Elastic公司在收购了Prelert半年之后,终于在Elasticsearch 5中推出了Machine Learning功能。Prelert本身就擅长做时序性数据的异常检测,从这点上讲也比较契合elasticsearch的数据特征。在做了一段时间的PoC之后,发现这个功能的最大作用就是troubleshooting过程中帮助定位日志的时间和空间,提高日志搜索的目的性,最终还是服务于elasticsearch。只不过这个功能需要额外的license,不然只有一个月的试用期,略显不爽。
还是先说是Perlert,Perlert做异常检测的基本原理在其CTO Stephen Dodson的文章中有详细介绍:《Anomaly Detection in Application Performance Monitoring Data》。通读全文,发现核心算法基于概率统计的假设检验,针对时间序列的time window(Elasticseaerch中叫bucket span)学习出P-value,用于甄别异常。
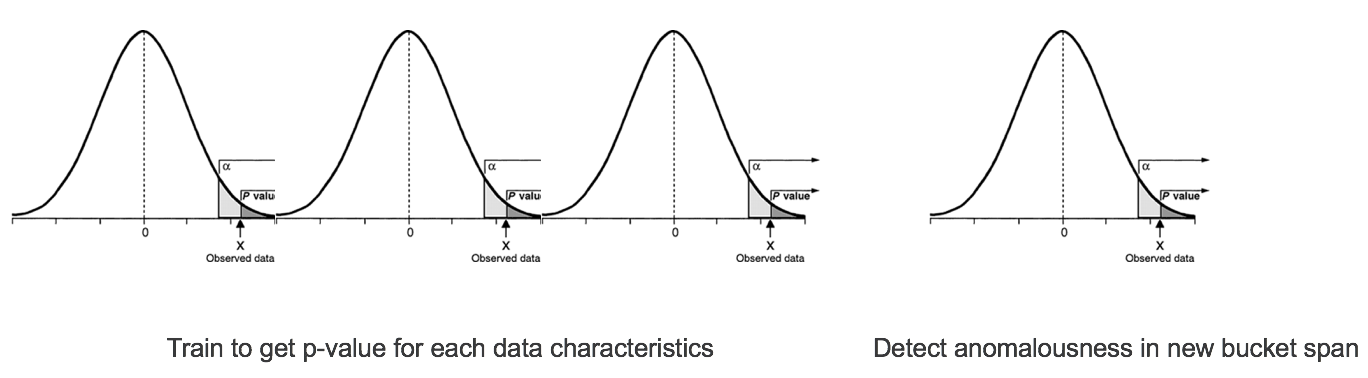
大致原理如上图,当然在实现中有对非正态分布数据的处理以及对P-value计算的优化。
了解了原理,回到Elasticsearch Machine Learning,虽然感觉没有用到什么Machine Learnig的算法,但是确实针对时序性的运维数据分析,非常实用。
笔者的PoC基于Elasticstack 5.5.2,在kibana上目前支持创建三种类型的job:
single metrics job:只针对index的某一个field的数据分析。
multi metrics job:可以对index的多个field进行数据分析。并不是多个field在一起分析,而是每个field的数据单独分析。
advance job:像multi metrics job一样可以支持多个field数据的分析,同时在一个field数据的分析过程中,加上别的field的影响因素。
一些有用的操作:
single job的创建过程中,对数值型的数据提供了一些aggreate方法,用于对要分析的数据预处理:

multi job支持split data操作,即对某个field的value进行partition。比如分析http_response_time的数据,可以按照field:http_response_status_code的value(200,404,500)分别进对应行分析,这对于某些情况下,提高异常检测的精准度非常有意义。
multi job还支持设定key field(influencer),在找到异常点后,可以显示该点的key field的值对这个异常的贡献有多大。这个功能对应上文所说的帮助精确定位日志查询。比如常设clientId, nodeArea等具有明确意义的field为key filed,可以帮助troubleshooting。
Advance job具有multi job的所有功能,同时又增强了detector功能,除了by_partition,还支持by_field, over_field等数据范围划分的操作。
本来,选取bucket span是创建job的过程中最难把握的环节,但在5.5之后,elastic提供了auto estimate bucket span的功能,在一定程度上解决了这方面的问题。
Frequency:bucket span时间内进行异常检测的间隔,防止bucket span设置的太大,异常检测出来的时效性过低。
Example:
1. 数据准备:进入elasticsearch的数据未必能直接做learning,很多有价值的数据存在raw data里面。可以通过logstash的grok方法把需要进行分析的属性提取出来,以key-value的形式存入elasticsearch.
