4.1环境准备
4.1.1 启动Hadoop
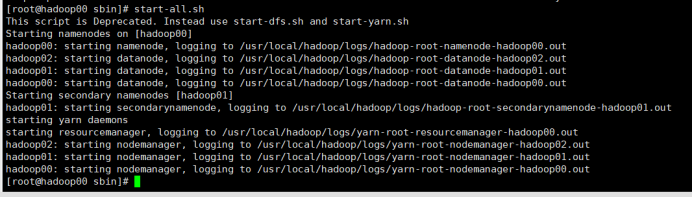
4.1.2 安装MySQL
1、安装包
将安装包复制到目录/usr/local/,当前使用版本如下:
mysql-5.7.22-linux-glibc2.12-x86_64.tar.gz
解压:
#tar xzvf mysql-5.7.22-linux-glibc2.12-x86_64.tar.gz
修改名称:
#mv mysql-5.7.22-linux-glibc2.12-x86_64 mysql
创建mysql用户组和用户:
# groupadd mysql
# useradd -r -g mysql mysql
2、在/usr/local/mysql目录下创建data目录
#mkdir /usr/local/mysql/data
3、更改mysql目录下所有的目录及文件夹所属的用户组和用户,以及权限
# chown -R mysql:mysql /usr/local/mysql
# chmod -R 755 /usr/local/mysql
4、编译安装并初始化mysql,务必记住初始化输出日志末尾的密码(数据库管理员临时密码)
#cd /usr/local/mysql/bin
#./mysqld --initialize --user=mysql --datadir=/usr/local/mysql/data --basedir=/usr/local/mysql
5、运行初始化命令成功后,输出日志如下:

记录日志最末尾位置root@localhost:后的字符串,此字符串为mysql管理员临时登录密码。如当前为:ykmpcILAR7=_
6、编辑配置文件my.cnf,添加配置如下
# vi /etc/my.cnf
7、启动mysql服务器
# /usr/local/mysql/support-files/mysql.server start
显示如下结果,说明数据库安装成功

8、添加软连接,并重启mysql服务
#ln -s /usr/local/mysql/support-files/mysql.server /etc/init.d/mysql
#ln -s /usr/local/mysql/bin/mysql /usr/bin/mysql
#service mysql restart

9、登录mysql,修改密码(密码为步骤5生成的临时密码)
#mysql -u root -p
Enter password:
mysql>set password for root@localhost = password('yourpass');

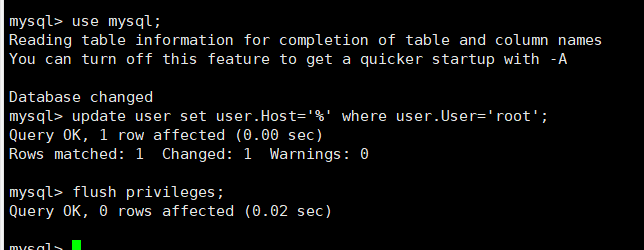
10、开放远程连接
mysql>use mysql;
msyql>update user set user.Host='%' where user.User='root';
mysql>flush privileges;
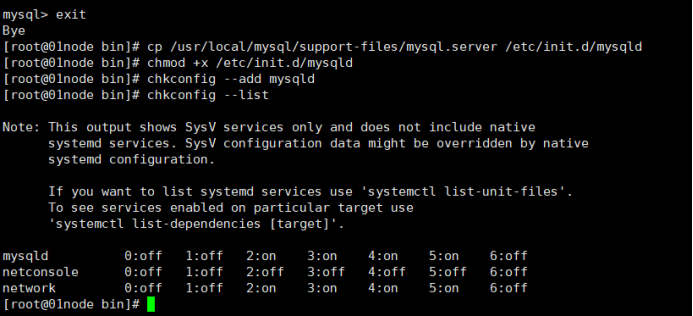
11、设置开机自动启动
- 将服务文件拷贝到init.d下,并重命名为mysql
# cp /usr/local/mysql/support-files/mysql.server /etc/init.d/mysqld
- 赋予可执行权限
# chmod +x /etc/init.d/mysqld
- 添加服务
# chkconfig --add mysqld
- 显示服务列表
# chkconfig --list
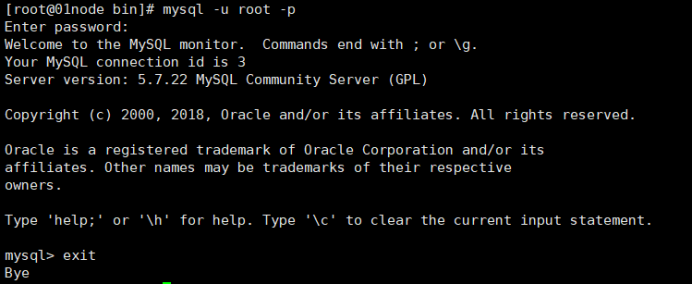
12、验证mysql数据库是否可用
所用命令或代码如下,此命令要在mysql安装目录下的bin文件夹下输入:
# mysql –u root –p
实验操作演示:
4.2安装并配置hive
4.2.1 在apache官网下载Hive安装包
安装包已经存放到/usr/local目录下,在/usr/local目录下解压Hive安装包,所用命令或代码:
# cd /usr/local
# tar zxvf apache-hive-3.1.2-bin.tar.gz
# mv apache-hive-3.1.2-bin hive
4.2.2 配置环境变量
修改环境变量,所用命令或代码:
# vim /etc/profile
加入hive相关的环境变量
export HIVE_HOME=/usr/local/hive
export PATH=$HIVE_HOME/bin:$HIVE_HOME/conf:$PATH
使修改文件生效:
# source /etc/profile
4.2.3 准备Hive的配置文件
进入hive 配置文件目录:
# cd /usr/local/hive/conf
把初始化的文件复制一份出来 并且改名:
所用命令或代码:
#cp hive-env.sh.template hive-env.sh
#cp hive-default.xml.template hive-site.xml
#cp hive-log4j2.properties.template hive-log4j2.properties
#cp hive-exec-log4j2.properties.template hive-exec-log4j2.properties
实验操作演示:

