文档最后附有测试用的XML文档。
本节要点:
- DOM解析方式
- SAX解析方式
- DOM4J对XML的解析
XML用于将数据组织起来,形成文档用于存储和传输;但仅仅这些是不够的,更多时候我们需要的是将xml中的数据解析出来,甚至是在程序中动态生成xml。操作xml的方式有两种DOM和SAX。
XML解析方式分为两种:DOM方式和SAX方式:
- DOM:Document Object Model,文档对象模型。这种方式是W3C推荐的处理XML的一种方式。
- SAX:Simple API for XML。这种方式不是官方标准,属于开源社区XML-DEV,几乎所有的XML解析器都支持它。
XML解析开发包:
- JAXP:是SUN公司推出的解析标准实现。
- Dom4J:是开源组织推出的解析开发包。(牛,大家都在用,包括SUN公司的一些技术的实现都在用)
- JDom:是开源组织推出的解析开发包。
JAXP:
- JAXP:(Java API for XML Processing)是开发包JavaSE的一部分,它由以下几个包及其子包组成:
- org.w3c.dom:提供DOM方式解析XML的标准接口
- org.xml.sax:提供SAX方式解析XML的标准接口
- javax.xml:提供了解析XML文档的类
- javax.xml.parsers包中,定义了几个工厂类。我们可以通过调用这些工厂类,得到对XML文档进行解析的DOM和SAX解析器对象。
1 DOM解析方式
DOM(Document Object Model),“文档对象模型”早期是为了解决不用浏览器间数据兼容问题提出的解决方案,现在已经是W3C组织推荐的处理可扩展标志语言的标准编程接口。
W3C DOM 被分为 3 个不同的部分/级别(parts / levels):
- 核心 DOM:用于任何结构化文档的标准模型
- XML DOM:用于 XML 文档的标准模型
- HTML DOM:用于 HTML 文档的标准模型
XML DOM 是:
- 用于 XML 的标准对象模型
- 用于 XML 的标准编程接口
- 中立于平台和语言
- W3C 的标准
SUN公司的JAXP(Java API for XML Processing)提供了对dom的支持;其解析步骤为:
- DocumentBuilderFactory.newInstance() 方法得到创建 DOM 解析器的工厂。, DocumentBuilderFactory是一个抽象工厂类,它不能直接实例化,但该类提供了一个newInstance方法 ,这个方法会根据本地平台默认安装的解析器,自动创建一个工厂的对象并返回。
- 调用工厂对象的 newDocumentBuilder方法得到 DOM 解析器对象。
- 调用 DOM 解析器对象的 parse() 方法解析 XML 文档,得到代表整个文档的 Document 对象,进行可以利用DOM特性对整个XML文档进行操作了。
具体代码如下:
1 DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); 2 3 DocumentBuilder builder = factory.newDocumentBuilder(); 4 5 Document doc = builder.parse(new File("books.xml"));
注:以下所有XML文档没有引入约束。
- 获取xml节点 内容
1 private static void findElement() throws ParserConfigurationException, 2 3 SAXException, IOException { 4 5 DocumentBuilderFactory factory =DocumentBuilderFactory.newInstance(); 6 7 DocumentBuilder builder = factory.newDocumentBuilder(); 8 9 Document doc = builder.parse(new File("books.xml")); 10 11 NodeList list = doc.getElementsByTagName("title"); 12 13 Node node = list.item(1); 14 15 System.out.println(node.getTextContent()); 16 17 }
- 获取属性内容
1 private static void getAttribute() throws ParserConfigurationException, 2 3 SAXException, IOException { 4 5 DocumentBuilderFactory factory =DocumentBuilderFactory.newInstance(); 6 7 DocumentBuilder builder = factory.newDocumentBuilder(); 8 9 Document doc = builder.parse(new File("books.xml")); 10 11 Element node = (Element) doc.getElementsByTagName("comment").item(1); 12 13 System.out.println(node.getAttribute("title")); 14 15 }
- 使用递归遍历xml文档
1 private static void loopNode() throws ParserConfigurationException, 2 3 SAXException, IOException { 4 5 DocumentBuilderFactory factory =DocumentBuilderFactory.newInstance(); 6 7 DocumentBuilder builder = factory.newDocumentBuilder(); 8 9 Document doc = builder.parse(new File("books.xml")); 10 11 loop(doc); 12 13 } 14 15 private static void loop(Node doc) { 16 17 NodeList list = doc.getChildNodes(); 18 19 for(int i=0;i<list.getLength();i++){ 20 21 Node node = list.item(i); 22 23 System.out.println(node.getNodeName()); 24 25 loop(node); 26 27 } 31 }
添加节点,内容,属性
1 private static void createElement() throws ParserConfigurationException, 2 3 SAXException, IOException,TransformerFactoryConfigurationError, 4 5 TransformerConfigurationException, TransformerException { 6 7 DocumentBuilderFactory factory =DocumentBuilderFactory.newInstance(); 8 9 DocumentBuilder builder = factory.newDocumentBuilder(); 10 11 Document doc = builder.parse(new File("books.xml")); 12 13 //创建结点 14 15 Element e = doc.createElement("language"); 16 17 //添加内容 18 19 e.setTextContent("Chinese"); 20 21 //添加属性 22 23 e.setAttribute("aa", "xxx"); 24 25 //获取父节点,并append新创建的结点 26 27 doc.getElementsByTagName("book").item(1).appendChild(e); 28 29 //使用Transformer将内存中更新过的xml文档写入实际的xml文档中 30 31 TransformerFactory tfactory = TransformerFactory.newInstance(); 32 33 Transformer tf = tfactory.newTransformer(); 34 35 tf.transform(new DOMSource(doc), new StreamResult(new File("books.xml"))); 36 37 }
删除节点注意:DOM的解析方式为将整个xml文档都加载入内存,因此对文档节点的添加、删除和修改操作都是只针对内存中的document对象,因此还需要使用Transformer类将修改真正写入到xml文件中!