2.创建job,比如创建一个advance job。
选择index=>add new detector & add influencer => start job.
在add new detector的时候需要注意选择是over field和partition field的区别,over field是基于存在某属性的所有bucket span进行detector,有点儿聚类的感觉。 Partition field是按照某个属性的值进行划分partition,在所属partition范围内进行detector。
3. 结果查询。
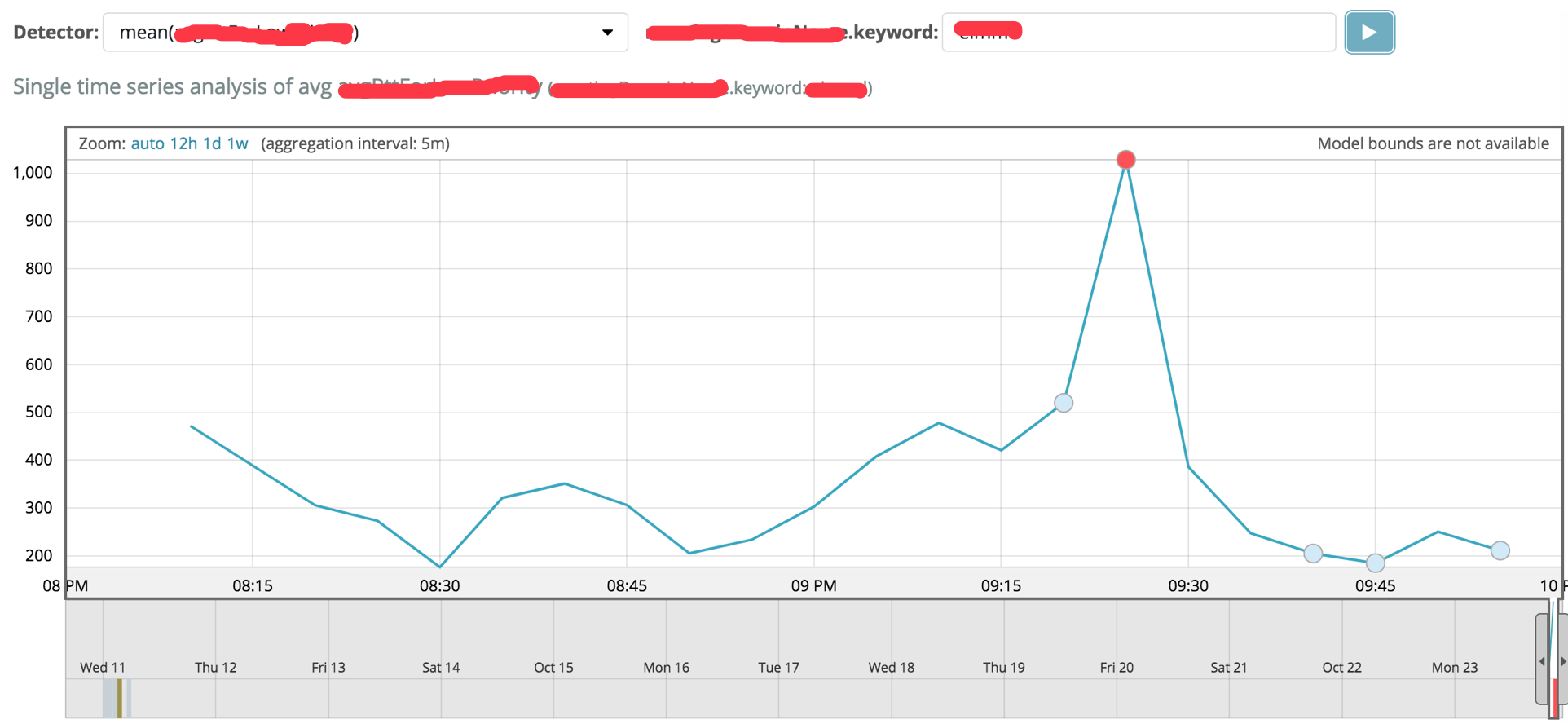
