from:why
很多很多part……
1.pair:
相当于把两个变量放在一起:
#include<utility> using namespace std; pair<TypeName1,TypeName2> VariableName; pair<int,int> x; pair<double,double> y; pair<int,double> z; pair< pair<int,int> ,int> a;
优点:好写
作为需要返回多个量的函数返回值
作为struct的代替:
默认按照第一元素来进行比较排序
Pair 的比较大小:先比较第一个元素,第一个元素相同时再比较第二个元素。
如果两个元素都相等则判定相等。
2.string:
#include<string> using namespace std; string a;//现在是空串
a = b, a = ``Hello World'':支持赋值
a[i];:支持下标访问
a.size():字符串长度
a+b:支持字符串拼接
a:qingbei b:xuetang
a+b=qingbeixuetang
a>b:支持按字典序排序
a.substr(x,y):从x位置开始,长度为y的子串 返回左闭右开???
3.vector:
problem 1:
有编号为 1 到 3000 × 3000 的人,每个人都属于一个队伍。一共有3000 个队伍,每个队伍 3000 人。如何存储这些数据?
显然用数组储存就好了qwq:
const int maxN = 3000; int team[maxN][maxN];
problem 2:
有编号为 1 到 3000 × 3000 的人,每个人都属于一个队伍。一共有3000 个队伍,每个队伍可能有任意多数人,也可能没有人。如何存储这些数据?
这个时候显然用数组存的话有点浪费,毕竟我们不能确定每队有多少人。这个时候,something amazing就出现了:
vector:
不定长数组:不需要指定数组元素的数量,可以直接通过元素
的个数分配内存
#include <vector> using namespace std; vector<TypeName> VariableName; vector<int> a; vector<double> b; vector<vector<int> > c;
内存分配:内存(也就相当于数组的大小)总是2n,加入操作时先开一个空间,接着开2个,然后开成4个……接着8个;
a[0]: 随机下标访问, O(1).
a.push_back(): 在末尾插入一个元素, O(1).
a.pop_back(): 弹出末尾元, O(1).
a.front(): 访问第一个元素(引用) , O(1).
a.back(): 访问最后一个元素, O(1).
a.clear(): 清空一个 Vector, O(n).
a.empty(): 返回 Vector 是否为空, O(1).
a.size(): 返回 Vector 中元素的个数, O(1)
eg:
接受n个整数的输入,倒序输出;
#include <iostream> using namespace std; int main() { vector<int> a; int n, x; cin >> n; for (int i = 0; i < n; ++i) { cin >> x; a.push_back(x); } while (!a.empty()) { cout << a.back(); a.pop_back(); } return 0; }
vector实现比数组慢(开o2的话和数组的实现速度差不多,不开o2可能会炸)
Vector迭代器:(vector的内存是连续的)
vector<int>::iterator it;
迭代器 (iterator) 的作用类似于指针,是一个指明元素位置的量。什么类型的 Vector就要用什么类型的迭代器。
a.begin(): 返回第一个元素的迭代器
a.end(): 返回最后一个元素的后一个迭代器
*a.begin(): 等价于 a.front()
*it: 得到 it 指向的值
it++: 得到下一个位置的迭代器it += i: 得到下 i 个位置的迭代器, O(1)
it1 - it2: 得到 it1 与 it2 之间的元素个数, O(1)
vector<int>::iterator it; for (it = a.begin(); it != a.end(); ++it) { cout << *it << endl; }
相当于指针(返回的是位置)
加*是返回指针的值
支持自增运算,可以得到下一个位置的迭代器
一些神奇的东西(c++11中才有,c++98没有):anto

遍历a的每一个anto类型x:这个anto的类型是系统自己判断的
4.set
set是一个集合
集合:不能有重复元素+有序的(数学:我没要求有序啊)
具有鲁棒性:
举个栗子:

删除的如果是一个不存在的数也不会报错
#include<set> using namespace std; set<TypeName> VariableName; set<int> a; set<double> b;
操作:
a.clear(): 清空元素
a.empty(): 检查是否为空
a.size(): 查看 set 内元素个数
a.begin(): 第一个元素的迭代器
a.end(): 最后一个元素的后一个迭代器
a.insert(): 插入一个元素, O(log n)
a.erase(): 删除一个元素, O(log n)
a.find(): 寻找一个元素, O(log n)
a.count(): 查找某个元素的数量, O(log n)
a.lower_bound(): 查找大于等于某个值的第一个元素, O(log n)
a.upper_bound(): 查找大于某个值的第一个元素, O(log n)
a.equal_range(): 查找等于某个值的左闭右开区间,返回一个pair, O(log n)

#include <set> #include <iostream> using namespace std; int main() { set<int> a; a.insert(1); // a: {1} a.insert(1); // a: {1} a.insert(2); // a: {1, 2} a.erase(1); // a: {2} for (int i = 0; i < 5; ++i) { a.insert(i); } // a: {0, 1, 2, 3, 4} cout << a.size() << endl; // 5 cout << a.count(4) << endl; // 1 }
set的迭代器:
Set 的迭代器和 Vector 的不同。(set的储存是无序的)
set<int>::iterator it;
*it: it 的求值
++it: it 的下一个迭代器
--it: it 的前一个迭代器
不能跳着访问第n个迭代器,只能向前或向后访问一个迭代器
Vector: 随机访问迭代器(可以访问任意迭代器)
Set: 双向迭代器(只能向前或向后访问一个迭代器)
寻找:返回的是迭代器,如果没有返回a.end()
不能一次访问某个迭代器后的n个(因为它的内存不是连续的)
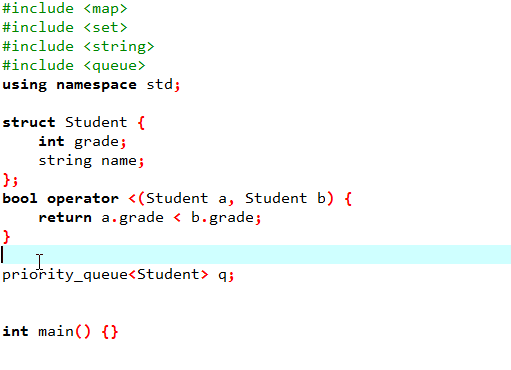
我也不知道这是写来干嘛的,总之是一个按照成绩排名的简单的神奇的东西:
可以这么写(利用重载运算符把成绩小的放在前面):

还可以这样写(把重载作为成员函数):

little 拓展:
替罪羊:打平(保证前序遍历不变,重新建一棵平衡的树)
(问题在于怎么设计?设计什么?)
Splay,treap
5.MultiSet:
和set差不多,只不过MultiSet允许存在重复的元素:
#include <set> using namespace std; multiset<TypeName> VariableName; multiset<int> s;
multiset 和 set 大部分操作相同,但支持在一个 set 内有多个元素。
注意在 multiset 中,如果 erase 一个数,仍然会把全部的数字删除。
erase删除时会删除所有的某个数,如果想要只删除一个有重的数字的话,需要删除它的迭代器;
6.Map
引例:
给出许多学生的名字和成绩,要求使用名字找到成绩。
比如学生 __debug 的微积分 59 分,我们希望能通过 __debug 找到 59.
a['__debug'] = 59 ?
楼上的数组显然——做不到;
所以有一个神奇的东西可以做到——map;
#include <map> using namespace std; map<TypeName1, TypeName2> VariableName; map<string, int> a;
map要保证第一维也就是TypeName1需要是可以排序的(map是有序的根据???)
举一坨栗子:

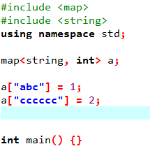
map其实是set的一种比较神奇的形式:



上下等价;
 这就是一个map
这就是一个map
map 的本质就是一个元素为 pair 的 set,重载了 [] 运算符。
7.stack:
#include <stack> using namespace std; stack<TypeName> VariableName; stack<int> a;
//一个“先进后出”结构。

8.queue
#include <queue> using namespace std; queue<TypeName> VariableName; queue<int> a; //一个“先进先出”结构。

