本文主要阐述下RPC调用过程中的寻址,序列化,以及服务端调用问题。
寻址
随机寻址
从可用列表中,随机选择地址
一致性寻址
可用服务地址一致性hash管理:根据可服务的地址,构造treemap,计算crc16 ccitt码时,加入虚拟节点数量,指向同一个可用地址。
for (String addr : list) {
for (int i = 0; i < VIRTUAL_NODE_SIZE; i++) {
ketamaMap.put(CRC16.getSlot(addr + VIRTUAL_NODE_SPLITER + i), addr);
}
}
当新加入服务时,确保之前服务的key是一致的,新加的key离散到treemap中。
调用方生成种子编码:CRC16 CCITT计算出种子。
寻址,采用treemap的tailmap(有序map的特性)。
找出比种子大的区间map,返回区间map的第一个,如果区间map为空,返回整个map的第一个。
CRC16 CCITT编码
//地址表
private static final int LOOKUP_TABLE[] = {0x0000, 0x1021, 0x2042, 0x3063,
0x4084, 0x50A5, 0x60C6, 0x70E7, 0x8108, 0x9129, 0xA14A, 0xB16B,
0xC18C, 0xD1AD, 0xE1CE, 0xF1EF, 0x1231, 0x0210, 0x3273, 0x2252,
0x52B5, 0x4294, 0x72F7, 0x62D6, 0x9339, 0x8318, 0xB37B, 0xA35A,
0xD3BD, 0xC39C, 0xF3FF, 0xE3DE, 0x2462, 0x3443, 0x0420, 0x1401,
0x64E6, 0x74C7, 0x44A4, 0x5485, 0xA56A, 0xB54B, 0x8528, 0x9509,
0xE5EE, 0xF5CF, 0xC5AC, 0xD58D, 0x3653, 0x2672, 0x1611, 0x0630,
0x76D7, 0x66F6, 0x5695, 0x46B4, 0xB75B, 0xA77A, 0x9719, 0x8738,
0xF7DF, 0xE7FE, 0xD79D, 0xC7BC, 0x48C4, 0x58E5, 0x6886, 0x78A7,
0x0840, 0x1861, 0x2802, 0x3823, 0xC9CC, 0xD9ED, 0xE98E, 0xF9AF,
0x8948, 0x9969, 0xA90A, 0xB92B, 0x5AF5, 0x4AD4, 0x7AB7, 0x6A96,
0x1A71, 0x0A50, 0x3A33, 0x2A12, 0xDBFD, 0xCBDC, 0xFBBF, 0xEB9E,
0x9B79, 0x8B58, 0xBB3B, 0xAB1A, 0x6CA6, 0x7C87, 0x4CE4, 0x5CC5,
0x2C22, 0x3C03, 0x0C60, 0x1C41, 0xEDAE, 0xFD8F, 0xCDEC, 0xDDCD,
0xAD2A, 0xBD0B, 0x8D68, 0x9D49, 0x7E97, 0x6EB6, 0x5ED5, 0x4EF4,
0x3E13, 0x2E32, 0x1E51, 0x0E70, 0xFF9F, 0xEFBE, 0xDFDD, 0xCFFC,
0xBF1B, 0xAF3A, 0x9F59, 0x8F78, 0x9188, 0x81A9, 0xB1CA, 0xA1EB,
0xD10C, 0xC12D, 0xF14E, 0xE16F, 0x1080, 0x00A1, 0x30C2, 0x20E3,
0x5004, 0x4025, 0x7046, 0x6067, 0x83B9, 0x9398, 0xA3FB, 0xB3DA,
0xC33D, 0xD31C, 0xE37F, 0xF35E, 0x02B1, 0x1290, 0x22F3, 0x32D2,
0x4235, 0x5214, 0x6277, 0x7256, 0xB5EA, 0xA5CB, 0x95A8, 0x8589,
0xF56E, 0xE54F, 0xD52C, 0xC50D, 0x34E2, 0x24C3, 0x14A0, 0x0481,
