在Scrapy里面,Selectors 有四种基础的方法
xpath():返回一系列的selectors,每一个select表示一个xpath参数表达式选择的节点
css():返回一系列的selectors,每一个select表示一个css参数表达式选择的节点
extract():返回一个unicode字符串,为选中的数据
re():返回一串一个unicode字符串,为使用正则表达式抓取出来的内容
/html/head/title: 选择HTML文档<head>元素下面的<title> 标签。
/html/head/title/text(): 选择前面提到的<title> 元素下面的文本内容
//td: 选择所有 <td> 元素
//div[@class="mine"]: 选择所有包含 class="mine" 属性的div 标签元素
以上只是几个使用XPath的简单例子,但是实际上XPath非常强大。
可以参照W3C教程
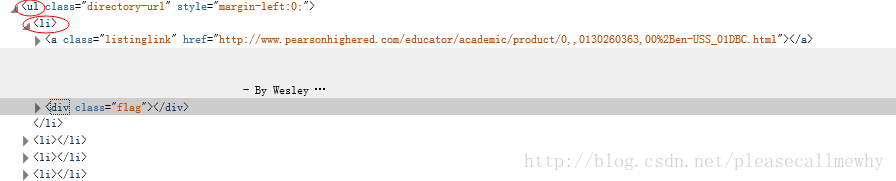
我们可以用如下代码来抓取这个<li>标签:
sel.xpath('//ul/li')
从<li>标签中,可以这样获取网站的描述:
sel.xpath('//ul/li/text()').extract()
可以这样获取网站的标题:
sel.xpath('//ul/li/a/text()').extract()
可以这样获取网站的超链接:
sel.xpath('//ul/li/a/@href').extract()