as obj #obj.test() print(hasattr(obj,'test')) getattr(obj,'test')()
了解完反射的四个函数后,我们不禁疑问:反射有什么作用?其应用场景又是什么呢?
现在让我们打开浏览器,访问一个网站,你单击登录就跳转到登录界面,你单击注册就跳转到注册界面,等等,其实你单击的其实是一个个的链接,每一个链接都会有一个函数或者方法来处理。
没学反射之前:
class User: def login(self): print('欢迎来到登录界面') def register(self): print('欢迎来到注册页面') def save(self): print('欢迎来到保存页面') while 1: choose=input('>>>').strip() if choose=='login': obj=User() obj.login() elif choose=='register': obj=User() obj.register() elif choose=='save': obj=User() obj.save()
学完反射后:
class User: def login(self): print('欢迎来到登录界面') def register(self): print('欢迎来到注册页面') def save(self): print('欢迎来到保存页面') user=User() while 1: choose=input('>>>').strip() if hasattr(user,choose): func=getattr(user,choose) func() else: print('输入错误...')
函数VS方法
之前我们一直称len()为函数,而称str的srip为方法,这其中有什么区别呢?
通过打印函数(方法)名确定
def func(): pass print(func) #<function func at 0x000001934624C378> class A: def func(self): pass print(func) #<function func at 0x000001934624C378> obj=A() print(obj.func) #<bound method A.func of <__main__.A object at 0x0000019347DA1DD8>>
通过types模块验证
from types import FunctionType from types import MethodType def func(): pass class A: def func(self): pass obj=A() print(isinstance(func,FunctionType)) #True print(isinstance(A.func,FunctionType)) #True print(isinstance(obj.func,FunctionType)) #False print(isinstance(obj.func,MethodType)) #True
静态方法是函数
from types import FunctionType from types import MethodType class A: def func(self): pass @classmethod def func1(self): pass @staticmethod def func2(self): pass obj=A() #静态方法其实是函数 print(isinstance(A.func2,FunctionType)) #True print(isinstance(obj.func2,FunctionType)) #True
函数与方法的区别
那么,函数和方法除了上述的不同之处,我们还总结了一下几点区别。
(1)函数的是显式传递数据的。如我们要指明为len()函数传递一些要处理数据。
(2)函数则跟对象无关。
(3)方法中的数据则是隐式传递的。
(4)方法可以操作类内部的数据。
(5)方法跟对象是关联的。如我们在用strip()方法是,是不是都是要通过str对象调用,比如我们有字符串s,然后s.strip()这样调用。是的,strip()方法属于str对象。
我们或许在日常中会口语化称呼函数和方法时不严谨,但是我们心中要知道二者之间的区别。
双下方法
定义:双下方法是特殊方法,他是解释器提供的,其形式为__方法名__
调用:不同的双下方法有不同的触发方式
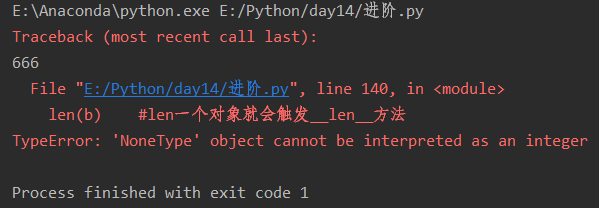
__len__
class B: def __len__(self): print(666) b=B() len(b) #len一个对象就会触发__len__方法 class A: def __init__(self): self.a=1 self.b=2 def __len__(self): return len(self.__dict__) a=A() print(len(a))