0x7466, 0x6447, 0x5424, 0x4405, 0xA7DB, 0xB7FA, 0x8799, 0x97B8,
0xE75F, 0xF77E, 0xC71D, 0xD73C, 0x26D3, 0x36F2, 0x0691, 0x16B0,
0x6657, 0x7676, 0x4615, 0x5634, 0xD94C, 0xC96D, 0xF90E, 0xE92F,
0x99C8, 0x89E9, 0xB98A, 0xA9AB, 0x5844, 0x4865, 0x7806, 0x6827,
0x18C0, 0x08E1, 0x3882, 0x28A3, 0xCB7D, 0xDB5C, 0xEB3F, 0xFB1E,
0x8BF9, 0x9BD8, 0xABBB, 0xBB9A, 0x4A75, 0x5A54, 0x6A37, 0x7A16,
0x0AF1, 0x1AD0, 0x2AB3, 0x3A92, 0xFD2E, 0xED0F, 0xDD6C, 0xCD4D,
0xBDAA, 0xAD8B, 0x9DE8, 0x8DC9, 0x7C26, 0x6C07, 0x5C64, 0x4C45,
0x3CA2, 0x2C83, 0x1CE0, 0x0CC1, 0xEF1F, 0xFF3E, 0xCF5D, 0xDF7C,
0xAF9B, 0xBFBA, 0x8FD9, 0x9FF8, 0x6E17, 0x7E36, 0x4E55, 0x5E74,
0x2E93, 0x3EB2, 0x0ED1, 0x1EF0,};
//计算CRC码
/**
* Create a CRC16 checksum from the bytes. implementation is from
* mp911de/lettuce, modified with some more optimizations
*
* @param bytes
* @return CRC16 as integer value
*/
public static int getCRC16(byte[] bytes) {
int crc = 0x0000;
for (byte b : bytes) {
crc = ((crc << 8) ^ LOOKUP_TABLE[((crc >>> 8) ^ (b & 0xFF)) & 0xFF]);
}
return crc & 0xFFFF;
}
序列化
序列化和反序列化在我们软件设计中有很多的应该场景,例如:
1、对象的持久化,以及从储存媒介还原对象。如果需要将一个对象保持到储存媒介中,我们需要先将这个对象进行序列化编码,然后将编码后的数据写入到储存媒介中。
2、进程之间的数据交互。在典型分布式服务架构中,面向服务的架构之间通常是通过RPC的方式来进行服务交互,在使用RPC的过程中,会将远程方法的参数等信息进行序列化,编码成字节序列,在网络中传输。服务方收到这个数据包后会对数据进行解码,进行反序列化。即将字节序列转换成参数对象;
3、网络中传输对象;使用分布式的缓存系统,缓存对象的获取以及对象放入缓存,都会使用序列化及反序列化;
Java序列化
1 简介
Java 对象序列化是 JDK 1.1 中引入的一组开创性特性之一,用于作为一种将 Java 对象的状态转换为字节数组,以便存储或传输的机制,以后,仍可以将字节数组转换回 Java 对象原有的状态。
实际上,序列化的思想是 “冻结” 对象状态,传输对象状态(写到磁盘、通过网络传输等等),然后 “解冻” 状态,重新获得可用的 Java 对象。所有这些事情的发生有点像是魔术,这要归功于 ObjectInputStream/ObjectOutputStream 类、完全保真的元数据以及程序员愿意用Serializable 标识接口标记他们的类,从而 “参与” 这个过程。
2 优点
使用非常方便,对象只要实现接口Serializable ,就可以被序列化;如果交互双方都是Java环境,那么使用Java自带的序列化机制还是最方便的了;
3 缺点
1、不能跨语言。Java自带的序列化,只适合Java语言使用。如果存在夸语言的应用场景,那就行不通了;
2、从序列化及反序列化的性能来看,Java自带的序列化性能是比较差的。无论是从时间,还是空间上看,性能都已经低的;
Protocol Buffers
1 简介
