一.简介
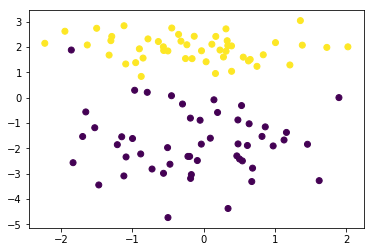
上一节介绍了硬间隔支持向量机,它可以在严格线性可分的数据集上工作的很好,但对于非严格线性可分的情况往往就表现很差了,比如:
import numpy as np
import matplotlib.pyplot as plt
import copy
import random
import os
os.chdir('../')
from ml_models import utils
from ml_models.svm import HardMarginSVM
%matplotlib inline
*** PS:请多试几次,生成含噪声点的数据***
from sklearn.datasets import make_classification
data, target = make_classification(n_samples=100, n_features=2, n_classes=2, n_informative=1, n_redundant=0,
n_repeated=0, n_clusters_per_class=1, class_sep=2.0)
plt.scatter(data[:,0],data[:,1],c=target)
<matplotlib.collections.PathCollection at 0x202a6f55a58>
#训练
svm = HardMarginSVM()
svm.fit(data, target)
utils.plot_decision_function(data, target, svm, svm.support_vectors)

那怕仅含有一个异常点,对硬间隔支持向量机的训练影响就很大,我们希望它能具有一定的包容能力,容忍哪些放错的点,但又不能容忍过度,我们可以引入变量(xi)和一个超参(C)来进行控制,原始的优化问题更新为如下:
这里(C)若越大,包容能力就越小,当取值很大时,就等价于硬间隔支持向量机,而(xi)使得支持向量的间隔可以调整,不必像硬间隔那样,严格等于1
Lagrange函数
关于原问题的Lagrange函数:
二.对偶问题
对偶问题的求解过程我就省略了,与硬间隔类似,我这里就直接写最终结果:
可以发现与硬间隔的不同是(alpha)加了一个上界的约束(C)
三.KKT条件
这里就直接写KKT条件看原优化变量与拉格朗日乘子之间的关系:
四.(w^*,b^*)的求解
由KKT条件中的关系1,我们可以知道:
对于(b^*)的求解,我们可以取某点,其(0<alpha_k^*<C),由关系3,4,5可以推得到:({w^*}^Tx_k+b^*=y_k),所以:
五.SMO求(alpha^*)
好了,最终模型得求解落到了对(alpha^*)得求解上,求解过程与硬间隔一样,无非就是就是对(alpha)多加了一个约束:(alpha_i^*<=C),具体而言需要对(alpha_2^{new})的求解进行更新:
当(y_1 eq y_2)时:
当(y_1=y_2)时:
更新公式:
六.代码实现
"""
软间隔支持向量机的smo实现,放到ml_models.svm模块中
"""
class SoftMarginSVM(object):
def __init__(self, epochs=100, C=1.0):
self.w = None
self.b = None
self.alpha = None
self.E = None
self.epochs = epochs
self.C = C
# 记录支持向量
self.support_vectors = None
def init_params(self, X, y):
"""
:param X: (n_samples,n_features)
:param y: (n_samples,) y_iin{0,1}
:return:
"""
n_samples, n_features = X.shape
self.w = np.zeros(n_features)
self.b = .0
self.alpha = np.zeros(n_samples)
self.E = np.zeros(n_samples)
# 初始化E
for i in range(0, n_samples):
self.E[i] = np.dot(self.w, X[i, :]) + self.b - y[i]
