一,自动化测试目前流行使用的是Selenium
安装方法pip install Selenium(默认安装最新的更新)
pip install Selenium==2.48.0(这个是指定版本号的安装)
卸载时pip uninstall Selenium
二,编写第一个自动化脚本


# -*- coding:UTF-8 -*- # 此处是为了防止中文乱码 当然也可以写成#coding=utf-8,等号两边不要有空格否则不起作用 __autor__ = 'zhouli' # 这些是在后台进行模板配置自动生成的 __date__ = '2018/6/17 12:02' from selenium import webdriver # 导入Selenium的Webdriver包,因为只有导入这个包才能使用Webdriver API进行自动化脚本的开发 driver = webdriver.Chrome() # 这句话是将Chrome这个对象赋值给driver driver.get("http://www.baidu.com") # 获得浏览器对象之后,通过get方法可以向浏览器发送网址(URl) # 关于页面元素的定位ID=kw,这个是定位到百度的输入框,并且通过键盘输入方法send_keys()像输入框输入Selenium搜索关键字 driver.find_element_by_id("kw").send_keys("Selenium2") # 这个一步是定位到ID=su,并且单击搜索按钮发送单击事件click() driver.find_element_by_id("su").click() # 关闭浏览器并且退出驱动程序 driver.quit()
这里必须要将Chrome的路径添加进path(默认已经添加)
在运行自动化脚本的时候,就会看到脚本启动Chrome并且进入百度输入selenium并且搜索。
三,WebDriver API
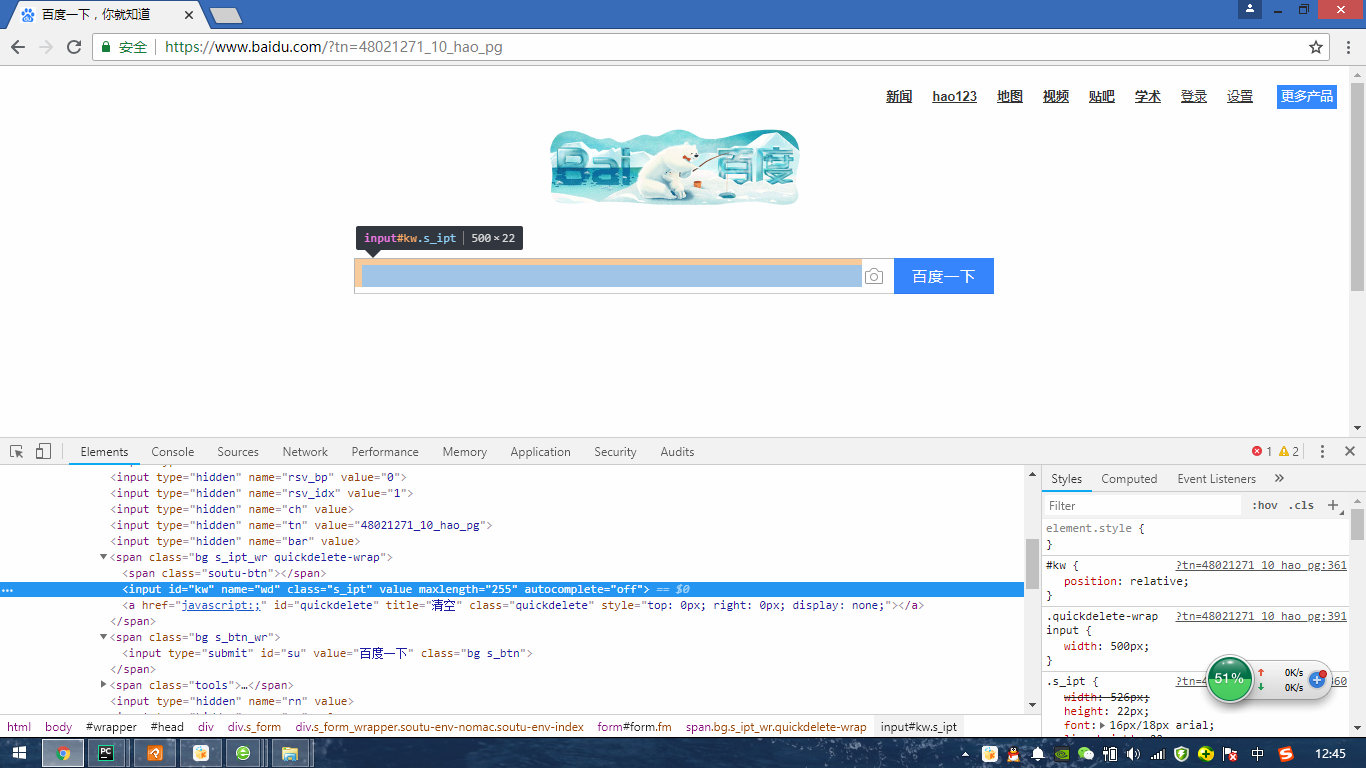
看到选中的那一行了吗?