__hash__
class A: def __init__(self): self.a=1 self.b=2 def __hash__(self): return hash(str(self.a)+str(self.b)) a=A() print(hash(a)) #1941954079067552
__str__
如果一个类中定义了__str__方法,那么在打印 对象 时,默认输出该方法的返回值。
class A: def __init__(self): pass def __str__(self): return '凝宝' a=A() print(a) #凝宝 print('%s'%a) #凝宝
__repr__
如果一个类中定义了__repr__方法,那么在repr(对象) 时,默认输出该方法的返回值。
class A: def __init__(self): pass def __repr__(self): return '凝宝' a=A() print(repr(a)) #凝宝 print('%r'%a) #凝宝
__call__
对象后面加括号,触发执行。
注:构造方法__new__的执行是由创建对象触发的,即:对象 = 类名() ;而对于 __call__ 方法的执行是由对象后加括号触发的,即:对象() 或者 类()()
class Foo: def __init__(self): pass def __call__(self, *args, **kwargs): print('__call__') #执行__init__ obj=Foo() #执行__call__ obj() #__call__
__eq__
class A: def __init__(self): self.a=1 self.b=2 def __eq__(self, obj): if self.a==obj.a and self.b==obj.b: return True a=A() b=A() print(a==b) #True
__del__
析构方法,当对象在内存中被释放时,自动触发执行。
注:此方法一般无须定义,因为Python是一门高级语言,程序员在使用时无需关心内存的分配和释放,因为此工作都是交给Python解释器来执行,所以,析构函数的调用是由解释器在进行垃圾回收时自动触发执行的。
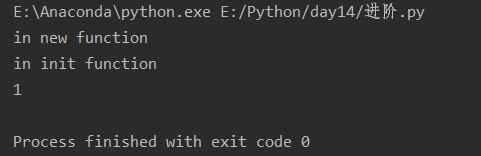
__new__
class A: def __init__(self): self.x = 1 print('in init function') def __new__(cls, *args, **kwargs): print('in new function') return object.__new__(A, *args, **kwargs) a = A() print(a.x)
单例模式
class A: __instance = None def __new__(cls, *args, **kwargs): if cls.__instance is None: obj = object.__new__(cls) cls.__instance = obj return cls.__instance


单例模式是一种常用的软件设计模式。在它的核心结构中只包含一个被称为单例类的特殊类。通过单例模式可以保证系统中一个类只有一个实例而且该实例易于外界访问,从而方便对实例个数的控制并节约系统资源。如果希望在系统中某个类的对象只能存在一个,单例模式是最好的解决方案。
【采用单例模式动机、原因】
对于系统中的某些类来说,只有一个实例很重要,例如,一个系统中可以存在多个打印任务,但是只能有一个正在工作的任务;一个系统只能有一个窗口管理器或文件系统;一个系统只能有一个计时工具或ID(序号)生成器。如在Windows中就只能打开一个任务管理器。如果不使用机制对窗口对象进行唯一化,将弹出多个窗口,如果这些窗口显示的内容完全一致,则是重复对象,浪费内存资源;如果这些窗口显示的内容不一致,则意味着在某一瞬间系统有多个状态,与实际不符,也会给用户带来误解,不知道哪一个才是真实的状态。因此有时确保系统中某个对象的唯一性即一个类只能有一个实例非常重要。
如何保证一个类只有一个实例并且这个实例易于被访问呢?定义一个全局变量可以确保对象随时都可以被访问,但不能防止我们实例化多个对象。一个更好的解决办法是让类自身负责保存它的唯一实例。这个类可以保证没有其他实例被创建,并且它可以提供一个访问该实例的方法。这就是单例模式的模式动机。
【单例模式优缺点】
【优点】
一、实例控制
单例模式会阻止其他对象实例化其自己的单例对象的副本,从而确保所有对象都访问唯一实例。
二、灵活性
因为类控制了实例化过程,所以类可以灵活更改实例化过程。
【缺点】
一、开销
虽然数量很少,但如果每次对象请求引用时都要检查是否存在类的实例,将仍然需要一些开销。可以通过使用静态初始化解决此问题。
二、可能的开发混淆
使用单例对象(尤其在类库中定义的对象)时,开发人员必须记住自己不能使用new关键字实例化对象。因为可能无法访问库源代码,因此应用程序开发人员可能会意外发现自己无法直接实例化此类。