def _select_j(self, best_i):
"""
选择j
:param best_i:
:return:
"""
valid_j_list = [i for i in range(0, len(self.alpha)) if self.alpha[i] > 0 and i != best_i]
best_j = -1
# 优先选择使得|E_i-E_j|最大的j
if len(valid_j_list) > 0:
max_e = 0
for j in valid_j_list:
current_e = np.abs(self.E[best_i] - self.E[j])
if current_e > max_e:
best_j = j
max_e = current_e
else:
# 随机选择
l = list(range(len(self.alpha)))
seq = l[: best_i] + l[best_i + 1:]
best_j = random.choice(seq)
return best_j
def _meet_kkt(self, w, b, x_i, y_i, alpha_i):
"""
判断是否满足KKT条件
:param w:
:param b:
:param x_i:
:param y_i:
:return:
"""
if alpha_i < self.C:
return y_i * (np.dot(w, x_i) + b) >= 1
else:
return y_i * (np.dot(w, x_i) + b) <= 1
def fit(self, X, y2, show_train_process=False):
"""
:param X:
:param y2:
:param show_train_process: 显示训练过程
:return:
"""
y = copy.deepcopy(y2)
y[y == 0] = -1
# 初始化参数
self.init_params(X, y)
for _ in range(0, self.epochs):
if_all_match_kkt = True
for i in range(0, len(self.alpha)):
x_i = X[i, :]
y_i = y[i]
alpha_i_old = self.alpha[i]
E_i_old = self.E[i]
# 外层循环:选择违反KKT条件的点i
if not self._meet_kkt(self.w, self.b, x_i, y_i, alpha_i_old):
if_all_match_kkt = False
# 内层循环,选择使|Ei-Ej|最大的点j
best_j = self._select_j(i)
alpha_j_old = self.alpha[best_j]
x_j = X[best_j, :]
y_j = y[best_j]
E_j_old = self.E[best_j]
# 进行更新
# 1.首先获取无裁剪的最优alpha_2
eta = np.dot(x_i - x_j, x_i - x_j)
# 如果x_i和x_j很接近,则跳过
if eta < 1e-3:
continue
alpha_j_unc = alpha_j_old + y_j * (E_i_old - E_j_old) / eta
# 2.裁剪并得到new alpha_2
if y_i == y_j:
L = max(0., alpha_i_old + alpha_j_old - self.C)
H = min(self.C, alpha_i_old + alpha_j_old)
else:
L = max(0, alpha_j_old - alpha_i_old)
H = min(self.C, self.C + alpha_j_old - alpha_i_old)
if alpha_j_unc < L:
alpha_j_new = L
elif alpha_j_unc > H:
alpha_j_new = H
else:
alpha_j_new = alpha_j_unc
# 如果变化不够大则跳过
if np.abs(alpha_j_new - alpha_j_old) < 1e-5:
continue
# 3.得到alpha_1_new
alpha_i_new = alpha_i_old + y_i * y_j * (alpha_j_old - alpha_j_new)
