Java下载:
首先我们要下载Java的JDK包,下载:https://www.oracle.com/java/technologies/javase-downloads.html。
在里面找见自己系统对应的版本:
下载后jdk的安装提示进行,在安装jdk时也会安装JRE,一起安装就行。
配置环境变量
1.右击我的电脑→属性→高级系统设置→高级→环境变量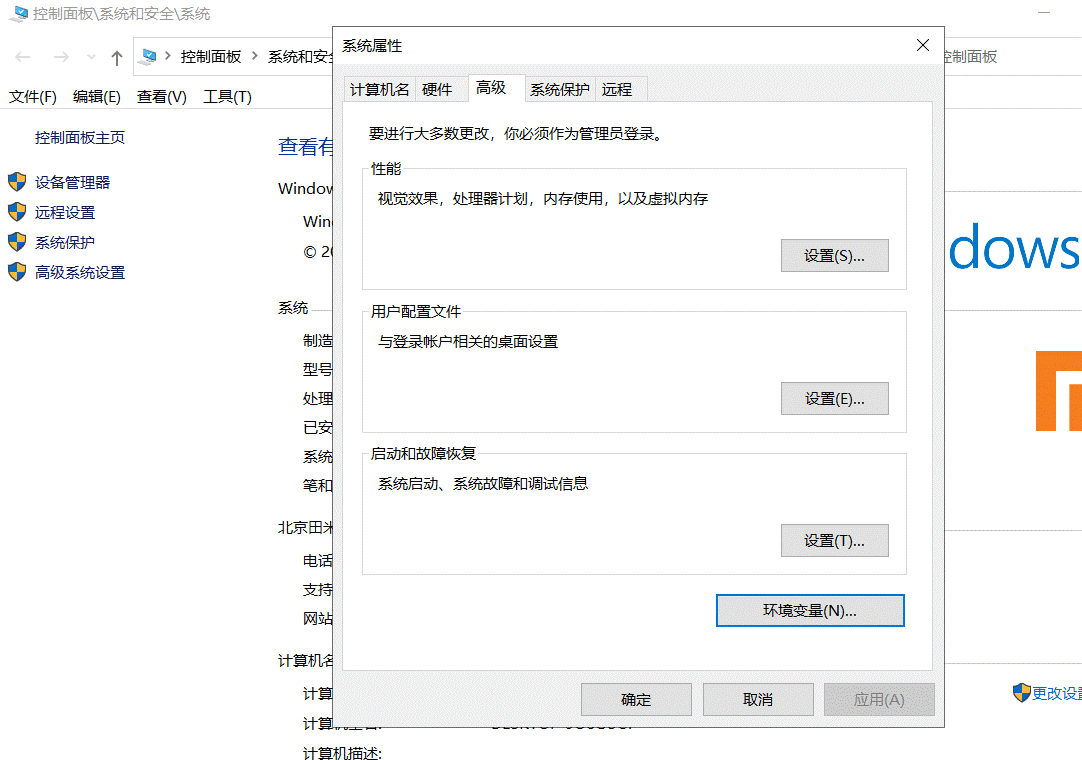
2.新建“JAVA_HOME”系统变量,变量名必须大写,变量值是自己安装jdk的位置。
3.同上,新建“CLASSPATH”系统变量,变量值为“.;%JAVA_HOME%lib;%JAVA_HOME%libdt.jar;%JAVA_HOME%lib ools.jar;”。
4.双击“系统变量”下的“Path”变量进行编辑。(此时可以看到JAVA_HOME已经存在于系统变量中)
通过控制台测试JDK是否安装成功
1.同时按键盘上“win”、“R”两个键打开运行,输入“cmd”确定打开控制台。
2.键入命令: java、javac 几个命令,出现以下信息,说明环境变量配置成功。
jdk基本包 功能 用途
java.lang包:该包提供了Java编程的基础类,例如 Object、Math、String、StringBuffer、System、Thread等,不使用该包就很难编写Java代码了。
java.util包:该包提供了包含集合框架、遗留的集合类、事件模型、日期和时间实施、国际化和各种实用工具类(字符串标记生成器、随机数生成器和位数组)。
java.io包:该包通过文件系统、数据流和序列化提供系统的输入与输出。
java.sql包:该包提供了使用Java语言访问并处理存储在数据源(通常是一个关系型数据库)中的数据API。
jar包和war包区别:
jar包介绍:
JAR(Java Archive,Java 归档文件)是与平台无关的文件格式,它允许将许多文件组合成一个压缩文件。JavaSE程序可以打包成Jar包;
JAR 文件格式以流行的 ZIP 文件格式为基础。与 ZIP 文件不同的是,JAR 文件不仅用于压缩和发布,而且还用于部署和封装库、组件和插件程序,并可被像编译器和 JVM 这样的工具直接使用。
jar包就是别人已经写好的一些类,然后对这些类进行打包。
war包介绍:
war是一个可以直接运行的web模块,通常用于网站,打成包部署到容器中。以Tomcat来说,将war包放置在其webapps目录下,然后启动Tomcat,这个包就会自动解压,就相当于发布了。
简单来说,war包是JavaWeb程序打的包,war包里面包括写的代码编译成的class文件,依赖的包,配置文件,所有的网站页面,包括html,jsp等等。一个war包可以理解为是一个web项目,里面是项目的所有东西。
区别:WAR文件代表了一个Web应用程序,JAR是类的归档文件。
基础数据类型
int、short、byte、long、char、float、double、boolean
注意:string并不是基础数据类型。它是jdk1.7加入的。
String和StringBuilder、StringBuffer的区别:
1.可变性:String不可变的字符序列,Builder和Buffer是可变的字符序列。
2.线程安全:String是线程安全的,StringBuilder是线程不安全的,StringBuffer是线程安全。StringBuidler效率高于StringBuffer。
因为String是不可变的一般情况下,效率最低。
3.使用方式:如果字符串变换较少,使用String类型,如果拼接操作较多使用StringBuilder,如果要求线程安全使用StringBuffer。
Java运算符优先级
所有的数学运算都认为是从左向右运算的,Java语言中大部分运算符也是从左向右结合的,只有单目运算符、赋值运算符和三目运算符例外,其中,单目运算符、赋值运算符和三目运算符是从右向左结合的,也就是从右向左运算。
一般而言,单目运算符优先级较高,赋值运算符优先级较低。算术运算符优先级较高,关系和逻辑运算符优先级较低。
多数运算符具有左结合性,单目运算符、三目运算符、赋值运算符具有右结合性。
Java 语言中运算符的优先级共分为 14 级,其中 1 级最高,14 级最低。在同一个表达式中运算符优先级高的先执行。
表 1 列出了所有的运算符的优先级以及结合性。

数组
数组可以说是把一个内存空间分给它,数组有多大就只有多大的内存空间。那么当数组开辟空间之后:
1.数组的访问通过索引完成,即:“数组名称[索引]”,但是需要注意的是,数组的索引从0开始,