4.2.4 修改hive-env.sh
在该文件添加以下四个环境变量的配置:
#jdk目录
export JAVA_HOME=/usr/local/jdk
#hadoop安装目录
export HADOOP_HOME=/usr/local/hadoop
##Hive安装路径
export HIVE_HOME=/usr/local/hive
##Hive配置文件路径
export HIVE_CONF_DIR=${HIVE_HOME}/conf
实验操作演示:


4.2.4 配置hive,使用mysql存放hive的元数据
1、复制mysql驱动程序到hive的lib目录下
mysql驱动包已经放在local目录下,复制过程如下。
注意:其他版本的驱动不一定兼容
# cp mysql-connector-java-5.1.17.jar /usr/local/hive/lib/
实验操作演示:

2、配置hive-site.xml
- l 将${system:...字样替换成具体路径,具体修改项如下:
<property> <name>hive.exec.local.scratchdir</name> <value>/usr/local/hive</value> <description>hive作业的暂存空间</description> </property> <property> <name>hive.downloaded.resources.dir</name> <value>/usr/local/hive/downloads</value> <description>远程添加资源文件的临时目录 </description> </property> <property> <name>hive.querylog.location</name> <value>/usr/local/hive/querylog</value> <description>Location of Hive run time structured log file</description> </property> <property> <name>hive.server2.logging.operation.log.location</name> <value>/usr/local/hive/server2_logs</value> <description>Top level directory where operation logs are stored if logging functionality is enabled</description> </property>
- l 在 hive-site.xml 文件中配置 MySQL 数据库连接信息。
<property> <name>javax.jdo.option.ConnectionURL</name> <value> jdbc:mysql://192.168.11.130:3306/hive</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>111</value> </property>
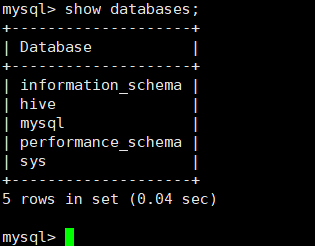
4.2.5 在msyql中创建存放hive信息的数据库
命令如下:
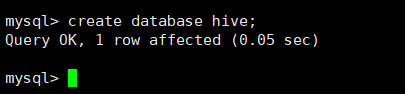
mysql>create database hive;
实验操作演示:
4.2.6 初始化hive的元数据(表结构)到mysql中
所用命令或代码:
# cd /usr/local/hive/bin
# schematool -dbType mysql –initSchema
实验操作演示:


