要爬取的新闻信息
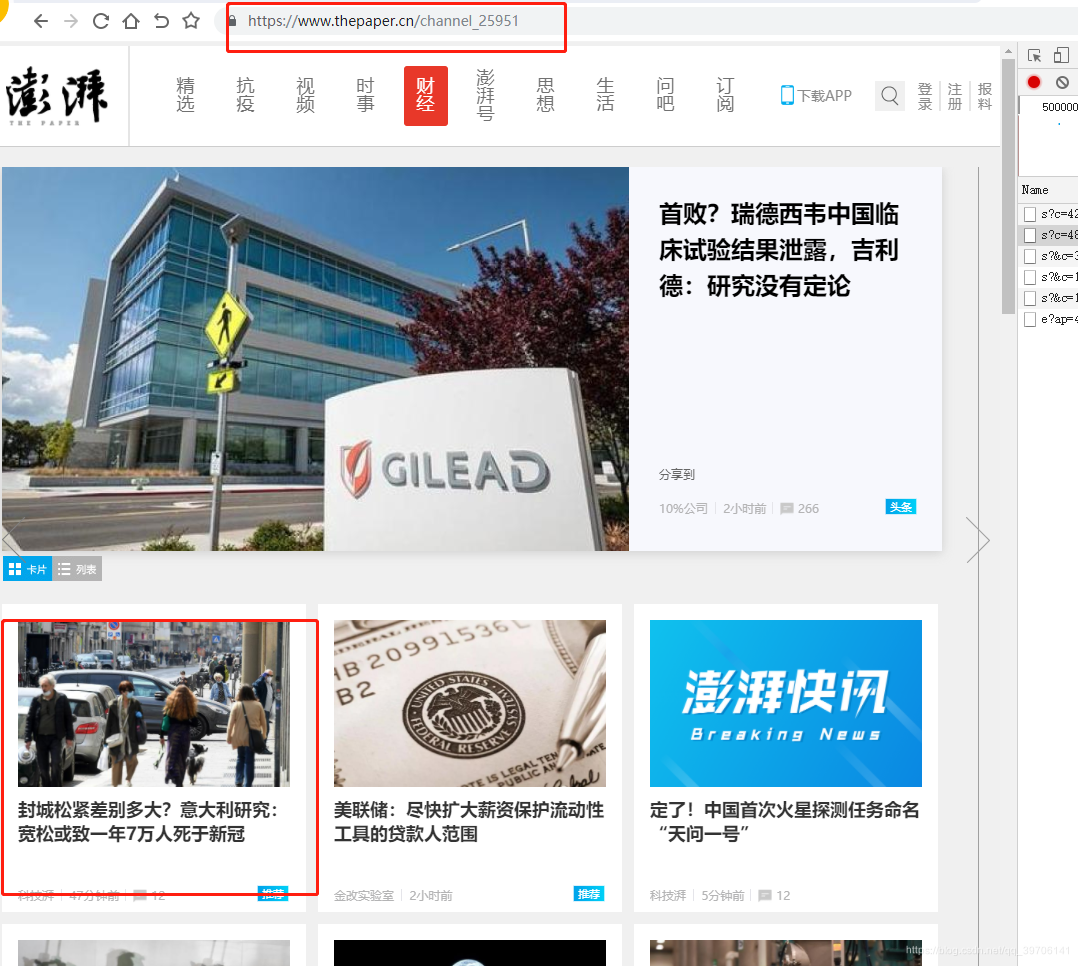 可以通过Ctrl+U快捷键查看页面的html源码,便于数据结构分析
可以通过Ctrl+U快捷键查看页面的html源码,便于数据结构分析
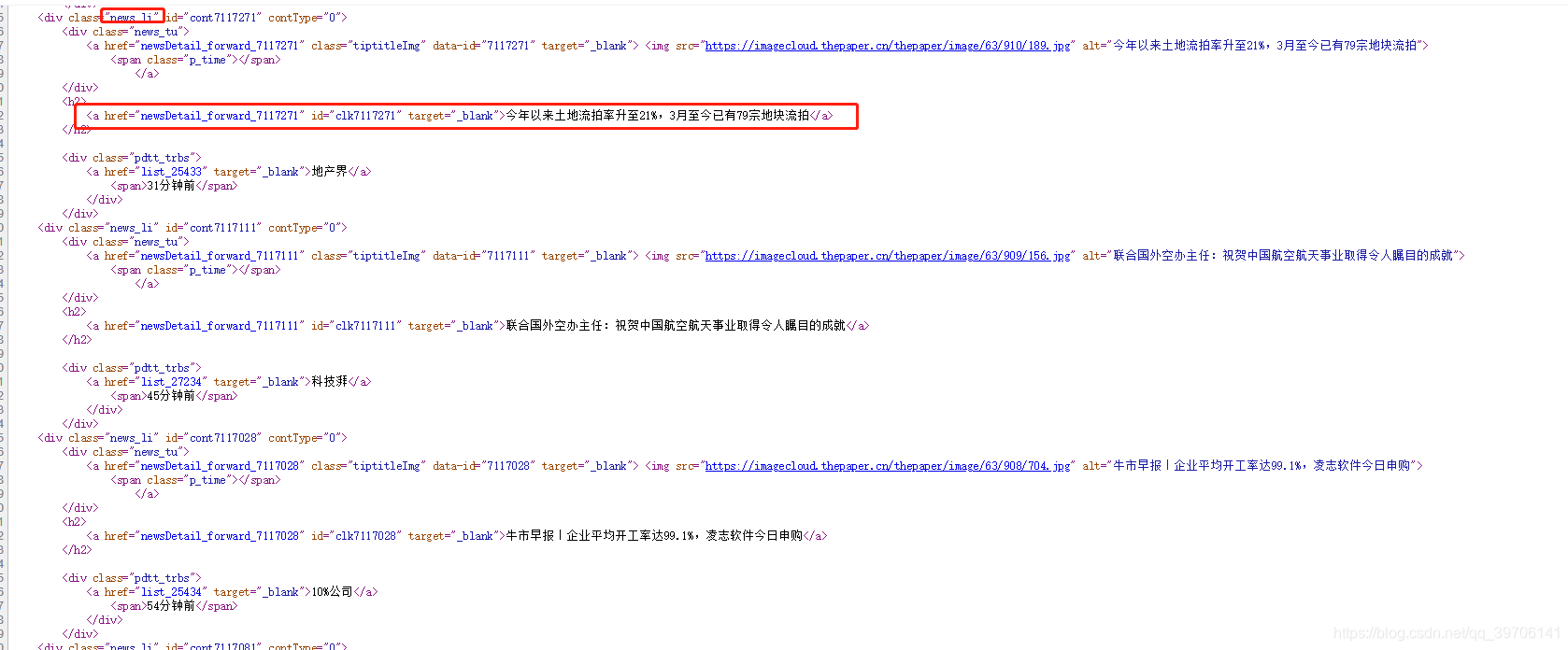 数据结构:类news_li下的h2标签下的a链接指定每个新闻的详情
数据结构:类news_li下的h2标签下的a链接指定每个新闻的详情
完整代码如下:
#encoding:utf-8
import requests
from pyquery import PyQuery as pq
import os
import datetime
header = {
"Referer": "https://www.thepaper.cn/channel_25951",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36"
}
base_url = "https://www.thepaper.cn/"
def index():
url = base_url + "channel_25951"
response = requests.get(url, header).text
# 数据初始化
doc = pq(response)
# 使用css选择器的方式进行数据提取(类(news_li)———》h2标签--》a标签内容)
a = doc(".news_li h2 a").items()
for x in a:
# 获取新闻详情链接
href = base_url + x.attr("href")
# 提取文本数据
title = x.text()
content(href, title)
def content(href, title):
response = requests.get(href, header).text
doc = pq(response)
news = doc(".news_txt").items()
for x in news:
new = x.text()
date = datetime.datetime.now().strftime("%Y-%m-%d") + "//"
if not os.path.exists(date):
os.mkdir(date)
with open(date + "{}.txt".format(title),"a", encoding="utf-8") as f:
f.write(new)
index()
