- 协程
- 基于单线程(只用一个主线程)来实现并发
- 切换+保存状态
- 协程是一种用户态的轻量级线程,即协程是由用户程序自己控制调度的
- 协程的切换开销更小,属于程序级别的切换,操作系统完全感知不到,因而更加轻量级
- 单线程内就可以实现并发的效果,最大限度地利用cpu
- 协程的本质是单线程下,无法利用多核,可以是一个程序开启多个进程,每个进程内开启多个线程,每个线程内开启协程
- 协程指的是单个线程,因而一旦协程出现阻塞,将会阻塞整个线程
- 修改共享数据不需加锁
- 可以控制多个任务之间的切换,切换之前将任务的状态保存下来,以便重新运行时,可以基于暂停的位置继续执行
- 作为1的补充:可以检测io操作,在遇到io操作的情况下才发生切换
- yield
- yiled可以保存状态
- send可以把一个函数的结果传给另外一个函数,以此实现单线程内程序之间的切换
- yield并不能实现遇到io切换
- 需要先得到初始化一次的生成器,然后再调用send
def consumer(): '''任务1:接收数据,处理数据''' while True: x=yield def producer(): '''任务2:生产数据''' g=consumer() next(g) for i in range(10000000): g.send(i) [time.sleep(2)]
- Greenlet
- 只是提供了一种比generator更加便捷的切换方式
- g1=greenlet(eat)
- g2=greenlet(play)
- g1.switch('egon')
- 切到一个任务执行时如果遇到io,那就原地阻塞
- 没有解决遇到IO自动切换来提升效率的问题
 View Code
View Codefrom greenlet import greenlet import time def f1(): res=1 for i in range(100000000): res+=i g2.switch() def f2(): res=1 for i in range(100000000): res*=i g1.switch() start=time.time() g1=greenlet(f1) g2=greenlet(f2) g1.switch() stop=time.time()
- 只是提供了一种比generator更加便捷的切换方式
- Gevent
- 实现并发同步或异步编程
- 遇到IO阻塞时会自动切换任务
- gevent是不能直接识别,需要打补丁。要用gevent,需要将from gevent import monkey;monkey.patch_all()放到文件的开头
# pip install gevent from gevent import monkey;monkey.patch_all() from socket import * import gevent #如果不想用money.patch_all()打补丁,可以用gevent自带的socket # from gevent import socket # s=socket.socket() def server(server_ip,port): s=socket(AF_INET,SOCK_STREAM) s.setsockopt(SOL_SOCKET,SO_REUSEADDR,1) s.bind((server_ip,port)) s.listen(5) while True: conn,addr=s.accept() gevent.spawn(talk,conn,addr) def talk(conn,addr): try: while True: res=conn.recv(1024) print('client %s:%s msg: %s' %(addr[0],addr[1],res)) conn.send(res.upper()) except Exception as e: print(e) finally: conn.close() if __name__ == '__main__': server('127.0.0.1',8080)
- 基于单线程(只用一个主线程)来实现并发
- IO模型
- 理论介绍
- 同步(synchronous) IO和异步(asynchronous) IO
- 阻塞(blocking) IO和非阻塞(non-blocking)IO