# 4.更新w
self.w = self.w + (alpha_i_new - alpha_i_old) * y_i * x_i + (alpha_j_new - alpha_j_old) * y_j * x_j
# 5.更新alpha_1,alpha_2
self.alpha[i] = alpha_i_new
self.alpha[best_j] = alpha_j_new
# 6.更新b
b_i_new = y_i - np.dot(self.w, x_i)
b_j_new = y_j - np.dot(self.w, x_j)
if self.C > alpha_i_new > 0:
self.b = b_i_new
elif self.C > alpha_j_new > 0:
self.b = b_j_new
else:
self.b = (b_i_new + b_j_new) / 2.0
# 7.更新E
for k in range(0, len(self.E)):
self.E[k] = np.dot(self.w, X[k, :]) + self.b - y[k]
# 显示训练过程
if show_train_process is True:
utils.plot_decision_function(X, y2, self, [i, best_j])
utils.plt.pause(0.1)
utils.plt.clf()
# 如果所有的点都满足KKT条件,则中止
if if_all_match_kkt is True:
break
# 计算支持向量
self.support_vectors = np.where(self.alpha > 1e-3)[0]
# 显示最终结果
if show_train_process is True:
utils.plot_decision_function(X, y2, self, self.support_vectors)
utils.plt.show()
def get_params(self):
"""
输出原始的系数
:return: w
"""
return self.w, self.b
def predict_proba(self, x):
"""
:param x:ndarray格式数据: m x n
:return: m x 1
"""
return utils.sigmoid(x.dot(self.w) + self.b)
def predict(self, x):
"""
:param x:ndarray格式数据: m x n
:return: m x 1
"""
proba = self.predict_proba(x)
return (proba >= 0.5).astype(int)
svm = SoftMarginSVM(C=3.0)
svm.fit(data, target)
utils.plot_decision_function(data, target, svm, svm.support_vectors)
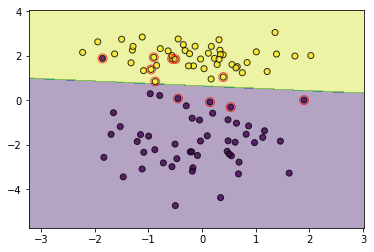
通过控制C可以调节宽容度,设置一个大的C可以取得和硬间隔一样的效果
svm = SoftMarginSVM(C=1000000)
svm.fit(data, target)
utils.plot_decision_function(data, target, svm, svm.support_vectors)
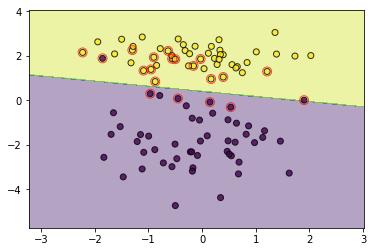
有时,太过宽容也不一定好
svm = SoftMarginSVM(C=0.01)
svm.fit(data, target)
utils.plot_decision_function(data, target, svm, svm.support_vectors)
七.支持向量
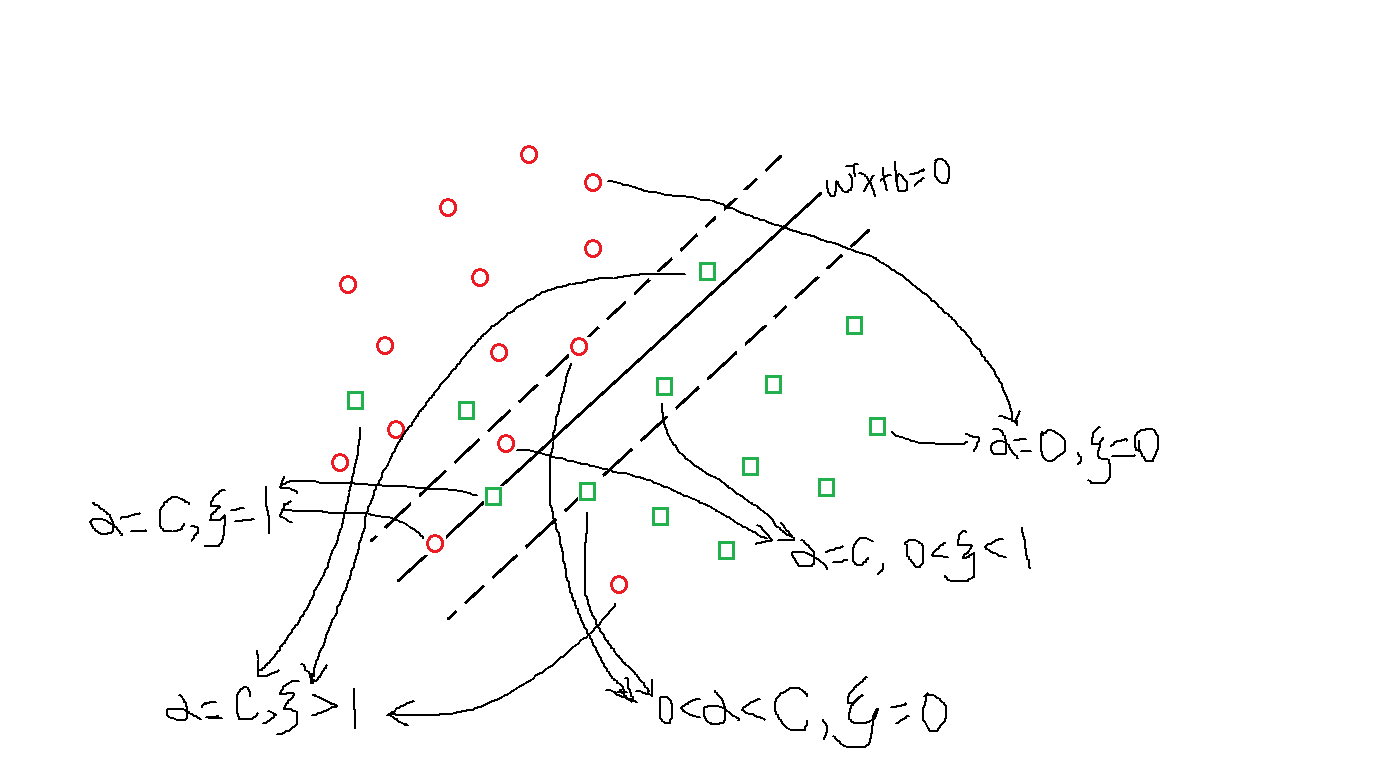
软间隔支持向量机的支持向量复杂一些,因为对于(alpha>0)有许多种情况,如下图所示,大概可以分为4类:
(1)(0<alpha_i<C,xi_i=0):位于间隔边界上;
(2)(alpha_i=C,0<xi_i<1):分类正确,位于间隔边界与分离超平面之间;
(3)(alpha_i=C,xi_i=1):位于分离超平面上;
(4)(alpha_i=C,xi_i>1):位于错误分类的一侧