可以看到single metrics views里面检测出来的异常点, 可以按照influencer进行再次的过滤,使得influencer的在图上更近突出。通过点击可以查看异常的的具体信息。
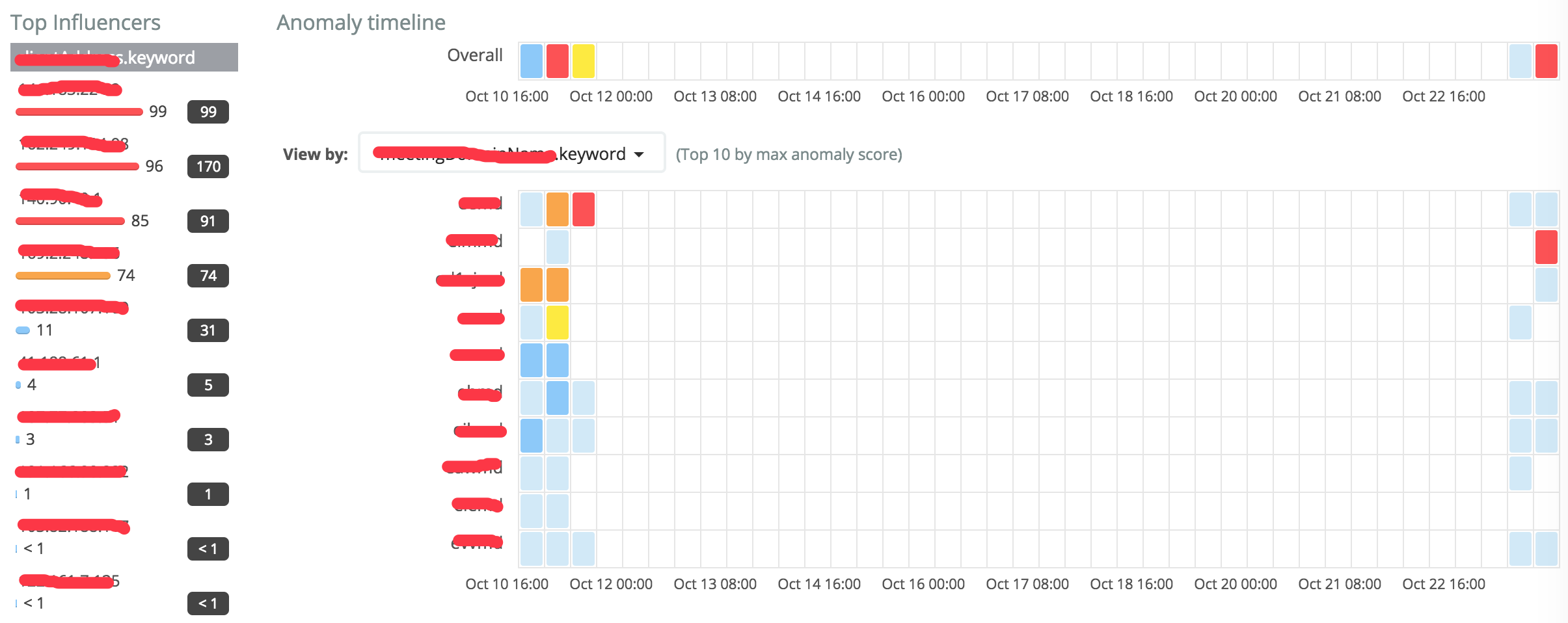
可以通过Anomaly Explorer窗口通过view by influencer来观察最有可能出异常的influencer值。
总之,Elasticsearch的Machine Learning主要还是为了配合search功能使用的,帮助更好的进行日志查询。