什么是进程和线程
有一定基础的小伙伴们肯定都知道进程和线程。
进程是什么呢?
直白地讲,进程就是应用程序的启动实例。比如我们运行一个游戏,打开一个软件,就是开启了一个进程。
进程拥有代码和打开的文件资源、数据资源、独立的内存空间。
线程又是什么呢?
线程从属于进程,是程序的实际执行者。一个进程至少包含一个主线程,也可以有更多的子线程。
线程拥有自己的栈空间。

有人给出了很好的归纳:
对操作系统来说,线程是最小的执行单元,进程是最小的资源管理单元。
无论进程还是线程,都是由操作系统所管理的。
Java中线程具有五种状态:
初始化
可运行
运行中
阻塞
销毁
这五种状态的转化关系如下:

但是,线程不同状态之间的转化是谁来实现的呢?是JVM吗?
并不是。JVM需要通过操作系统内核中的TCB(Thread Control Block)模块来改变线程的状态,这一过程需要耗费一定的CPU资源。


进程和线程的痛点
线程之间是如何进行协作的呢?
最经典的例子就是生产者/消费者模式:
若干个生产者线程向队列中写入数据,若干个消费者线程从队列中消费数据。

如何用java语言实现生产者/消费者模式呢?
让我们来看一看代码:
public class ProducerConsumerTest {

}
class Producer extends Thread {

}
class Consumer extends Thread { private final QueuesharedQueue;

}
这段代码做了下面几件事:
1.定义了一个生产者类,一个消费者类。
2.生产者类循环100次,向同步队列当中插入数据。
3.消费者循环监听同步队列,当队列有数据时拉取数据。
4.如果队列满了(达到5个元素),生产者阻塞。
5.如果队列空了,消费者阻塞。
上面的代码正确地实现了生产者/消费者模式,但是却并不是一个高性能的实现。为什么性能不高呢?原因如下:
1.涉及到同步锁。
2.涉及到线程阻塞状态和可运行状态之间的切换。
3.涉及到线程上下文的切换。
以上涉及到的任何一点,都是非常耗费性能的操作。


什么是协程
协程,英文Coroutines,是一种比线程更加轻量级的存在。正如一个进程可以拥有多个线程一样,一个线程也可以拥有多个协程。

最重要的是,协程不是被操作系统内核所管理,而完全是由程序所控制(也就是在用户态执行)。
这样带来的好处就是性能得到了很大的提升,不会像线程切换那样消耗资源。
既然协程这么好,它到底是怎么来使用的呢?
由于Java的原生语法中并没有实现协程(某些开源框架实现了协程,但是很少被使用),所以我们来看一看python当中对协程的实现案例,同样以生产者消费者模式为例:

这段代码十分简单,即使没用过python的小伙伴应该也能基本看懂。
代码中创建了一个叫做consumer的协程,并且在主线程中生产数据,协程中消费数据。
其中 yield 是python当中的语法。当协程执行到yield关键字时,会暂停在那一行,等到主线程调用send方法发送了数据,协程才会接到数据继续执行。
但是,yield让协程暂停,和线程的阻塞是有本质区别的。协程的暂停完全由程序控制,线程的阻塞状态是由操作系统内核来进行切换。
因此,协程的开销远远小于线程的开销。


协程的应用
有哪些编程语言应用到了协程呢?我们举几个栗子:
Lua语言
Lua从5.0版本开始使用协程,通过扩展库coroutine来实现。
Python语言
正如刚才所写的代码示例,python可以通过 yield/send 的方式实现协程。在python 3.5以后, async/await 成为了更好的替代方案。
Go语言
Go语言对协程的实现非常强大而简洁,可以轻松创建成百上千个协程并发执行。
Java语言
如上文所说,Java语言并没有对协程的原生支持,但是某些开源框架模拟出了协程的功能,有兴趣的小伙伴可以看一看Kilim框架的源码:
https://github.com/kilim/kilim