id=“kw” name=“wd”
在下面的第四行,是不是有个id=“su”
这个就是webdriver提供的定位前端元素的方法,在python中对应如下:
① id→name
②class name →tag name
③link text → partial link text
④xpath →css selector
⑤find_element_by_id() → find_element_by_name()
⑥find_element_by_class_name() →find_element_by_tag_name()
⑦find_element_by_link_text() →find_element_by_partial_link_text()
⑧find_element_by_xpath() →find_element_by_css_selector()
(一)ID定位
HTML中规定的id属性在HTML文档中是必须唯一的,类似于现实世界的身份证号码。webdriver提供的id定位方法就是通过元素的id属性来查找元素,用法如下:
find_elenium_by_id("kw")
find_element_by_id("su")
find_element_by_id()方法通过id的属性来定位元素。
(二)NAME定位
HTML中规定name来指定原色的名称,因此他的作用更像是人的姓名。name的属性值在当前页面可以不唯一。通过name属性定位百度的输入框。
find_element_by_name("wd),大家看上面的图片,因为点击搜索的按钮并没有提供关于name的属性,所以我们并不能通过name属性来定位它。
(三)class定位
HTML中规定class赖志定元素的类名。其中的用法与id、name类似,下面通过class的属性定位百度的输入框和搜索按钮
find_element_by_class_name("s_ipt")
find_element_by_class_name("bg s_btn wr")