三、对象生存期
不能解决删除单个对象的问题。在提供内存管理的语言中(例如基于.NET Framework的语言),只有单例类能够导致实例被取消分配,因为它包含对该实例的私有引用。在某些语言中(如 C++),其他类可以删除对象实例,但这样会导致单例类中出现悬浮引用
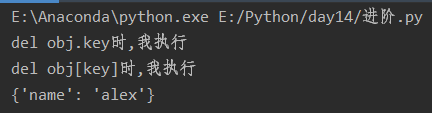
__item__系列
class Foo: def __init__(self,name): self.name=name def __getitem__(self, item): print(self.__dict__[item]) def __setitem__(self, key, value): self.__dict__[key]=value def __delitem__(self, key): print('del obj[key]时,我执行') self.__dict__.pop(key) def __delattr__(self, item): print('del obj.key时,我执行') self.__dict__.pop(item) f1=Foo('sb') f1['age']=18 f1['age1']=19 del f1.age1 del f1['age'] f1['name']='alex' print(f1.__dict__)
上下文管理器相关
__enter__ __exit__
class Diycontextor: def __init__(self,name,mode): self.name = name self.mode = mode def __enter__(self): print "Hi enter here!!" self.filehander = open(self.name,self.mode) return self.filehander def __exit__(self,*para): print "Hi exit here" self.filehander.close() with Diycontextor('py_ana.py','r') as f: for i in f: print i
异常和错误
part one:程序中难免出现错误,而错误分两种
1.语法错误(这种错误,根本过不了python解释器的语法检测,必须在程序执行前就改正)
#语法错误示范一 if #语法错误示范二 def test: pass #语法错误示范三 print(haha
2.逻辑错误(逻辑错误)
#用户输入不完整(比如输入为空)或者输入非法(输入不是数字) num=input(">>: ") int(num) #无法完成计算 res1=1/0 res2=1+'str'
part two:什么是异常
异常就是程序运行时发生错误的信号,在python中,错误触发的异常如下
part three:python中的异常种类
在python中不同的异常可以用不同的类型(python中统一了类与类型,类型即类)去标识,不同的类对象标识不同的异常,一个异常标识一种错误
# 触发IndexError l=['egon','aa'] l[3] # 触发KeyError dic={'name':'egon'} dic['age'] #触发ValueError s='hello' int(s)
AttributeError 试图访问一个对象没有的树形,比如foo.x,但是foo没有属性x IOError 输入/输出异常;基本上是无法打开文件 ImportError 无法引入模块或包;基本上是路径问题或名称错误 IndentationError 语法错误(的子类) ;代码没有正确对齐 IndexError 下标索引超出序列边界,比如当x只有三个元素,却试图访问x[5] KeyError 试图访问字典里不存在的键 KeyboardInterrupt Ctrl+C被按下 NameError 使用一个还未被赋予对象的变量 SyntaxError Python代码非法,代码不能编译(个人认为这是语法错误,写错了) TypeError 传入对象类型与要求的不符合 UnboundLocalError 试图访问一个还未被设置的局部变量,基本上是由于另有一个同名的全局变量, 导致你以为正在访问它 ValueError 传入一个调用者不期望的值,即使值的类型是正确的
异常处理
什么是异常??
异常发生之后
异常之后的代码就不执行了
什么是异常处理?
python解释器检测到错误,触发异常(也允许程序员自己触发异常)
程序员编写特定的代码,专门用来捕捉这个异常(这段代码与程序逻辑无关,与异常处理有关)
如果捕捉成功则进入另外一个处理分支,执行你为其定制的逻辑,使程序不会崩溃,这就是异常处理
为什么要进行异常处理?
python解析器去执行程序,检测到了一个错误时,触发异常,异常触发后且没被处理的情况下,程序就在当前异常处终止,后面的代码不会运行,谁会去用一个运行着突然就崩溃的软件。
所以你必须提供一种异常处理机制来增强你程序的健壮性与容错性
如何进行异常处理?