9.priority_queue:
#include <queue> using namespace std; priority_queue<TypeName> VariableName; priority_queue<int> a;
一个类似队列的结构。不同的是,队列每次出最先进队的元素,优先队列每次出最大的元素。
类似 Set,需要重载 < 运算符。
是一个大根堆,如果定义int型并且要建小根堆:

大根堆:

还可以用cmp:
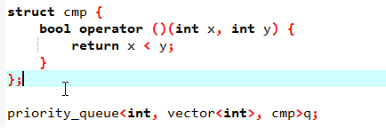
比较大小的话,cmp(1,2),显然它很像一个函数,但是c++不接受函数型,所以要改成一种类型opp会用到qwq
比set要慢,set和map比较快,开o2的话map可以跑得像o(1)一样;

10.algorithm:
(1)sort:O(nlogn)
#include <algorithm> using namespace std; int a[30]; vector<int> b; int main() { sort(a, a + 30); sort(b.begin(), b.end()); } 可以是指针或迭代器;
(2)Reverse:O(n)
#include <algorithm> using namespace std; int a[30]; vector<int> b; int main() { reverse(a, a + 30); reverse(b.begin(), b.end()); }
和sort用法相反?
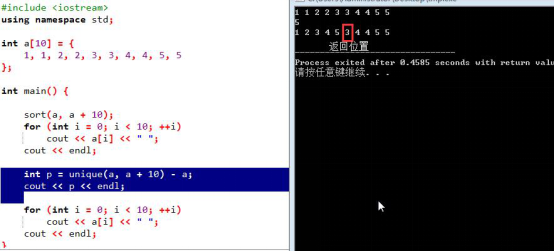
(3)unique去重:unique复杂度o(n)
应用的时候必须排好序,p指向的是去重过后的数组的后一个位置;

(4)fill:赋值:
把一段全都赋值成某个数:语法见下:
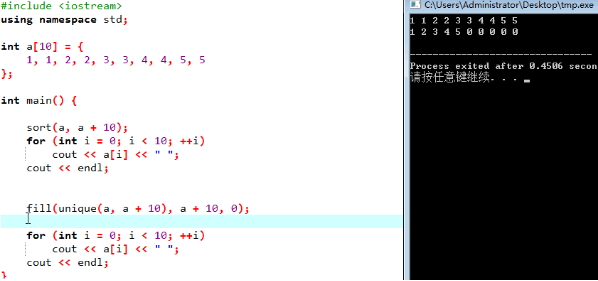
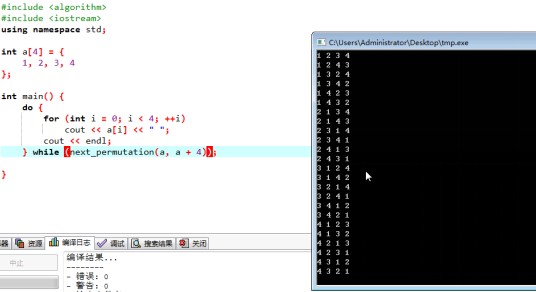
(5)Next Permutation:O(n!)
求排列,如果没有排列方式了,返回1;
函数是返回是否是最后一个排列
可以用来求全排列:

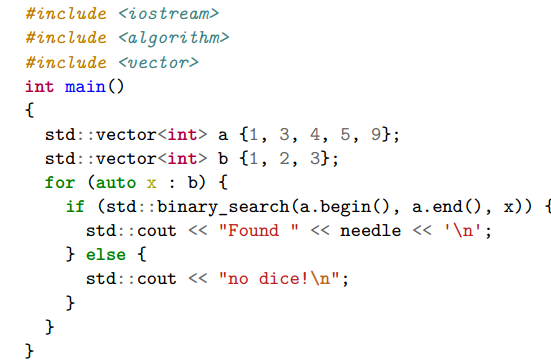
(6)Binary Search:写好的二分
从a.begin();开始
(7)Nth Element:



随机重拍里面的元素
 实现随机排列的方式
实现随机排列的方式
rand:
rand是个假随机,它有一个随机种子,srand改变他的种子,为了随机,用时间点来当种子srand(time(0))