用find_element_class_name()方法获取class属性来定位元素
(四)tag定位
HTML的本质就是通过不同的tag定义实现不同的功能,每一个元素本质上就是一个tag。因为一个tag往往用来定义一类的功能,所以通过tag识别摸个元素的概率很低,所以一般不用。但如果非要用find_element_by_tag_name()
(五)link定位
link定位是专门用来定位文本链接,如下图:
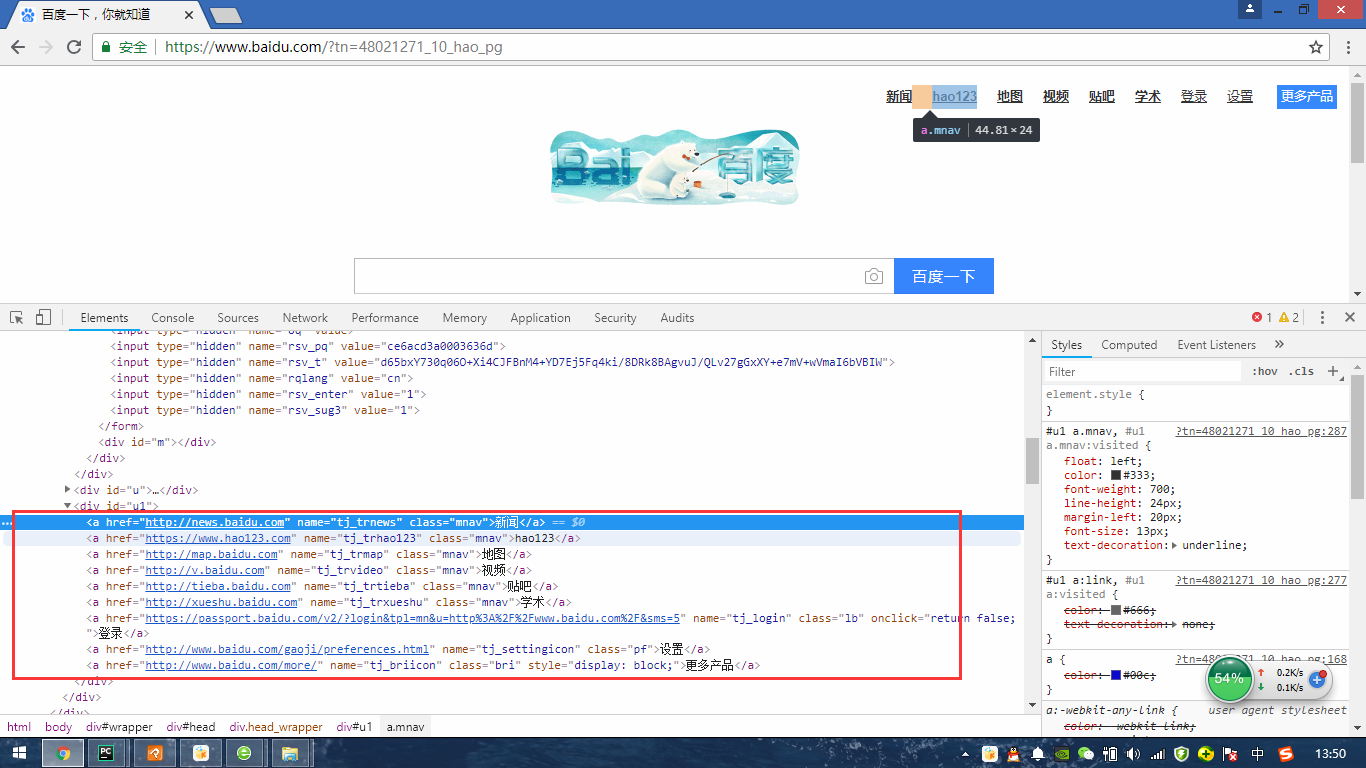
如图所示使用find_element_by_name()属性来定位完全可以做到
但是现在用link来定位
find_element_by_link_text("新闻")
find_element_by_link_text("hao123")
find_element_by_link_text("地图")
find_element_by_link_text("学术")
find_element_by_link_text("贴吧")
find_element_by_link_text("视频")
总结:find_element_by_link_text()来定位元素标签之间的文本信息实现定位。
(六)partial link定位
打个比方假如上图中<a>中的字,新闻 变成是 新闻答复都是男方家都是对的丰富的收到对方水电费
这个时候我们可以取到文本链接的一部分定位,只要部分信息就可以唯一标识这个链接
find_element_by_partial_link_text(“对方水电费”)
或者
find_element_by_partial_link_text(“都是对的丰富”)
总结:
前面介绍的几种方法比较简单,总结起来都是finf_element_by_+……
在一个页面当中每一个唯一id和name属性值,我们可以通过以上的方法找到它们,假如一个元素没有id,name属性,或者页面上多个元素id和name属性值相同,又或者是,每次刷新页面id就会随机变化,这些情况下,怎么定位?