Protocol buffers是Google开源的一个序列化框架;是一个用来序列化结构化数据的技术,支持多种语言诸如C++、Java以及Python语言,可以使用该技术来持久化数据或者序列化成网络传输的数据。在Google 几乎所有它内部的RPC协议和文件格式都是采用PB。它具有灵活、高效、自动化的特点;相比较一些其他的XML技术而言,该技术的一个明显特点就是更加节省空间(以二进制流存储)、速度更快以及更加灵活。
通常,编写一个protocol buffers应用需要经历如下三步:
1、定义消息格式文件,最好以proto作为后缀名
2、使用Google提供的protocol buffers编译器来生成代码文件,一般为.h和.cc文件,主要是对消息格式以特定的语言方式描述
3、使用protocol buffers库提供的API来编写应用程序
2 优点
1、平台无关、语言无关
2、高性能 比XML块20-100倍
3、体积小 比XML小3-10倍
4、使用简单
5、兼容性好
3 缺点
1、使用时首先需要定义消息格式文件,然后生成代码,代码不是纯pojo,对于代码有一定的侵入性;
2、使用方便些上,不适合那种动态类型的数据。因为使用他之前必须先定义好格式文件;
XML类
1 简介
XML 序列化用处很多,包括对象持久化和数据传输。但是一些 XML 序列化技术实现起来可能很复杂。XStream 是一个轻量级的、简单易用的开放源代码 Java™ 库,用于将 Java 对象序列化为 XML 或者再转换回来;
使用 XStream 不用任何映射就能实现多数 Java 对象的序列化。在生成的 XML 中对象名变成了元素名,类中的字符串组成了 XML 中的元素内容。使用 XStream 序列化的类不需要实现 Serializable 接口。XStream 是一种序列化工具而不是数据绑定工具,就是说不能从 XML 或者 XML Schema Definition (XSD) 文件生成类。
2 优点
Xml最大的优点是可阅读性;
1、XStream 不关心序列化/反序列化的类的字段的可见性。
2、序列化/反序列化类的字段不需要 getter 和 setter 方法。
3、序列化/反序列化的类不需要有默认构造函数。
4、不需要修改类,使用 XStream 就能直接序列化/逆序列化任何第三方类。
3 缺点
1、xml序列化性能差,无论是空间还是时间,性能都不高;
JSON类
1 简介
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式。 易于人阅读和编写。同时也易于机器解析和生成。 它基于JavaScript Programming Language, Standard ECMA-262 3rd Edition - December 1999的一个子集。
JSON采用完全独立于语言的文本格式,但是也使用了类似于C语言家族的习惯(包括C, C++, C#, Java, JavaScript, Perl, Python等)。 这些特性使JSON成为理想的数据交换语言。
JSON 已经是 JavaScript 标准的一部分。目前,主流的浏览器对 JSON 支持都非常完善。应用 JSON,我们可以从 XML 的解析中摆脱出来,对那些应用 Ajax 的 Web 2.0 网站来说,JSON 确实是目前最灵活的轻量级方案
JSON非常适合Web浏览器端和服务端的数据交换;
2 优点
1、跨平台,跨语言实现;
2、轻量级,非常容易阅读与编写;
3 缺点
1、貌似除了FastJSON的性能比较好外,其他JSON库的性能不是很高;
Hessian
1 简介
Hessian是Resin的开源的,一个基于二进制的RPC服务框架。他内部有一套完善的序列化及反序列化组件,采用二进制的序列化协议。Hessian使用简单。协议性能比较高效,有各种语言的实现版本;
2 优点
1、跨平台,跨语言实现;
2、使用简单,性能相对来说,比较高效;
3 缺点
1、 各版本之间好像不太兼容。有些版本有BUG;
Avro
1 简介
Avro是Hadoop中的一个子项目,也是Apache中一个独立的项目,Avro是一个基于二进制数据传输高性能的中间件。在Hadoop的其他项目中例如HBase(Ref)和Hive(Ref)的Client端与服务端的数据传输也采用了这个工具,Avro可以做到将数据进行序列化,适用于远程或本地大批量数据交互。