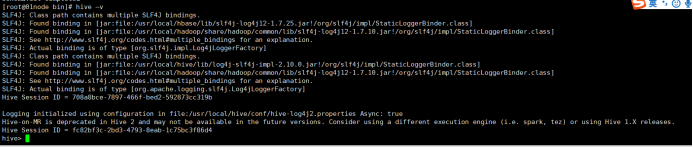
4.3 Hive的访问
所用命令或代码:
# hive –v
实验操作演示:
4.4 HiveQL:数据定义
4.4.1 应用HiveQL创建数据库
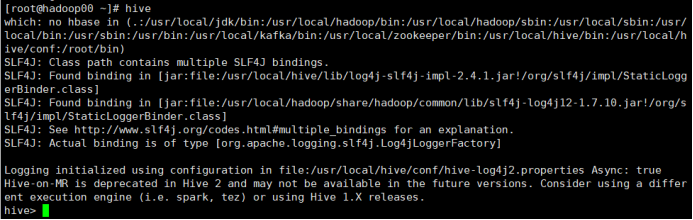
1) 进入Hive命令模式
所用命令或代码:(如果已经进入Hive命令模式则略过此步骤)
# hive
实验操作演示:
2) 创建数据库hive
所用命令或代码:
hive> create database hive;
实验操作演示:
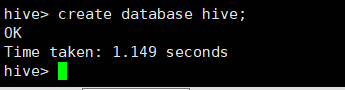
如果hive数据库已经存在,则会抛出异常,可以加上if not exists关键字,则不会抛出异常。
hive> create database if not exists hive;
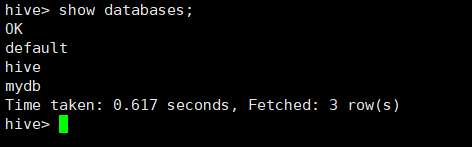
3) 查看创建好的数据库
所用命令或代码:
hive> show databases;
实验操作演示:
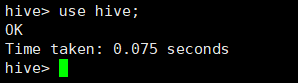
4) 使用创建好的数据库
所用命令或代码:
hive>use hive;
实验操作演示:
4.4.2 应用HiveQL创建表
1) 创建usr表
在hive数据库中,创建表usr,含三个属性id,name,age。
所用命令或代码:
hive>create table if not exists usr(id bigint,name string,age int);
实验操作演示:

2) 创建表时定义分隔符

所使用命令:
# create table employee (id int,name string,salary int,position string) row format delimited fields terminated by ' ' ;
3) 复制表
a、复制表结构和数据
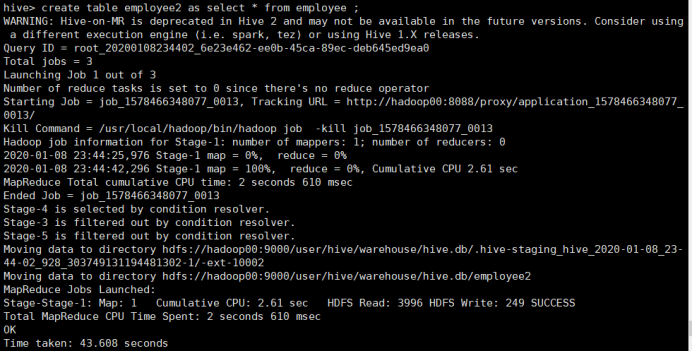
所使用命令:
# create table employee2 as select * from employee ;
查询结果:
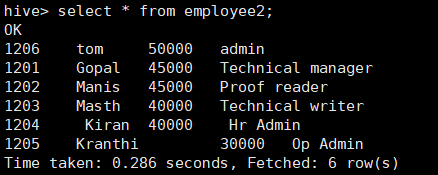
b、复制表结构

所使用命令:
# create table employee3 like employee;
查询结果:

4.4.3 应用HiveQL创建分区表
分区表可以从目录的层面控制搜索数据的范围。
1、创建分区表

所使用命令:
# CREATE TABLE t(id int,name string,age int) PARTITIONED BY (Year INT, Month INT) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' ;
2、添加分区,创建目录

# alter table t add partition (year=2014, month=11) partition (year=2014, month=12);
3、显式表的分区信息
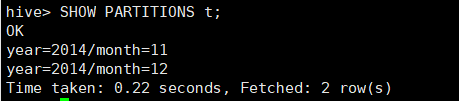
所使用命令:
# SHOW PARTITIONS t;
4、删除分区