……………………………………………………………………分割线………………………………………………………………2018-06-19
xpath定位:
xpath是一种在xml文档中定位元素的语言。因为HTML可以看做xml的一种实现。
绝对路径定位:xpath有多种定位策略,直观的就是直接定位出元素的绝对路径。
参照第一张截图:用下面这种方式来定位到百度输入框和搜索按钮。
find_element_by_xpath("/html/body/div/div[2]/div/div/div/from/span/input")
find_element_by_xpath("/html/body/div/div[2]/div/div/div/from/span[2]/input")
首先来了解一下xpath的定位规则:
①xpath主要是用标签名的层级关系来定位元素的绝对路径的,最外层为html语言,在body文本中按照层级往下进行,假如一个层级之下有多个相同的标签名称,那么按照从上而下的顺序来确定第几个,就像/div[2]和/span[2]一样就是代表当前层级下第二个标签。
②xpath可以使用元素的属性值定位。还是以第一张图的输入框和搜索框为例:
find_element_by_xpath("//input[@id='kw']")
find_element_by_xpath("//input[@id='su']")
//表示在当前的目录下,input表示当前定位元素的标签名。[@id='kw']表示这个元素的id为kw,当然也可以通过name和class属性值来进行定位。
find_element_by_xpath(“//input[@name='wd']”)
find_element_by_xpath(“//input[@class='s_ipt']”)
find_element_by_xpath(“//*[@class='bg s_btn']”)
如果不想指定标签名,则可以用*代替。当然,使用XPATH不局限id、name和class这三个属性值。元素的任意属性值都可以使用,只要他能唯一标志的元素。
find_element_by_xpath("//input[@maxlength='100']")
find_element_by_xpath("//input[@autocomplete='off']")
find_element_by_xpath("//input[@type='submit']")
层级与属性结合
如果一个元素本身没有唯一标志这个元素的属性值,那么我们可以找其上一级元素,如果他的上一级元素又可以唯一标识属性的值,也可以拿出来使用,参考baidu.html
文本

假如百度输入框本身没有可以利用的属性,那么我们可以检查它的上一级的属性,就好比新生儿出生没有名字,那怎么认定这个孩子呢,那么就先叫他爸爸的儿子
那就知道准确定位到这个新生儿
find_element_by_xpath("//span[@class='bg s_ipt_wr']/input")
span[@class='bg s_ipt_wr']通过class属性定位到父元素,后面/input就表示父元素下面的子元素。如果父元素没有可以可利用的属性值,那么可以继续向上查找爷爷元素。
find_element_by_xpath("//from[@class='bg s_ipt_wr']/span/input")
find_element_by_xpath("//from[@class='bg s_ipt_wr']/span[2]/input")
我们可以通过这种方法一级一级向上查找,直到找到最外层的<html>标签,这就是一个绝对路径的轻松写法。
使用逻辑运算符
如果一个属性不能唯一区分一个元素,我们还可以使用逻辑运算符连接多个属性来查找元素。
<iinput id="kw" class="su" name="ie"> <iinput id="kw" class="aa" name="ie"> <iinput id="bb" class="su" name="ie">
就像上面的三行元素,假设我们现在要去定位到第一行的元素,如果使用id定位会和第二行元素重名,如果使用class属性的话会和第三行重名,如果使用id和class联合起来的就可以唯一标识这个元素,这个时候就用and来连接这两个条件。
find_elemengt_by_xpath("//input[@id='kw' and @class=‘su’]/span/input")
当然and可以连接更多的属性来唯一标识这个元素。
当然Chrome自带识别,如下图:
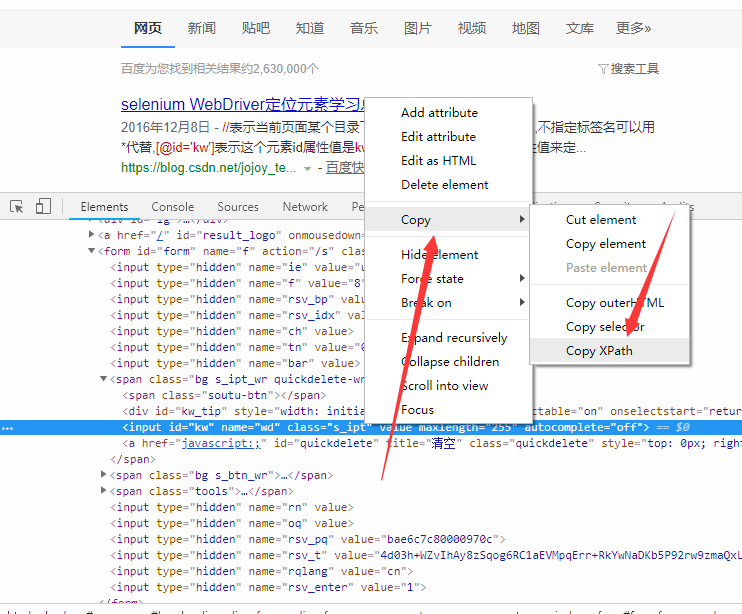 这个是Chrome自带的
这个是Chrome自带的
点击即可获取到xpath的语法,然后find_element_by_xpath(“粘贴到此处”)
赶紧去试试,我是不是在蒙你。