参考Speech and Language Processing[1]
假设人类的语言是上帝掷骰子生成的, 那这个骰子应该是什么样的呢? 语言模型, 就是从概率的视角, 来描述这个骰子. 具体一点, 给定一句话或者词序列, 语言模型负责给出其出现的概率. 而其中最简单的一种语言模型就是n-gram模型.
n-gram就是n个连续的词, "我"是1-gram (或者unigram), "我们" 就是2-gram (或者bigram). 平时使用时, n-gram模型会简略成n-gram. 所以n-gram有两个意思, 一说是N个连续的词, 也指接下来要介绍的n-gram语言模型.
长度为n的一句话出现的概率可以表示为P(w1, w2,..., wn), 或者P(w1n). 如果直接估计这个概率, 需要统计两个东西, (1) {w1, w2,..., wn}这句话出现的次数, (2) 所有长度为n的词序列的个数. 想想看, 长度为n的一句话有多少种不同的情况, 当N比较大的时候呢? 而且随着序列变长, 0概率出现的情况会越来越多. 所以, 这种估计方法工作量大且不太可行. 如果通过概率论的链式法则对P(w1, w2,..., wN)进行分解, 就会得到:
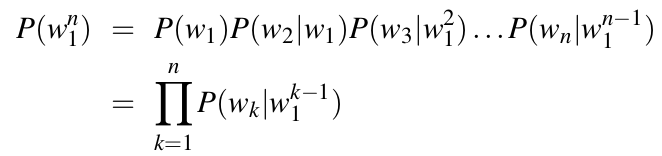
额.....好像还是需要统计较长序列的出现次数. 例如最后一项P(wn | w1n-1), 已知前n-1个词第n个词的概率, 还是会有上面说到的问题. 咋办呢? n-gram这个时候出场了. 以2-gram或者bigram为例, 他将上述公式中的条件概率进行的简化, 即一个词只与它前面一个词相关, 于是P(wn | w1n-1)≈P(wn | wn-1). 同理, 对于3-gram或者trigram, 一个词只与它之前两个词相关, 即P(wn | w1n-1)≈P(wn | wn-1, wn-2). 于是上述P(w1n) ≈ Π P(wk|wk-1). 我们只要估计P(wk|wk-1)就可以了.
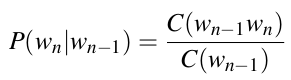
这的C(.)代表.出现的次数. 扩展到n-gram, 概率的计算公式为:
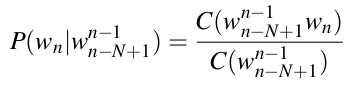
以bigram为例, 假设我们有如下这样的语料:

我们可以计算出各个bigram的概率为:
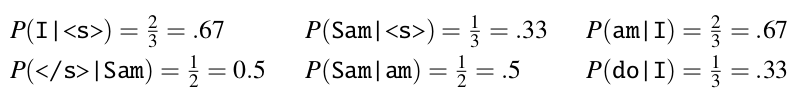
于是P(<s> I am Sam </s>) = P(I | <s>) * P(am | I) * P(Sam | am) * P(</s> | Sam) = 0.67 * 0.67 * 0.5 * 0.5 = 0.11225. 实际应用中, 为了防止多个小于0的数相乘引发的下溢, 常对概率取对数. 于是, 概率相称变成对数概率的相加, 如需获得真正的概率值, 则将对数概率作为自然对数e的指数即可计算得出.
[1] Daniel Jurafsky and James H Martin. Speech and Language Processing: An Introduction to Natural Language Processing, Computational Linguistics, and Speech Recognition. Tracy Dunkelberger, 2008.