介绍
前面对模型的组合主要用了两种方式:
(1)一种是平均/投票;
(2)另外一种是加权平均/投票;
所以,我们有时就会陷入纠结,是平均的好,还是加权的好,那如果是加权,权重又该如何分配的好?如果我们在这些模型预测的结果上再训练一个模型对结果做预测,那么岂不是就免除了这些烦恼;而训练后,也可以方便的获取这些基分类器的权重(等价于下一层级模型的特征权重),且结果也更为客观!简单流程如下:
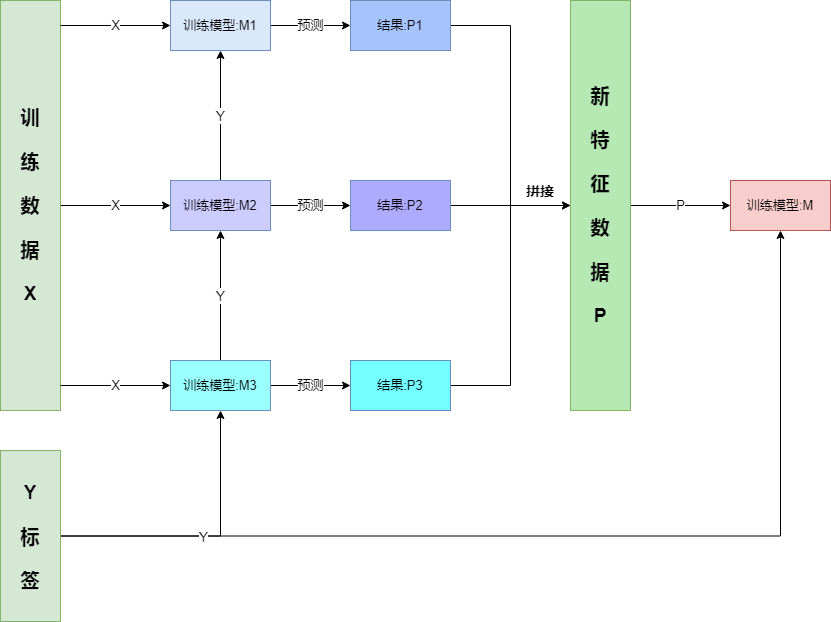
当然实际训练时回更加细致和复杂,比如:
(1)通常会对数据做(k)折切分,切分为(k)份,然后将每个基学习器扩展为(k)个基学习器,每个学习器学习(k-1)份训练数据;
(2)对分类器,预测结果通常会取概率分布,这样可以提取更多的信息;
(3)上面的结构还可以无限叠加,构建更加复杂的stacking结构,比如对新的拼接特征又训练几组基分类器,然后再组合...
stacking的代码实现,跳转>>>