在传输的过程中Avro对数据二进制序列化后 节约数据存储空间 和 网络传输带宽。做个比方:有一个100平方的房子,本来能放100件东西,现在期望借助某种手段能让原有面积的房子能存放比原来多150件以上或者更多的东西,就好比数据存放在缓存中,缓存是精贵的,需要充分的利用缓存有限的空间,存放更多的数据。再例如网络带宽的资源是有限的,希望原有的带宽范围能传输比原来高大的数据量流量,特别是针对结构化的数据传输和存储,这就是Avro存在的意义和价值。
Avro还可以做到在同一系统中支持多种不同语言,也有点类似Apache的另一个产品:Thrift(Ref),对于Thrift不同的是Avro更加具有灵活性,Avro可以支持对定义的数据结构(Schema)动态加载,利于系统扩展。
2 优点
1、跨平台,跨语言实现;
2、Avro最大的特点是序列化数据不要带字段标签,这样他序列化的后的数据非常精简,在空间上站很大的优势;
3、性能优秀;无论是空间还是时间,都比较好;
3 缺点
1、 依赖Schema文件;使用前必须定义数据的Schema格式文件,编码及解码都依赖于Schema文件
2、 各版本之间好像不太兼容。有些版本有BUG;
Apache Thrift
Apache Thrift 是 Facebook 实现的一种高效的、支持多种编程语言的远程服务调用的框架 ,同时也提供了序列化的功能;
Thrift源于大名鼎鼎的Facebook之手,在2007年facebook提交Apache基金会将Thrift作为一个开源项目,对于当时的facebook来说创造thrift是为了解决Facebook系统中各系统间大数据量的传 输通信以及系统之间语言环境不同需要跨平台的特性。所以thrift可以支持多种程序语言,例如: C++, C#, Cocoa, Erlang, Haskell, Java, Ocami, Perl, PHP, Python, Ruby, Smalltalk. 在多种不同的语言之间通信thrift可以作为二进制的高性能的通讯中间件,支持数据(对象)序列化和多种类型的RPC服务。Thrift适用于程序对程 序静态的数据交换,需要先确定好他的数据结构,他是完全静态化的,当数据结构发生变化时,必须重新编辑IDL文件,代码生成,再编译载入的流程,跟其他IDL工具相比较可以视为是Thrift的弱项,Thrift适用于搭建大型数据交换及存储的通用工具,对于大型系统中的内部数据传输相对于JSON和xml无论在性能、传输大小上有明显的优势;
Kryo
Kryo 是一个快速高效的Java对象图形序列化框架,它原生支持java,且在java的序列化上甚至优于google著名的序列化框架protobuf。
Kryo只适用于Java平台,如果只考虑Java平台,Kryo是一个不错的选择。期性能非常的好。
MessagePack
MessagePack是一个基于二进制高效的对象序列化Library用于跨语言通信。 它可以像JSON那样,在许多种语言之间交换结构对象;但是它比JSON更快速也更轻巧。 支持Python、Ruby、Java、C/C++、Javascript等众多语言。
性能比较
服务端调用
同步模型只能在调用方法中,将所有的逻辑顺序执行,如下图所示:
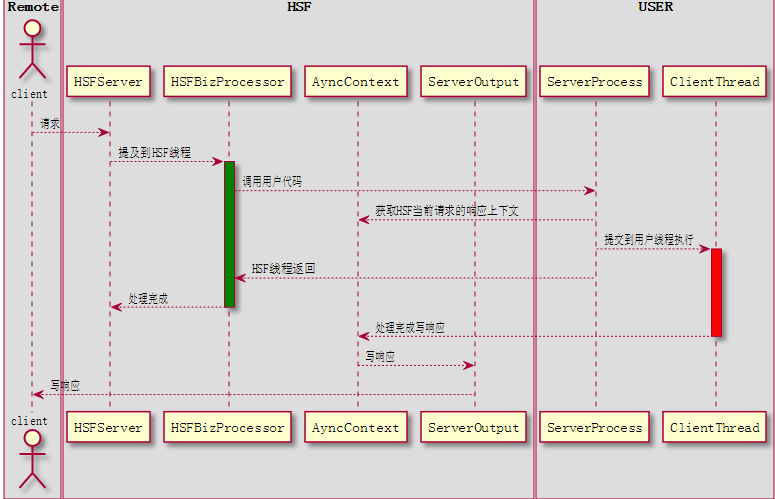
从时序图可以看出,如果用户执行逻辑比较耗时(红色部分)很容易造成HSFBizProcessor线程全部卡在这些逻辑上,造成线程池满的问题。
使用HSF服务端异步处理的方式,将耗时的部分从HSF的处理线程中移到用户的服务端,使得HSF服务端线程能够快速释放,这样可以 保证 整个机器的服务吞吐量处于较高水平,进而提升稳定性(假设耗时的方法调用频度不高)。如下图所示:
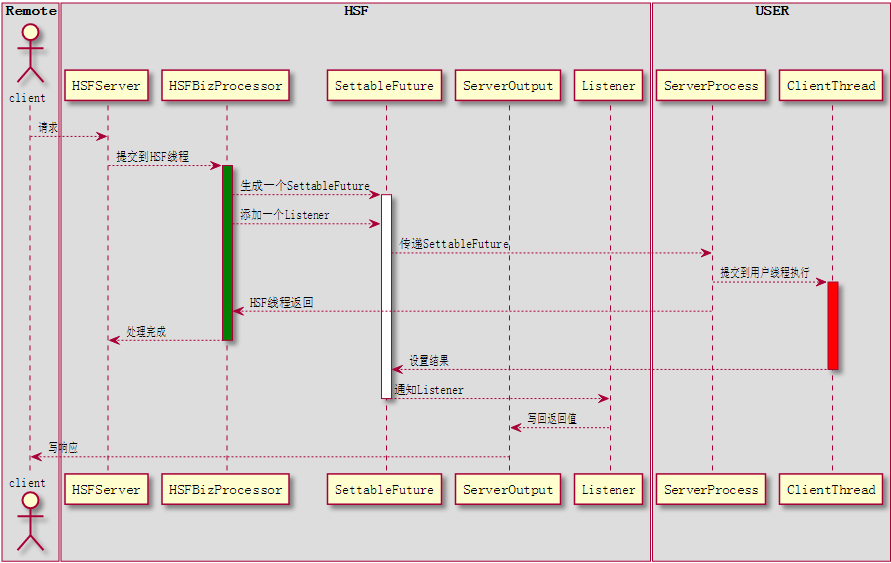
想一下之前提到的ListenableFuture,它的含义就是异步计算结束后,帮我做一些事情。我们把这个逻辑套用过来,当ClientThread完成计算之后,让框架帮忙把数据写出去,这样就解决了客户端写数据的问题了。
是不是感觉使用一个ListenableFuture作为处理的依据还是很不习惯?其实我们只需要识别三个条件因素就可以了,第一,谁负责计算(调用Future.set(Object obj)),第二,计算成功之后谁来做什么,第三,计算结果是什么。在这个例子里面,计算结果是RPCResult,负责计算的是客户端ClientThread,而计算成功之后是框架负责将数据写出。