几点补充:
1.关于协程的概念,小灰也仅仅是知道一些皮毛,希望小伙伴们多多指正。
yield与send实现协程操作
之前我们说过,在函数内部含有yield语句即称为生成器。
下面,我们来看看在函数内部含有yield语句达到的效果。首先,我们来看看以下代码:

def foo():
while True:
x = yield
print("value:",x)
g = foo() # g是一个生成器
next(g) # 程序运行到yield就停住了,等待下一个next
g.send(1) # 我们给yield发送值1,然后这个值被赋值给了x,并且打印出来,然后继续下一次循环停在yield处
g.send(2) # 同上
next(g) # 没有给x赋值,执行print语句,打印出None,继续循环停在yield处
我们都知道,程序一旦执行到yield就会停在该处,并且将其返回值进行返回。上面的例子中,我们并没有设置返回值,所有默认程序返回的是None。我们通过打印语句来查看一下第一次next的返回值:
print(next(g)) ####输出结果##### None
正如我们所说的,程序返回None。接着程序往下执行,但是并没有看到next()方法。为什么还会继续执行yield语句后面的代码呢?这是因为,send()方法具有两种功能:第一,传值,send()方法,将其携带的值传递给yield,注意,是传递给yield,而不是x,然后再将其赋值给x;第二,send()方法具有和next()方法一样的功能,也就是说,传值完毕后,会接着上次执行的结果继续执行,知道遇到yield停止。这也就为什么在调用g.send()方法后,还会打印出x的数值。有了上面的分析,我们可以很快知道,执行了send(1)后,函数被停止在了yield处,等待下一个next()的到来。程序往下执行,有遇到了send(2),其执行流程与send(1)完全一样。
有了上述的分析,我们可以总结出send()的两个功能:1.传值;2.next()。
既然send()方法有和next一样的作用,那么我们可不可以这样做:
def foo():
while True:
x = yield
print("value:",x)
g = foo()
g.send(1) #执行给yield传值,这样行不行呢?
很明显,是不行的。
TypeError: can't send non-None value to a just-started generator
错误提示:不能传递一个非空值给一个未启动的生成器。
也就是说,在一个生成器函数未启动之前,是不能传递数值进去。必须先传递一个None进去或者调用一次next(g)方法,才能进行传值操作。至于为什么要先传递一个None进去,可以看一下官方说法。