- 表现情况
- 输入操作
- read、readv、recv、recvfrom、recvmsg
- 阻塞状态,则会经历wait data和copy data两个阶段
- 设置为非阻塞则在wait 不到data时抛出异常
- 输出操作
- write、writev、send、sendto、sendmsg
- 在发送缓冲区满了会阻塞在原地
- 设置为非阻塞,则会抛出异常
- 接收外来连接
- accept,与输入操作类似
- 发起外出连接
- connect,与输出操作类似
- 输入操作
- Linux环境下的network IO
- 调用这个IO的process
- 系统内核(kernel)
- 等待数据准备
- 将数据从内核拷贝到进程中
- 模型分类
- 阻塞IO blocking
- linux中,默认情况下所有的socket都是blocking。几乎所有的IO接口 ( 包括socket接口 ) 都是阻塞型的
- 特点就是在IO执行的两个阶段(等待数据和拷贝数据两个阶段)都被block了
- 解决方案是:在服务器端使用多线程(或多进程)
- 让每个连接都拥有独立的线程(或进程),任何一个连接的阻塞都不会影响其他的连接
- 严重占据系统资源,降低系统对外界响应效率,其本身也更容易进入假死状态
- 线程池或连接池
- 减少创建和销毁线程的频率,其维持一定合理数量的线程,让空闲的线程重新承担新的执行任务
- 多线程模型可以方便高效的解决小规模的服务请求,但面对大规模的服务请求,多线程模型也会遇到瓶颈
- 让每个连接都拥有独立的线程(或进程),任何一个连接的阻塞都不会影响其他的连接

-
当用户进程调用recvfrom这个系统调用,kernel就开始IO的第一个阶段:准备数据。对network io来说,很多时候数据在一开始还没到达(比如,还未收到一个完整UDP包),这时kernel就要等足够的数据到来。
-
而在用户进程这边,整个进程会被阻塞。当kernel一直等到数据准备好了,它就会将数据从kernel中拷贝到用户内存,然后kernel返回结果,用户进程才解除block的状态,重新运行起来。
- 非阻塞IO nonblocking
- 用户进程其实是需要不断的主动询问kernel数据准备好了没有
- 能够在等待任务完成的时间里干其他任务,循环调用recv()将大幅度推高CPU占用率
- 任务完成的响应延迟增大了:每过一段时间才去轮询一次read操作,而任务可能在两次轮询之间的任意时间完成,导致整体数据吞吐量的降低
- 非阻塞IO模型绝不被推荐
- recv()更多的是起到检测“操作是否完成”的作用
- 操作系统提供了更为高效的检测接口
- recv()更多的是起到检测“操作是否完成”的作用
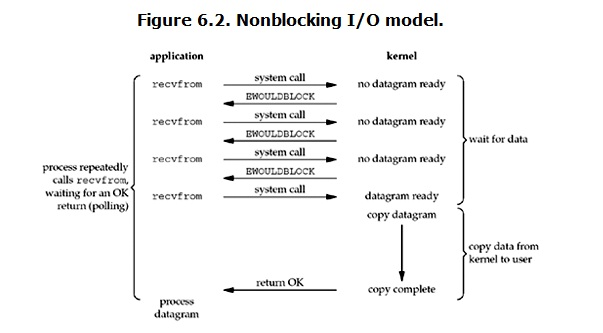
-
当用户进程发出read操作时,如果kernel中的数据还没有准备好,那么它并不会block用户进程,而是立刻返回一个error。从用户进程角度讲 ,它发起一个read操作后,并不需要等待,而是马上就得到了一个结果。用户进程判断结果是一个error时,它就知道数据还没有准备好,于是用户就可以在本次到下次再发起read询问的时间间隔内做其他事情,或者直接再次发送read操作。一旦kernel中的数据准备好了,并且又再次收到了用户进程的system call,那么它马上就将数据拷贝到了用户内存(这一阶段仍然是阻塞的),然后返回。
-
也就是说非阻塞的recvform系统调用调用之后,进程并没有被阻塞,内核马上返回给进程,如果数据还没准备好,此时会返回一个error。进程在返回之后,可以干点别的事情,然后再发起recvform系统调用。重复上面的过程,循环往复的进行recvform系统调用。这个过程通常被称之为轮询。轮询检查内核数据,直到数据准备好,再拷贝数据到进程,进行数据处理。需要注意,拷贝数据整个过程,进程仍然是属于阻塞的状态
- 多路复用IO multiplexing
- 事件驱动IO(event driven IO) select/epoll。单个process就可以同时处理多个网络连接的IO
- 基本原理就是select/epoll这个function会不断的轮询所负责的所有socket
- 当某个socket有数据到达了,就通知用户进程
- 连接数少,使用select/epoll的web server不一定比使用multi-threading + blocking IO的web server性能更好,可能延迟还更大