1 private static void deleteElement() throws ParserConfigurationException, 2 3 SAXException, IOException, TransformerFactoryConfigurationError, 4 5 TransformerConfigurationException, TransformerException { 6 7 DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); 8 9 DocumentBuilder builder = factory.newDocumentBuilder(); 10 11 Document doc = builder.parse(new File("books.xml")); 12 13 //得到待删除的结点 14 15 Element e = (Element) doc.getElementsByTagName("language").item(0); 16 17 //获取结点的父节点,然后删除该子结点 18 19 e.getParentNode().removeChild(e); 20 21 //使用Transformer将内存中更新过的xml文档写入实际的xml文档中 22 23 TransformerFactory tfactory = TransformerFactory.newInstance(); 24 25 Transformer tf = tfactory.newTransformer(); 26 27 tf.transform(new DOMSource(doc), new StreamResult(new File("books.xml"))); 28 29 }
2 SAX解析方式
由于dom采用的是将xml文档加载入内存进行处理的方式,如果xml文档较大,则会导致加载时间过长,效率降低的情况,因此,sun公司在JAXP中又添加了对SAX的支持;
SAX,全称Simple API for XML,既是一种接口,也是一种软件包。它是一种XML解析的替代方法。SAX不同于DOM解析,它逐行扫描文档,一边扫描一边解析。由于应用程序只是在读取数据时检查数据,因此不需要将数据存储在内存中,这对于大型文档的解析是个巨大优势。
SAX采用事件处理的方式解析XML文件,利用 SAX 解析 XML 文档,涉及两个部分“解析器”和“事件处理器”:
- 解析器可以使用JAXP的API创建,创建出SAX解析器后,就可以指定解析器去解析某个XML文档。
- 解析器采用SAX方式在解析某个XML文档时,它只要解析到XML文档的一个组成部分,都会去调用事件处理器的一个方法,解析器在调用事件处理器的方法时,会把当前解析到的xml文件内容作为方法的参数传递给事件处理器。
- 事件处理器由程序员编写,程序员通过事件处理器中方法的参数,就可以很轻松地得到sax解析器解析到的数据,从而可以决定如何对数据进行处理.