所使用命令:
# ALTER TABLE t DROP IF EXISTS PARTITION (year=2014, month=12);
5、查看分区结构
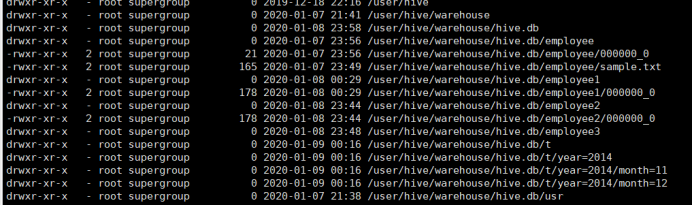
如上图所示:
/user/hive/warehouse/hive.db/t/year=2014/month=11
/user/hive/warehouse/hive.db/t/year=2014/month=12
所使用命令:
# dfs -lsr /;
6、查看表结构
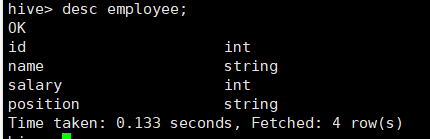
所使用命令:
# desc employee;
4.4.4 应用HiveQL创建视图
1、 创建视图
创建视图little_usr,只包含usr表中id,age属性
实验操作演示:

所用命令或代码:
hive>create view little_usr as select id,age from usr;
2、 查看所有的表和视图
实验操作演示:
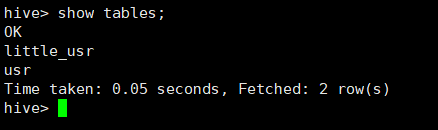
所用命令或代码:
hive> show tables;
3、查看以u开头的所有表和视图
实验操作演示:
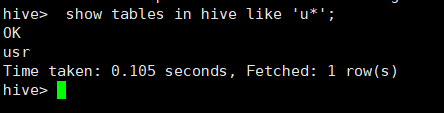
所用命令或代码:
hive> show tables in hive like 'u*';
4.5 HiveQL:数据操作
4.5.1 实验准备
- 本地/usr/local/data目录下创建文件sample.txt,并插入以下内容:
1201 Gopal 45000 Technical manager
1202 Manis 45000 Proof reader
1203 Masth 40000 Technical writer
1204 Kiran 40000 Hr Admin
1205 Kranthi 30000 Op Admin
- 创建employee表

所用命令或代码:
# create table employee (id int,name string,salary int,position string) row format delimited fields terminated by ' ' ;
4.5.2 应用LOAD DATA语句向数据表内加载文件
将本地/usr/local/data目录下文件sample.txt内容装载到employee表中:

所用命令或代码:
# LOAD DATA LOCAL INPATH '/usr/local/data/sample.txt' overwrite into table employee;
查询表内数据:

所使用命令代码:
# select * from employee;
4.5.3 应用INSERT语句将查询结果插入数据表
- insert into方式插入一条数据:
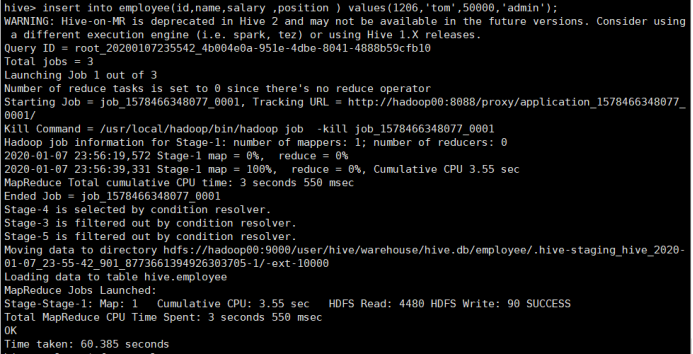
所使用命令代码:
# insert into employee(id,name,salary ,position ) values(1206,'tom',50000,'admin');
查询插入结果:
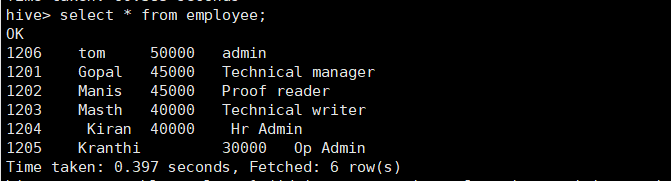
- 应用INSERT语句将查询结果插入数据表:
创建备份表employee1:

所使用命令:
# create table employee1 (id int,name string,salary int,position string) row format delimited fields terminated by ' ' ;
将查询结果追加到表:
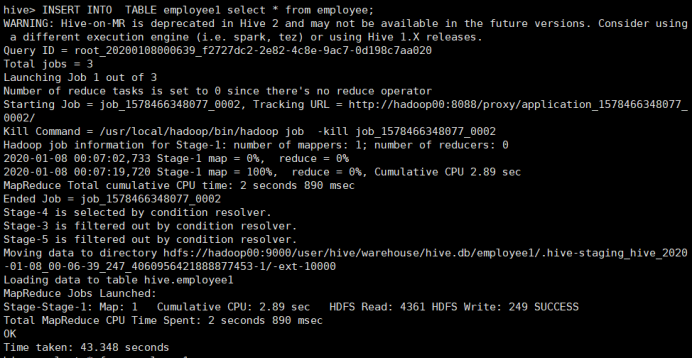
所使用命令:
# INSERT INTO TABLE employee1 select * from employee;
查询插入结果:
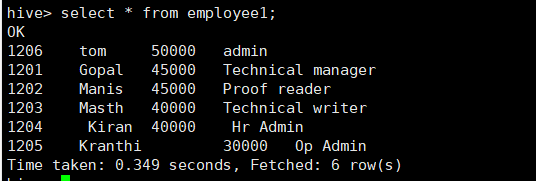
再次插入数据:
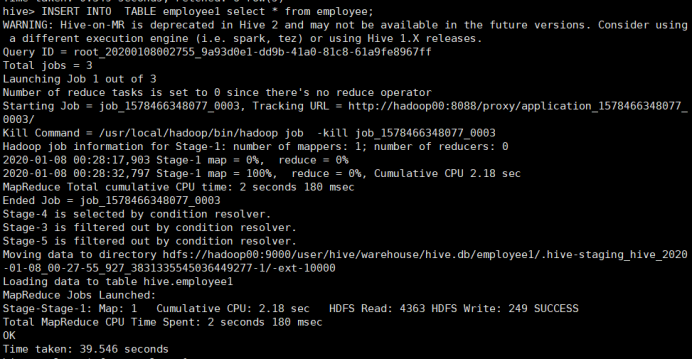
查询结果显示:
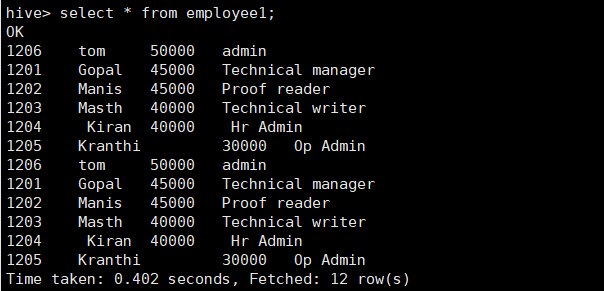
4.5.4 应用INSERT语句将查询结果覆盖数据表
应用INSERT语句将查询结果覆盖目的数据表
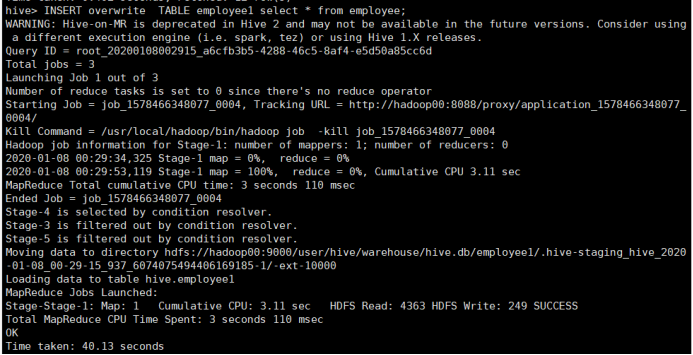
所使用命令:
# INSERT overwrite TABLE employee1 select * from employee;
查询结果显示:
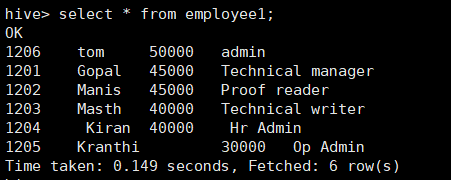
INSERT语句后跟overwrite将覆盖目的数据表的数据。
4.6 HiveQL:数据查询
4.6.1 基本的Select 操作
- 基本查询
查询employee表中数据:
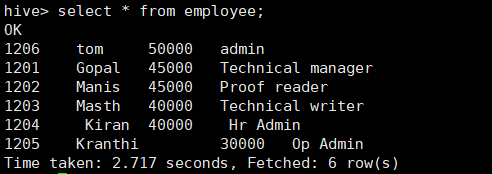
所使用命令:
# select * from employee;
或者
# select t.id,t.name,t.salary,t.position from employee t;
- limit
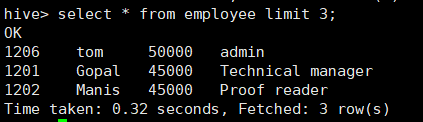
所使用命令:
# select * from employee limit 3;
- 区间查询between and
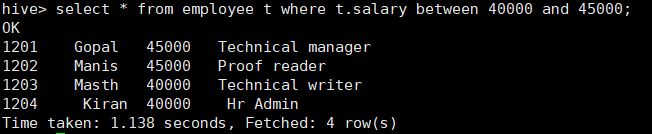
所使用命令:
# select * from employee t where t.salary between 40000 and 45000;
- 空查询is null

