起因是我们的集群应用(3台机器)新版本测试过程中,一般的JVM内存占用 都在1G左右, 但在运行了一段时间后,慢慢升到了4G, 这是一个明显不正常的现象。
定位 过程:
1.先在该机器上按照步骤尝试重现现场,当发生问题后打开一台机器上JDK的jvisualvm观察JVM内存占用情况,这时明显看到GC很密集,锯齿线很密,几乎压在一起。之后随着时间增加,
Heap曲线缓步上升。 这时怀疑是哪里的代码出现了死循环, 产生了大量的垃圾对象频繁被GC。
JVM启动的主要参数为-Xms1024M -Xmx1096M -XX:MaxPermSize=512M -Xmn512M -Xss512k -XX:+UseParallelGC

这里能看到频繁GC后heap直线上升,接近分配的heap上限。

2.这时尝试dump了heap和thread:
jps查看pid
jmap -dump:format=b,file=HeapDump.hprof pid
jstack pid > threaddump.txt
用TDA打开thread dump试图分析有无一些死锁资源竞争问题,并没有看到有死锁的报告,但看到一个可疑的大部分操作都在等待monitor的问题。

看了下大部分sleep thread都卡在java.util.Vector上,应该是某些IO操作导致的底层问题。
"TheadPool:AuditLookup:Waiting" prio=6 tid=0x0000000008e8c800 nid=0x968 in Object.wait() [0x000000000e45f000] java.lang.Thread.State: TIMED_WAITING (on object monitor) at java.lang.Object.wait(Native Method) - waiting on <0x00000000c20d42d0> (a java.util.Vector) at com.***.util.BlockingQueue.remove(BlockingQueue.java:114) - locked <0x00000000c20d42d0> (a java.util.Vector) at com.***.util.ThreadPool$PooledThread.run(ThreadPool.java:184) Locked ownable synchronizers: - None
3.拿到hprof后,用IBM贡献的开源工具Eclipse Memory Analyzer,打开Leak report看一下overview

从这里大概可以看见占用比较多的是byte[], 占了75%, 下面看一下details的信息。
4.下面显示的是向内存聚集点的一个common path,这里能找到的信息就比较多了,可以看到是这个Message有关的service引起的,这个service调用了
序列化流ObjectInputStream, 然后在它的HandleTable中保存了大量的二进制byte数组。截图去掉了一些包名。

由于是这个Message的服务调用了下层JDK的ObjectInputStream,怀疑是这里出了什么问题。看了一下有关的介绍和ObjectInputStream内部HandleTable的代码,
HandleTable是用来接收流的。一些主要的代码片段如下
HttpURLConnection huc= ( HttpURLConnection )new URL( url).openConnection(); ObjectInputStream ois = new ObjectInputStream( huc.getInputStream() ); ois.readUTF(); ois.readObject();
很简单,就是打开输入流,读入string与对象,没什么特别的, 这样的东西也会有什么问题?继续查,看到一些文章说ObjectInputStream会有memory leak的风险,分析了下
似乎这里并不是问题的起点,ObjectInputStream只有被滥用时才有可能。 这样回到业务代码上继续看,因为有三台机连在一起时才会这样, 2台机就不会, 所以继续查log,
用command line的方式启动应用, 发现时send message的方法在刷屏, 两台机不停的在互发, 这时观察一下系统的网络占用:

可以看到该机器A 网络从一个较低的send <100Kbps的速率直线上升到1.1Mbps, 是个很明显的广播风暴, 另一台机B也是这样, 第三台机C并没有什么明显的网络
波动。
看来明显是消息的分发逻辑出了问题,这里简单介绍一下目前的消息分发逻辑,不然就无法解释怎么解决的了。消息分发是被改动过的了,之前的逻辑是这样:
集群中有一个主机(A),其它都是分机(B,C),当 有消息从分机(B)中发出时,A会判断消息类型,如果是广播型则向A中保存的所有分机列表进行广播(步骤2,3)
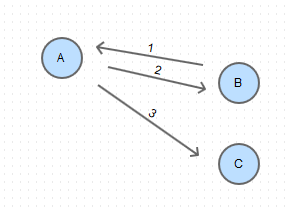
这个过程中B会判断消息来源是否是自己,反正重复循环发。C如果想向B发消息,只能先向主机A发,由A来转发给B。
而这个逻辑被这次升级改动打破了,这个封闭的消息组加入了一个新的消息主机,这个主机会有自己对应的几个分机,组成了另一个消息分发环,而发消息的时候并没有考虑这个新的主机,图如下:

当B向A发消息后,主机A的设计就是想其所有分机(B,C,D)分发消息,所以另一组消息主机D也被认为是A的分机,B的消息被传播到D,D接到后检查自己的分机(E,F,A),
向A又回发了这个消息(步骤3),这时A与D之间就会不停地互相转发源头是B的消息,造成了大量的消息对象产生及销毁,内存波动及网络拥堵。
根据逻辑改动过两个消息主机A,D的分发机制后,问题解决, 内存GC回归正常, 网络流量也回落了。