示例:使用SAX读取XML
public static void main(String[] args) throws Exception, SAXException { //创建工厂 SAXParserFactory factory = SAXParserFactory.newInstance(); //使用工厂生成一个SAX解析器 SAXParser parser = factory.newSAXParser(); //解析xml文档 parser.parse(new File("books.xml"), new DefaultHandler(){ @Override public void startDocument() throws SAXException { System.out.println("文档开始读取了……"); } @Override public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException { //qName开始结点的名称 System.out.println("<"+qName+">"); for(int i=0;i<attributes.getLength();i++){ //getQName得到属性名称,getValue得到属性值 System.out.println(attributes.getQName(i) + ":" + attributes.getValue(i)); } } @Override public void characters(char[] ch, int start, int length) throws SAXException { //构造字符串,输出ch字符数组,从start开始,输出长度length System.out.println(new String(ch, start, length)); } @Override public void endElement(String uri, String localName, String qName) throws SAXException { //打印结束结点 System.out.println("<"+qName+">"); } @Override public void endDocument() throws SAXException { System.out.println("文档结束了……"); } }); }
3 DOM4J对XML的解析
JAXP是sun公司官方提供的java解析工具包,但很多其他企业和机构也都开发了自己的xml解析工具,甚至比JAXP更加优秀,比如DOM4J。
- Dom4j是一个简单、灵活的开放源代码的库。Dom4j是由早期开发JDOM的人分离出来而后独立开发的。与JDOM不同的是,dom4j使用接口和抽象基类,虽然Dom4j的API相对要复杂一些,但它提供了比JDOM更好的灵活性。
- Dom4j是一个非常优秀的Java XML API,具有性能优异、功能强大和极易使用的特点。现在很多软件采用的Dom4j,例如Hibernate,包括sun公司自己的JAXM也用了Dom4j。
- 使用Dom4j开发,需下载dom4j相应的jar文件。
- Dom4j的使用可参见其所提供的文档(quick start)
DOM4J需要加入两个包:dom4j-1.6.1.jar和jaxen-1.1-beta-6.jar
参考下载地址:http://pan.baidu.com/s/1eS3X3DS
示例:
- 查询
-
private static void find() throws DocumentException { SAXReader reader = new SAXReader(); Document document = reader.read(new File("books.xml")); //传统解析模式,不能根据结点名称直接查找,只能一级一级的往下查 /*Element root = document.getRootElement(); List<Element> list = root.elements(); List<Element> list1 = list.get(1).elements(); System.out.println(list1.get(1).getText());*/ //XPath模式解析 /*Element e = (Element) document.selectNodes("//title").get(1); System.out.println(e.getText());*/ //查找comment标签的title属性值 Element e = (Element) document.selectNodes("//comment[@id='S002']").get(0); System.out.println(e.attributeValue("title")); }
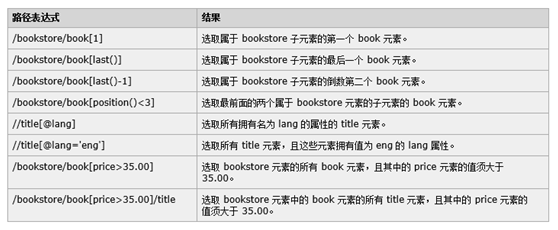
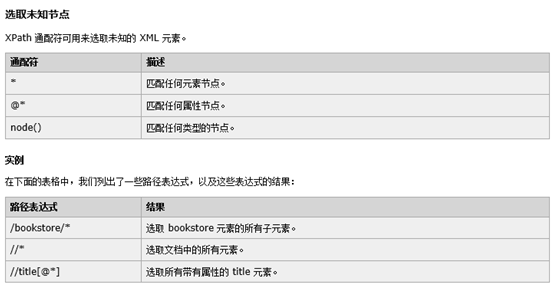
注:XPath的使用
在W3cschool中可以找到官方文档
例如:


- 新增
1 private static void addElement() throws DocumentException, IOException { 2 3 SAXReader reader = new SAXReader(); 4 5 Document document = reader.read(new File("books.xml")); 6 7 //使用工具类DocumentHelper创建结点 8 9 Element e = DocumentHelper.createElement("languge"); 10 11 e.setText("Chinese"); 12 13 e.addAttribute("bb", "boy"); 14 15 //寻找父节点 16 17 Element ee = (Element) document.selectNodes("//book").get(1); 18 19 //添加结点至内存文档 20 21 ee.add(e); 22 23 //Writing a document to a file,可以参考dom4j的API 24 25 XMLWriter writer = new XMLWriter( 26 27 new FileWriter("books.xml") 28 29 ); 30 31 writer.write(document); 32 33 writer.close(); 34 35 }
- 删除
-
1 private static void deleteElement() throws DocumentException, IOException { 2 3 SAXReader reader = new SAXReader(); 4 5 Document document = reader.read(new File("books.xml")); 6 7 //读取待删除结点的父节点 8 9 Element e = (Element) document.selectNodes("//languge").get(0); 10 11 //移除结点(内存) 12 13 e.getParent().remove(e); 14 15 //Writing a document to a file 16 17 XMLWriter writer = new XMLWriter( 18 19 new FileWriter("books.xml") 20 21 ); 22 23 writer.write(document); 24 25 writer.close(); 26 27 }
附件:
- 项目概况
-
XML文档
-
1 <?xml version="1.0" encoding="UTF-8"?> 2 <!-- <!DOCTYPE books SYSTEM "books.dtd"> --> 3 <books> 4 <book> 5 <author>joy</author> 6 <title>java core</title> 7 <price>100</price> 8 </book> 9 <book> 10 <author>joy1</author> 11 <title>Thinking in java</title> 12 <price>100</price> 13 </book> 14 <book> 15 <comment author="joy" id="S001" language="Chinese" price="20" title="Java"/> 16 <comment author="joy" id="S002" language="Chinese" price="20" title="Thinking in Java"/> 17 </book> 18 </books>