说明:
python这门语言在设计的时候,有一个全局解释器锁(GIL锁)这个就尴尬了,这个就导致了python的多线程都是伪多线程,也就是本质上还是一个线程
但是这个线程每个事情只做几毫秒,几毫秒以后就保存现场,换做其他事情,几毫秒以后再做其他事情,
微观上的单线程,宏观上就相当于同时,这个在(I/O)密集型上影响不大,但是在CPU密集型上影响很大,但是爬虫属于I/O密集型,所以采用多线程;
1,多进程的库(multiprocessing)
multiprocessing本身是python的多进程库,用来处理与多进程相关的操作。但是由于
进程和进程之间不能直接共享内存和堆栈资源,并且启用进程开销较大,因此使用多线程要比使用多进程来做爬虫更加具备优势,multiprocessing下面有个
dummy的模块,他可以让python的线程使用multiprocessing的各种方法。
dummy下面有个pool类来实现线程池。这个线程池有一个map方法
举个栗子:
# -*- coding:UTF-8 -*- __autor__ = 'zhouli' __date__ = '2018/10/27 23:06' from multiprocessing.dummy import Pool def calc(num): return num * num pool = Pool(3) orign_num = [x for x in range(100)] result = pool.map(calc, orign_num) print(result)
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81, 100, 121, 144, 169, 196, 225, 256, 289, 324, 361, 400, 441, 484, 529, 576, 625, 676, 729, 784, 841, 900, 961, 1024, 1089, 1156, 1225, 1296, 1369, 1444, 1521, 1600, 1681, 1764, 1849, 1936, 2025, 2116, 2209, 2304, 2401, 2500, 2601, 2704, 2809, 2916, 3025, 3136, 3249, 3364, 3481, 3600, 3721, 3844, 3969, 4096, 4225, 4356, 4489, 4624, 4761, 4900, 5041, 5184, 5329, 5476, 5625, 5776, 5929, 6084, 6241, 6400, 6561, 6724, 6889, 7056, 7225, 7396, 7569, 7744, 7921, 8100, 8281, 8464, 8649, 8836, 9025, 9216, 9409, 9604, 9801]
在上面的代码中,先定义了一个函数来计算平方,然后初始化了一个有3个线程的线程池,这三个线程负责计算10个数字的平方,谁先计算完谁就先取下一个数字计算,直到最后
map()方法第一个参数是函数的名字,第二个参数是一个列表(只要是可迭代对象都行),一定要注意的是函数的名字不带括号的!二,在可迭代对象中的每一个参数都会被函数
接收并作为参数。除了列表以外,字典,元祖,集合都是可以作为map()的第二个参数的。
注意:这个例子仅仅是说明多线程的使用方法,不涉及I/O操作,所以在GIL的影响之下,使用3个线程不会使代码运行时间小于单线程运行时间!
多进程,多线程的开启方式:
from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor from threading import currentThread import os,time,random def task(): print('name:%s pid:%s run' %(currentThread().getName(),os.getpid())) time.sleep(random.randint(1,3)) if __name__ == '__main__': pool=ThreadPoolExecutor(5) for i in range(10): pool.submit(task,) pool.shutdown(wait=True)
pool.shutdown(wait=True) 默认值为TRUE,这个是保证所有任务完成之后才能进行主进程
数据对比
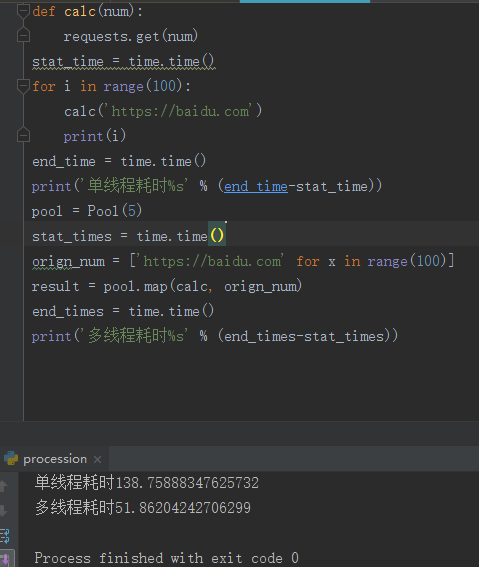 可以看到单线程和多线程之间的对比是非常的明显的
可以看到单线程和多线程之间的对比是非常的明显的
但这里不能说明线程池设置的越大越好,我们发现线程池所使用的时间要比单个线程所用时间的5分之一要多,这个多出来的时间就是线程切换所需要的时间,这个也是侧面反映了python的多线程其实就是串行的方式,因此如果线程池设置的过大的话,线程池切换所带来的开销可能抵消性能的提升!
xpath
之前写过关于xpath,不够简洁,总结一下:
获取文本:
//标签1[@属性1="属性值1"]/标签2[@属性2="属性值2"]/.../text()
获取属性值:
//标签1[@属性1="属性值1"]/标签2[@属性2="属性值2"]/.../@属性n
获取属性一某些字符串开头的:
//标签[start-with(@属性名,"相同的开头部分")]
例如 //div[start-with(@id,"test")]/text() 获取div标签下所有id开头以test开头的文本
获取属性包含某些字符串的:
例如 //div[contains(@id,"test")]/text() 获取div标签下所有id包含test的文本
目前,xpath不支持查找以XX结尾的情况,如果遇到这种情况,建议使用contains代替