消费者的实例化
关于consumer的默认实现,metaq有两种:
- DefaultMQPullConsumer:由业务方主动拉取消息
- DefaultMQPushConsumer:通过业务方注册回调方法,由metaq主动推送消息
共同点:
都是消费者,也都提供了start,shutdown方法(吐个槽,这种公用的接口应该MQConsumer接口中,而不是MQPullConsumer与MQPushConsumer各搞一个)
不同点:
具体消费模式不同,PullConsumer提供了各种获取消息的方法,MQPushConsumer提供了各种订阅注册的方法来回调处理
同一类型的消费者通过consumerGroup来区分。
类结构:

Consumer 消息消费者,负责消费消息,一般是后台系统负责异步消费。一般一个应用创建一个Consumer,由应用来维护此对象,可以设置为全局对象或者单例。
consumer的start()方法主要完成以下几件事:
- checkConfig();检查consumer的groupName、Listener等是否设置。consumer的配置需在start()方法前完成。
- copySubscription();复制consumer所有的订阅。
- registerConsumer().注册consumer
- sendHeartbeatToAllBrokerWithLock()。给broker发送心跳
- rebalanceImmediately()订阅消息负载均衡。
底层还是调动netty中com.alibaba.rocketmq.remoting.netty.NettyRemotingClient#invokeAsync
或者com.alibaba.rocketmq.remoting.netty.NettyRemotingClient#invokeSync
无论是consumer还是producer中的send还是pull方法本质上都是调用netty中的invokeSync/invokeAsync进行通信。区别只是在于InvokeCallback回调对象的实现。
消费架构
consumer多余partition
partition多余consumer


消费者可靠性保证
消费者是一条接着一条地消费消息,只有在成功消费一条消息后才会接着消费下一条。如果在消费某条消息失败(如异常),则会尝试重试消费这条消 息(默认最大5次),超过最大次数后仍然无法消费,则将消息存储在消费者的本地磁盘,由后台线程继续做重试。而主线程继续往后走,消费后续的消息。因此, 只有在MessageListener确认成功消费一条消息后,meta的消费者才会继续消费另一条消息。由此来保证消息的可靠消费。消费者的另一个可靠性的关键点是offset的存储,也就是拉取数据的偏移量。默认存储在zoopkeeper上,zookeeper通过集群来保证数据的安全性。Offset会定期保存,并且在每次重新负载均衡前都会强制保存一次,因此可能会存在极端情况下的消息的重复消费。
消息过滤
消息过滤主要使用Message 的Tag字段做的。
- 在服务端,每一条消息对应的Tag被转换成一个8byte的hashcode, 在Broker 端对比Queue中每一个存储单元的的hashcode和 订阅的Tag的hashcode进行对比,不符合,则跳过,继续比对下一个,符合则传输给Consumer。在队列中进行hashcode对比
- Consumer 收到过滤后的消息后,再次将传递过来的Message中的Tag字符串和订阅的Tag字符串进行对比,不是hashcode。这样做可以避免Hash冲突
消息重复性
订阅消息阶段,由于涉及集群订阅,多个订阅方需要使用负载均衡方式订阅,在因负载均衡出现的短暂不一致的情况下可能会重复。
订阅者意外宕机,消费进度未及时存储也会产生息重复。
解决方法:
- Consumer收到消息后,通过Tair,DB去重。
- 使用Pull的方式拉取消息,但是Pull的时候,怎么协调分配队列需要应用控制。
消费时序
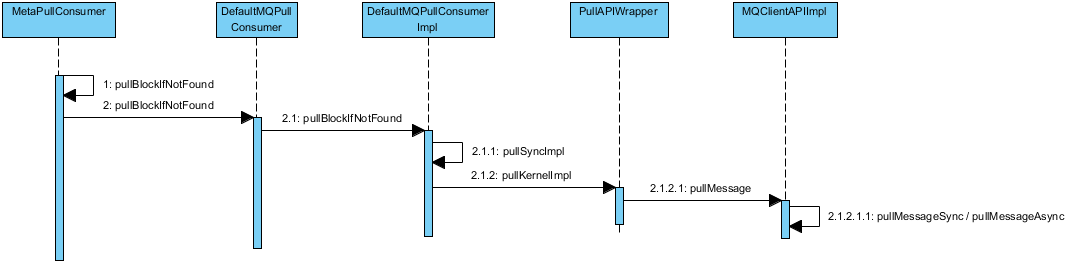
- RebalanceService根据NameServer提供的路由信息,执行负载均衡策略。每个consumer都会被尽量平均的分配相应的队列。
- 每一个consumer,RebalanceService都会针对每一个队列派发初始的pullRequest到PullMessageService维护的pullRequest阻塞队列里。
- pullMessageService每次都从pullRequestList里take一个拉消息的请求,并建立与broker的连接,每次默认从Broker获取32条消息。
- 每次pull消息成功后,会异步的调用callback回调函数,callback函数需要做的就是:第一,重新实例化一个新的的pullRequest,将其offset设置为之前已经消费的32条消息之后的offset值,将这个pullRequest重新put到pullRequest队列里。这样就形成了针对一个队列消费的闭环。第二,将之前已经能够获取到的32条消息及其他信息封装成一ConsumeRequest,并submit到ConsumeMessageService维护的ConsumeRequestQueue里。
- ConsumeMessageService 监听到ConsumeRequestQueue里有新的请求时,将会每次起一个线程执行ConsumeRequest里的run函数,这个函数主要是针对每一个消息调用之前Consumer注册的MessageListener函数。
- 顺序消费服务ConsumeMessageConcurrentlyService构建的时候,构建线程池来接收消费请求ConsumeRequest,同时构建一个单线程的本地线程,定时重新消费ConsumeRequest, 用来执行定时周期性锁队列任务
- 周期性锁队列lockMQPeriodically,获取正在消费队列列表ProcessQueueTable所有MesssageQueue,构建根据broker归类成MessageQueue集合Map<brokername,Set
>;遍历Map<brokername,Set >的brokername, 获取broker的master机器地址,将brokerName的Set 发送到broker请求锁定这些队列。在broker端锁定队列,其实就是在broker的queue中标记一下消费端,表示这个queue被某个client锁定。 Broker会返回成功锁定队列的集合,根据成功锁定的MessageQueue,设置对应的正在处理队列ProccessQueue的locked属性为true没有锁定设置为false