想实现一个自动下载微信公众号分享百度网盘图片链接的爬虫,使用selenium和火狐的webdriver进行完成
1.首先根据自己的浏览器下载相应的webdriver驱动器,python中导入selenium包。webdriver下载好后,放在浏览器的默认安装地址中,
然后再在自己的python默认安装地址中也加入一份webdriver,并且添加环境变量path,加入浏览器的安装地址,即:webdriver放置的目录
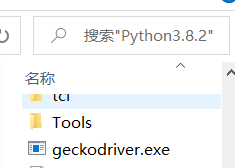
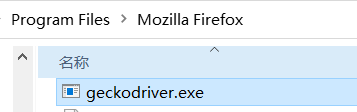

2.获取自己浏览器的默认配置,也可以不用,即去掉
propath = r"C:Users用户名AppDataRoamingMozillaFirefoxProfiles�5dg6q1p.default"
profile = webdriver.FirefoxProfile(propath)#使用自己浏览器的配置,我的是火狐浏览器
,其实不影响什么。获取的话根据写的路径自己找
3.获取自己百度网盘的cookie,先在浏览器上登录,然后点击检查
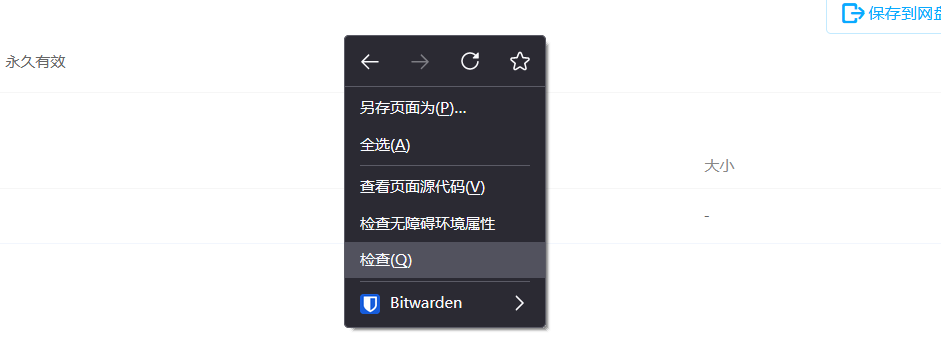
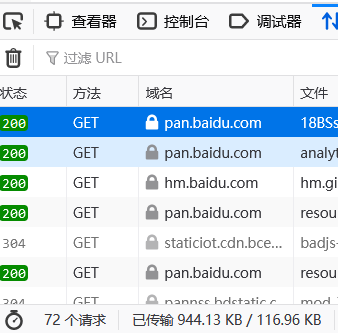
找到网络点击第一条发出的请求

找到cookie中的名字是BDUSS,复制替换源代码的值

4.替换百度网盘的连接,和提取码后就大体完成了
5.可以自己编写从文件读取多条百度网盘链接的函数,在调用本源代码。此方法仅是适用一条百度链接
源代码
from selenium import webdriver from selenium.webdriver.common.keys import Keys import time propath = r"C:Users用户名AppDataRoamingMozillaFirefoxProfiles�5dg6q1p.default" profile = webdriver.FirefoxProfile(propath)#使用自己浏览器的配置,我的是火狐浏览器 #使用自己百度网盘的cookie cookie1 = {'value': '自己百度网盘的cookie', 'name': 'BDUSS'} driver = webdriver.Firefox()#括号参数:executable_path="driver路径",可配置浏览器驱动的目录加入了环境变量,就不用括号里的参数了 #https://pan.baidu.com/s/18BSsXsCKUfpEumKUMT8mTA # 提取码:bhnd 测试 link="https://pan.baidu.com/s/18BSsXsCKUfpEumKUMT8mTA" num="bhnd" driver.get(link)#先建立链接 driver.add_cookie(cookie_dict=cookie1)#添加cookie进行登录 elem = driver.find_element_by_id("accessCode") elem.send_keys(num) elem.send_keys(Keys.RETURN)#输入回车 time.sleep(10)#等待到完全加载后再找元素 nowurl=driver.current_url # # sreach_window = driver.current_window_handle #全选 driver.find_element_by_xpath("/html/body/div[1]/div[2]/div[1]/div/div[2]/div[2]/div[2]/div/ul[1]/li[1]/div/span[1]").click() time.sleep(2) #点击下载 # driver.find_element_by_xpath("/html/body/div[1]/div[2]/div[1]/div/div[1]/div/div[2]/div/div/div[2]/a[2]/span/span").click()#自己决定是下载还是保存,下载可能会出现输入校验码的情况,无法解决 #点击保存 driver.find_element_by_xpath("/html/body/div[1]/div[2]/div[1]/div/div[1]/div/div[2]/div/div/div[2]/a[1]").click() time.sleep(2) driver.find_element_by_xpath("/html/body/div[3]/div[3]/a[2]/span/span").click()#找到确认按钮点击
如果对你有帮助的话不妨点个赞,欢迎在评论区留言