所以索引的范围就是0 ~ 数组长度-1,例如开辟了3个空间的数组,
所以可以使用的索引是:0,1,2,如果此时访问的时候超过了数组的索引范围,会产生 java.lang.ArrayIndexOutOfBoundsException 异常信息。
2.当我们数组采用动态初始化开辟空间后,数组里面的每一个元素都是该数组对应数据类型的默认值。
3.数组本身是一个有序的集合操作,所以对于数组的内容操作往往会采用循环的模式完成,数组是一个有限的数据集合,所以应该使用 for 循环。
集合
Collection分为:List和Set
Collection接口储存不唯一,无序
List接口储存不唯一,有序的对象。
List分为ArrayList和LinkedList
1.ArrayList基于动态数组实现的非线程安全的集合,对于随机index访问的get和set方法,一般ArrayList的速度要优于LinkedList。
因为ArrayList直接通过数组下标直接找到元素。ArrayList在新增和删除元素时,可能扩容和复制数组。
2.LinkedList基于链表实现的非线程安全的集合,要移动指针遍历每个元素直到找到为止。
新增和删除元素,一般LinkedList的速度要优于ArrayList,LinkedList实例化对象需要时间外,只需要修改指针即可。
3.ArrayList的空间浪费主要体现在在list列表的结尾预留一定的容量空间,而LinkedList的空间花费则体现在它的每一个元素都需要消耗相当的空间。
Set接口储存唯一,无序的对象。
Map接口是键值对形势。
Map:key-value 的键值对,key 不允许重复,value 可以。
1.严格来说 Map 并不是一个集合,而是两个集合之间 的映射关系。
2.这两个集合没每一条数据通过映射关系,我们可以看成是一条数据。即 Entry(key,value)。Map 可以看成是由多个 Entry 组成。
3.因为 Map 集合即没有实现于 Collection 接口,也没有实现 Iterable 接口,所以不能对 Map 集合进行 for-each 遍历。
Map和Set关系:
HashMap 和 HashSet ,都采 哈希表算法,TreeMap 和 TreeSet 都采用 红-黑树算法,
LinkedHashMap 和 LinkedHashSet 都采用 哈希表算法和红-黑树算法。
HashMap和Hashtable的区别:
1.HashMap是基于哈希表实现的,每一个元素是一个key-value对,其内部通过单链表解决冲突问题,容量不足(超过了阀值)时,同样会自动增长。
2. HashMap是非线程安全的,只是用于单线程环境下,多线程环境下可以采用concurrent并发包下的concurrentHashMap。
3.HashMap 实现了Serializable接口,因此它支持序列化,实现了Cloneable接口,能被克隆。
4.HashMap存数据的过程是:
HashMap内部维护了一个存储数据的Entry数组,HashMap采用链表解决冲突,每一个Entry本质上是一个单向链表。当准备添加一个key-value对时,首先通过hash(key)方法计算hash值,然后通过indexFor(hash,length)求该key-value对的存储位置,计算方法是先用hash&0x7FFFFFFF后,再对length取模,这就保证每一个key-value对都能存入HashMap中,当计算出的位置相同时,由于存入位置是一个链表,则把这个key-value对插入链表头。
5.HashMap中key和value都允许为null。key为null的键值对永远都放在以table[0]为头结点的链表中。
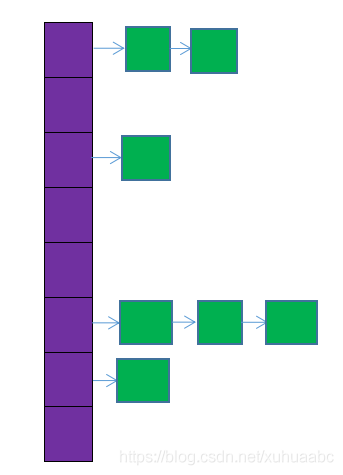
图中,紫色部分即代表哈希表,也称为哈希数组,数组的每个元素都是一个单链表的头节点,链表是用来解决冲突的,如果不同的key映射到了数组的同一位置处,就将其放入单链表中。
分析二者不同:
HashMap继承自AbstractMap类。但二者都实现了Map接口。
Hashtable继承自Dictionary类,Dictionary类是一个已经被废弃的类。
HashMap线程不安全,HashTable线程安全。
HashMap是没有contains方法的,而包括containsValue和containsKey方法;hashtable则保留了contains方法。
Hashmap是允许key和value为null值的,用containsValue和containsKey方法判断是否包含对应键值对;HashTable键值对都不能为空,否则包空指针异常。