- select/epoll的优势并不是对于单个连接能处理得更快,而是在于能处理更多的连接
- 在多路复用模型中,对于每一个socket,一般都设置成为non-blocking 。
- process是被select这个函数block,而不是被socket IO给block
- select的优势在于可以处理多个连接,不适用于单个连接
- 只用单线程(进程)执行,占用资源少,不消耗太多 CPU; 同时能够为多客户端提供服务
- 需要探测的句柄值较大时,select()接口本身需要消耗大量时间去轮询各个句柄
- 实现更高效的服务器程序:epoll
- 跨平台:不同的操作系统特供的epoll接口有很大差异
- 该模型将事件探测和事件响应夹杂在一起,一旦事件响应的执行体庞大,则对整个模型是灾难性的
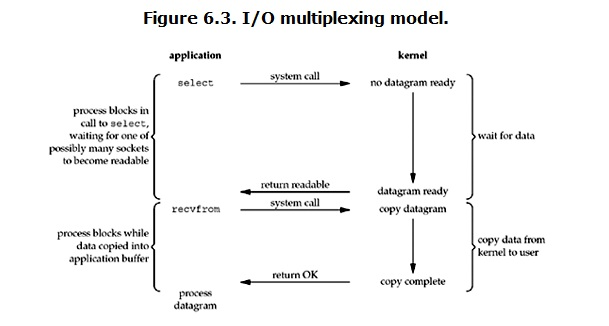
-
当用户进程调用了select,那么整个进程会被block,而同时,kernel会“监视”所有select负责的socket,当任何一个socket中的数据准备好了,select就会返回。这个时候用户进程再调用read操作,将数据从kernel拷贝到用户进程。
-
这个图和blocking IO的图其实并没有太大的不同,事实上还更差一些。因为这里需要使用两个系统调用(select和recvfrom),而blocking IO只调用了一个系统调用(recvfrom)。但是,用select的优势在于它可以同时处理多个connection。
- 事件驱动IO(event driven IO) select/epoll。单个process就可以同时处理多个网络连接的IO
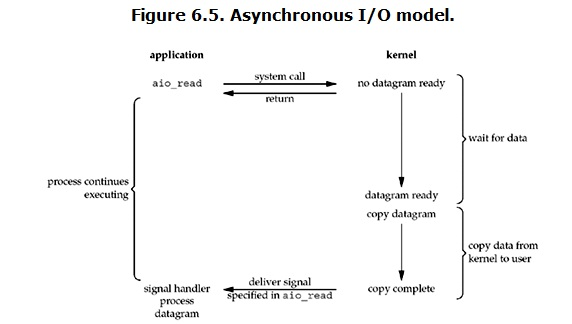
- 异步IO asynchronous
- 用户进程发起read操作之后,立刻就可以开始去做其它的事
- 从kernel的角度,当它受到一个asynchronous read之后,首先它会立刻返回,所以不会对用户进程产生任何block
- 然后,kernel会等待数据准备完成,然后将数据拷贝到用户内存
- 当这一切都完成之后,kernel会给用户进程发送一个signal,告诉它read操作完成了
- 阻塞IO blocking
- 模型比较
- blocking和non-blocking
- blocking IO会一直block住对应的进程直到操作完成
- non-blocking IO在kernel还准备数据的情况下会立刻返回
- synchronous IO和asynchronous IO :blocking IO,non-blocking IO,IO multiplexing都属于synchronous IO

-
在non-blocking IO中,虽然进程大部分时间都不会被block,但是它仍然要求进程去主动的check,并且当数据准备完成以后,也需要进程主动的再次调用recvfrom来将数据拷贝到用户内存
-
而asynchronous IO则完全不同。它就像是用户进程将整个IO操作交给了他人(kernel)完成,然后他人做完后发信号通知。在此期间,用户进程不需要去检查IO操作的状态,也不需要主动的去拷贝数据。
- blocking和non-blocking
- selectors
- 共用某个介质来尽可能多的做同一类(性质)的事,一个进程可以同时对多个客户请求进行服务
- IO复用的介质是进程(select和poll),复用一个进程(select和poll)来对多个IO进行服务
- 本质是同步IO
- 利用一个函数(select和poll)来监听IO所需的客户端并发发来的数据的准备状态
- 一旦IO有数据可以进行读写了,进程就来对这样的IO进行服务
-
select:int select(int nfds, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);
-
poll:int poll(struct pollfd *fds, nfds_t nfds, int timeout);
-
epoll:int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout);#windows下不支持
- 理论介绍