所使用命令:
# select t.id no,t.name,t.salary from employee t where t.id is null;
- 不空查询is not null
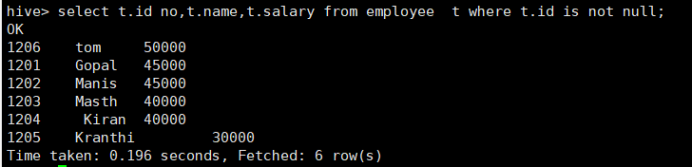
所使用命令:
# select t.id no,t.name,t.salary from employee t where t.id is not null;
- 集合查询in

所使用命令:
# select t.id no,t.name,t.salary from employee t where t.name in (‘tom’,’Gopal’);
- 不在集合范围内not in

所使用命令:
# select t.id no,t.name,t.salary from employee t where t.name not in (‘tom’,’Gopal’);
- 函数查询
最高工资max

所使用命令:
# select max(e.salary) from employee e;
最低工资min
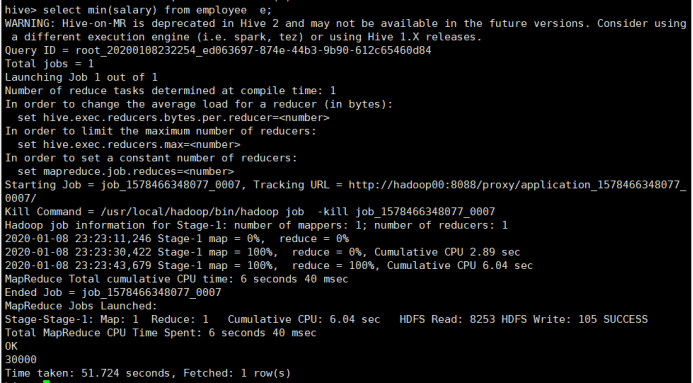
所使用命令:
# select min(salary) from employee e;
总人数count
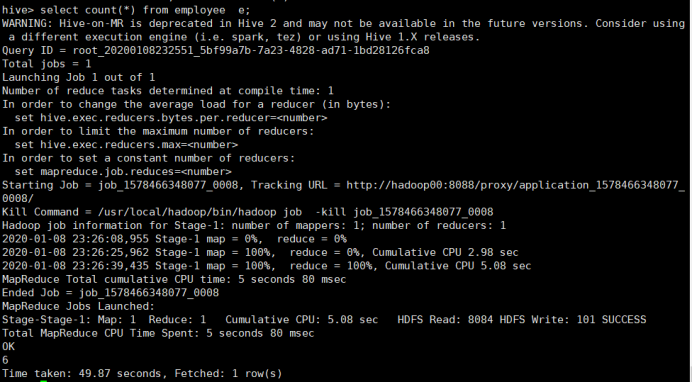
所使用命令:
# select count(*) from employee e;
公司月总支出sum
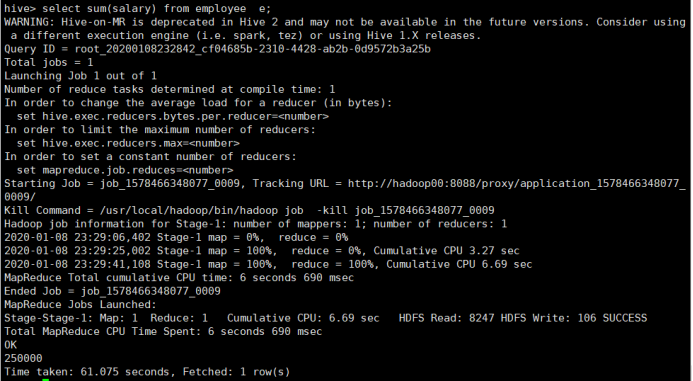
所使用命令:
# select sum(salary) from employee e;
平均工资avg
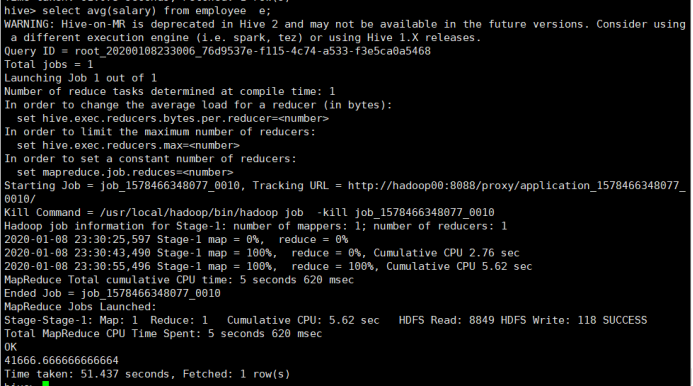
所使用命令:
# select avg(salary) from employee e;
- ORDER BY与SORT BY
ORDER BY的使用:
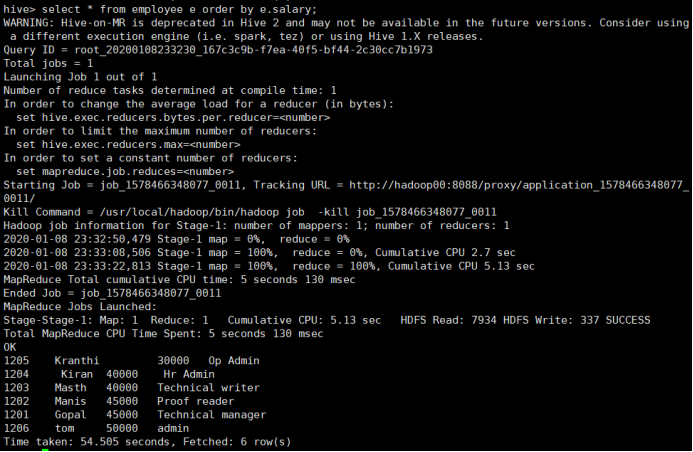
所使用的命令:
# select * from employee e order by e.salary;
SORT BY的使用:

# select * from employee e sort by e.salary;
4.6.2 基于分区的查询
加载数据到表分区,以第五章创建的表t为例。
1) 加载数据到分区
在/usr/local/data/文件夹下创建customer.txt文件,其内容为:

加载数据到分区:
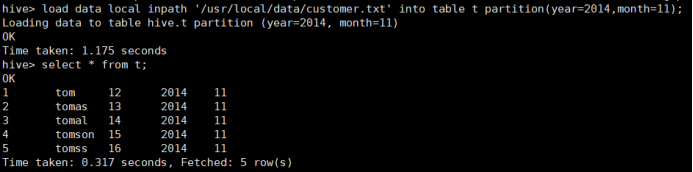
所使用命令:
# load data local inpath ‘/usr/local/data/customer.txt' into table t partition(year=2014,month=11);
查询结果:
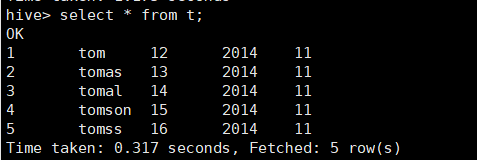
加载数据到分区(year=2014,month=12)和查询结果:
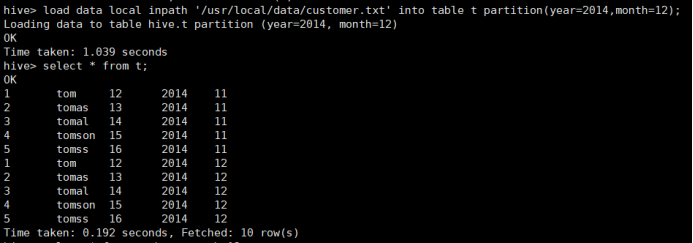
2) 基于分区的查询
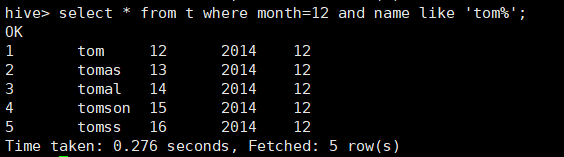
所使用命令:
# select * from t where month=12 and name like ‘tom%’;
4.6.3 基于Join的查询
两个表进行连接,例如有两个表m n ,m表中的一条记录和n表中的一条记录组成一条记录。
1) 实验准备:
/usr/local/data目录下创建两个数据文件:

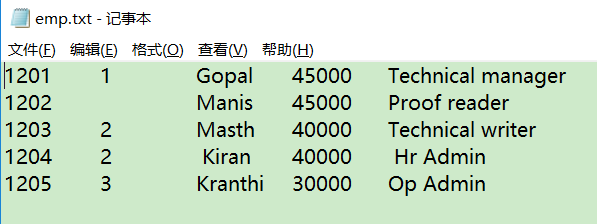
创建员工表和部门表:

所使用命令如下:
# create table emp (id int,depno int,name string,salary int,position string) row format delimited fields terminated by ' ' ;
# create table dep (id int,name string) row format delimited fields terminated by ' ' ;
导入数据:
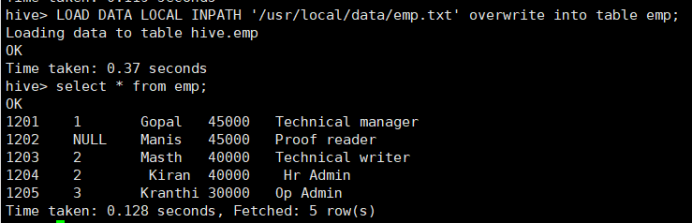
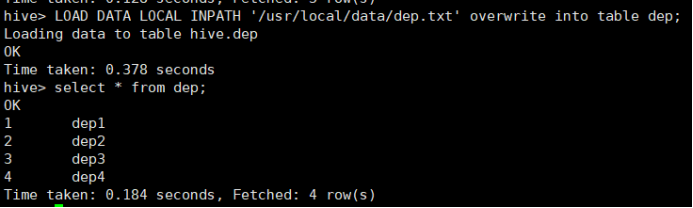
所使用命令如下:
# LOAD DATA LOCAL INPATH '/usr/local/data/emp.txt' overwrite into table emp;
# LOAD DATA LOCAL INPATH '/usr/local/data/dep.txt' overwrite into table dep;
2) join on :等值连接
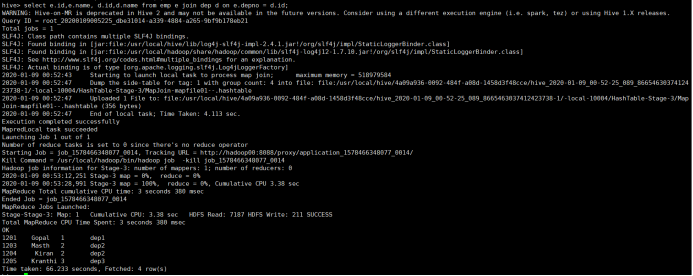
所使用命令:
# select e.id,e.name, d.id,d.name from emp e join dep d on e.depno = d.id;
3) left join:左连接
左连接表示以join左边数据为主,若join右边的数据不存在则补空。
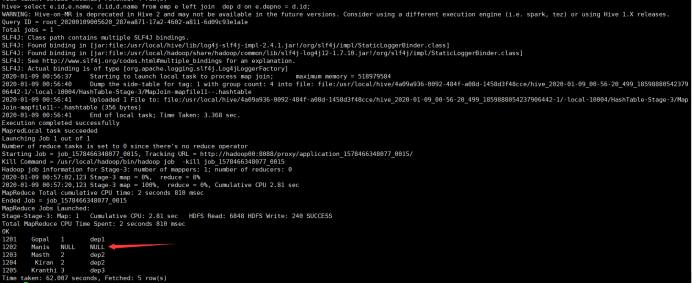
所使用命令:
# select e.id,e.name, d.id,d.name from emp e left join dep d on e.depno = d.id;
4) right join:右连接
右连接表示以join右边数据为主,若join左边的数据不存在则补空。
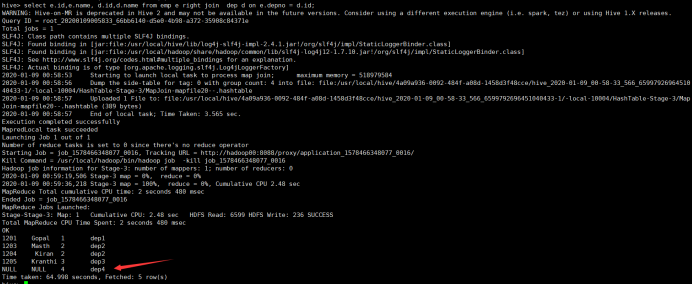
所使用命令:
# select e.id,e.name, d.id,d.name from emp e right join dep d on e.depno = d.id;