Because generator-iterators begin execution at the top of the
generator's function body, there is no yield expression to receive
a value when the generator has just been created. Therefore,
calling send() with a non-None argument is prohibited when the
generator iterator has just started, and a TypeError is raised if
this occurs (presumably due to a logic error of some kind). Thus,
before you can communicate with a coroutine you must first call
next() or send(None) to advance its execution to the first yield
expression.
问题就来,既然在给yield传值过程中,会调用next()方法,那么是不是在调用一次函数的时候,是不是每次都要给它传递一个空值?有没有什么简便方法来解决這个问题呢?答案,装饰器!!看下面代码:
def deco(func): # 装饰器:用来开启协程
def wrapper():
res = func()
next(res)
return res # 返回一个已经执行了next()方法的函数对象
return wrapper
@deco
def foo():
pass
上面我yield是没有返回值的,下面我们看看有返回值的生成器函数。
def deco(func):
def wrapper():
res = func()
next(res)
return res
return wrapper
@deco
def foo():
food_list = []
while True:
food = yield food_list #返回添加food的列表
food_list.append(food)
print("elements in foodlist are:",food)
g = foo()
print(g.send('苹果'))
print(g.send('香蕉'))
print(g.send('菠萝'))
###########输出结果为######
elements in foodlist are: 苹果
['苹果']
elements in foodlist are: 香蕉
['苹果', '香蕉']
elements in foodlist are: 菠萝
['苹果', '香蕉', '菠萝']
分析:首先,我们要清楚,在函数执行之前,已经执行了一次next()(装饰器的功能),程序停止yield。接着程序往下执行,遇到g.send(),然后将其值传递给food,然后再将获得的food添加到列表food_list中。打印出food,再次循环程序停在yield。程序继续执行,又遇到g.send(),其过程与上面是一模一样的。看看以下的程序执行流程,你可能会更清楚。
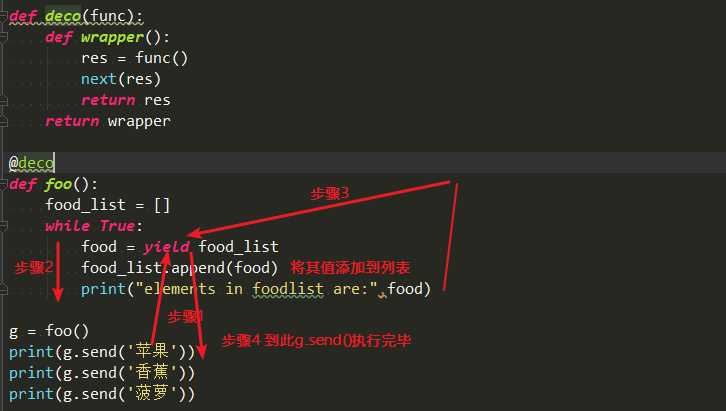
这里我们要明确一点,yield的返回值和传给yield的值是两码事!!
yiedl的返回值就相当于return的返回值,这个值是要被传递出去的,而send()传递的值,是要被yield接受,供函数内部使用的的,明确这一点很重要的。那么上面的打印,就应该打印出yield的返回值,而传递进去的值则本保存在一个列表中。
三、实例
"""模拟:grep -rl 'root' /etc"""
import os
def deco(func): # 用来开启协程
def wrapper(*args,**kwargs):
res = func(*args,**kwargs)
next(res) # res.seng(None)
return res
return wrapper
@deco
def search(target):
while True:
PATH = yield
g = os.walk(PATH) # 获取PATH目录下的文件,文件夹
for par_dir, _, files in g: #迭代解包,取出当前目录路径和文件名
for file in files:
file_path = r'%s\%s' %(par_dir,file) # 拼接文件的绝对路径
target.send(file_path) # 给下一个
@deco
def opener(target, pattern=None):
while True:
file_path = yield
with open(file_path, encoding='utf-8') as f:
target.send((file_path, f)) # 将文件路径和文件对象一起传递给下一个函数的yield,因为在打印路径时候,需要打印出文件路径,只有从这里传递下去
@deco
def cat(target):
while True:
filepath, f = yield # 这里接收opener传递进来的路径和文件对象
for line in f:
tag = target.send((filepath, line)) # 同样,也要传递文件路径,并且获取下一个函数grep的返回值,从而判断该文件是否重复读取了
if tag: # 如果为真,说明该文件读取过了,则执行退出循环
break
@deco
def grep(target, pattern):
tag = False
while True:
filepath, line = yield tag # 接受两个值,并且设置返回值,這个返回值要传递给发送消息的send(),也就是cat()函数send
tag = False
if pattern in line: # 如果待匹配字符串在该行
target.send(filepath) # 把文件路径传递给priter
tag = True # 设置tag
@deco
def printer():
while True:
filename = yield
print(filename)
调用方式:
PATH1 = r'D:CODE_FILEpython est' search(opener(cat(grep(printer(), 'root')))).send(PATH1)
输出结果:
######找出了含有'root'的所有文件####### D:CODE_FILEpython esta.txt D:CODE_FILEpython est est1c.txt D:CODE_FILEpython est est1 est2d.txt
程序分析:
有了上面的基础,我们来分析一下上述程序的执行。
每一个函数之前都有一个@deco装饰器,这个装饰器用于开启协程。首先我们定义了一个search(),其内部有关键字yield,则search()是一个生成器。也就是说,我们可以通过send()给其传递一个值进去。search()函数的功能 是:获取一个文件的绝对路径,并将這个绝对路径通过send()方法,在传递给下个含有yield的函数,也就是下面的opener函数。opener的yield接受了search()传递进来的路径,并将其赋值给了file_path,然后我们根据這个路径,打开了一个文件,获取了一个文件对象f。然后我们在将這个文件对象send()给cat()函数,這个函数功能是读取文件中的内容,我们根据逐行读取文件内容,将每次读取到的内容,在send()给下一个函数,也就是grep(),這个函数功能是实现过滤操作。我们从上一个函数cat()接受到的每一行内容,在grep()函数里面进行过滤处理,如果有匹配到的过滤内容,那么我们将就过滤到的文件传递给下一个函数print(),该函数主要是打印出文件路径。也许,上述的描述内容你没看懂,下面看看这个程序的流程图:
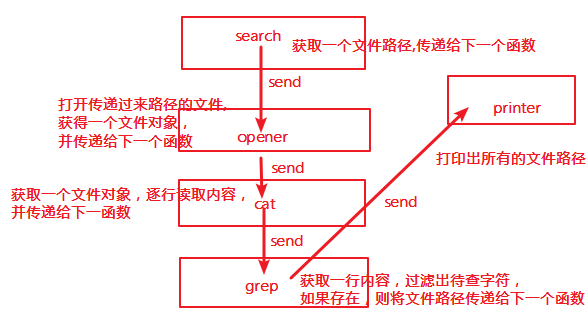
根据上述流程,我们很清楚知道,send()传递给下一个函数的值。但是上述代码存在一个问题:如果待过滤的字符在一个文件中存在多个,而在读取文件的时候,我们是一行一行地读取,然后再传递给下一个函数。我们的目的是:过滤出包好pattern的文件,如果一个文件存在多个同样的pattern,那么就会输出多次同样的文件名。这无疑是浪费内存,要解决这中问题,我们可以通过yield的返回值来控制,每次读取时候的条件。具体实施,看上述代码注释。