首先须知,异常是由程序的错误引起的,语法上的错误跟异常处理无关,必须在程序运行前就修正
一、使用if判断式
正常代码:
num1=input('>>: ') #输入一个字符串试试 int(num1)
num1=input('>>: ') #输入一个字符串试试 if num1.isdigit(): int(num1) #我们的正统程序放到了这里,其余的都属于异常处理范畴 elif num1.isspace(): print('输入的是空格,就执行我这里的逻辑') elif len(num1) == 0: print('输入的是空,就执行我这里的逻辑') else: print('其他情情况,执行我这里的逻辑') ''' 问题一: 使用if的方式我们只为第一段代码加上了异常处理,但这些if,跟你的代码逻辑并无关系,这样你的代码会因为可读性差而不容易被看懂 问题二: 这只是我们代码中的一个小逻辑,如果类似的逻辑多,那么每一次都需要判断这些内容,就会倒置我们的代码特别冗长。 '''
总结:
1.if判断式的异常处理只能针对某一段代码,对于不同的代码段的相同类型的错误你需要写重复的if来进行处理。
2.在你的程序中频繁的写与程序本身无关,与异常处理有关的if,会使得你的代码可读性极其的差
3.if是可以解决异常的,只是存在1,2的问题,所以,千万不要妄下定论if不能用来异常处理。
二、python异常处理的‘私人订制’
python:为每一种异常定制了一个类型,然后提供了一种特定的语法结构用来进行异常处理
part one:基本语法
try:
被检测的代码块
except 异常类型:
try中一旦检测到异常,就执行这个位置的逻辑
try: f = open('a.txt') g = (line.strip() for line in f) print(next(g)) print(next(g)) print(next(g)) print(next(g)) print(next(g)) except StopIteration: f.close() ''' next(g)会触发迭代f,依次next(g)就可以读取文件的一行行内容,无论文件a.txt有多大,同一时刻内存中只有一行内容。 提示:g是基于文件句柄f而存在的,因而只能在next(g)抛出异常StopIteration后才可以执行f.close() '''
part two:异常类只能用来处理指定的异常情况
# 未捕获到异常,程序直接报错 s1 = 'hello' try: int(s1) except IndexError as e: print e
part three:多分支
s1 = 'hello' try: int(s1) except IndexError as e: print(e) except KeyError as e: print(e) except ValueError as e: print(e)
part four:万能异常Exception
他可以捕获任意异常,即:
s1 = 'hello'
try:
int(s1)
except Exception as e:
print(e)
你可能会说既然有万能异常,那么我直接用上面的这种形式就好了,其他异常可以忽略
你说的没错,但是应该分两种情况去看
1.如果你想要的效果是,无论出现什么异常,我们统一丢弃,或者使用同一段代码逻辑去处理他们,那么骚年,大胆的去做吧,只有一个Exception就足够了。
s1 = 'hello' try: int(s1) except Exception,e: '丢弃或者执行其他逻辑' print(e) #如果你统一用Exception,没错,是可以捕捉所有异常,但意味着你在处理所有异常时都使用同一个逻辑去处理(这里说的逻辑即当前expect下面跟的代码块)
2.如果你想要的效果是,对于不同的异常我们需要定制不同的处理逻辑,那就需要用到多分支了
s1 = 'hello' try: int(s1) except IndexError as e: print(e) except KeyError as e: print(e) except ValueError as e: print(e)
s1 = 'hello' try: int(s1) except IndexError as e: print(e) except KeyError as e: print(e) except ValueError as e: print(e) except Exception as e: print(e)
part five:异常的其他机构
s1 = 'hello' try: int(s1) except IndexError as e: print(e) except KeyError as e: print(e) except ValueError as e: print(e) #except Exception as e: # print(e) else: print('try内代码块没有异常则执行我') finally: print('无论异常与否,都会执行该模块,通常是进行清理工作')
part six:主动触发异常
try:
raise TypeError('类型错误')
except Exception as e:
print(e)
part seven:自定义异常
class EvaException(BaseException): def __init__(self,msg): self.msg=msg def __str__(self): return self.msg try: raise EvaException('类型错误') except EvaException as e: print(e)
part eight:断言
# assert 条件 assert 1 == 1 assert 1 == 2
part nine:try...except的方式比较if的方式的好处
try..except这种异常处理机制就是取代if那种方式,让你的程序在不牺牲可读性的前提下增强健壮性和容错性
异常处理中为每一个异常定制了异常类型(python中统一了类与类型,类型即类),对于同一种异常,一个except就可以捕捉到,可以同时处理多段代码的异常(无需‘写多个if判断式’)减少了代码,增强了可读性
使用try..except的方式
1:把错误处理和真正的工作分开来
2:代码更易组织,更清晰,复杂的工作任务更容易实现;
3:毫无疑问,更安全了,不至于由于一些小的疏忽而使程序意外崩溃了;
什么时候用异常处理?
try...except应该尽量少用,因为它本身就是你附加给你的程序的一种异常处理的逻辑,与你的主要的工作是没有关系的
这种东西加的多了,会导致你的代码可读性变差,只有在有些异常无法预知的情况下,才应该加上try...except,其他的逻辑错误应该尽量修正