Elasticsearch默认安装后设置的内存是1GB,对于生产环境来说,这个配置太小了。如果生产环境使用默认堆内存配置,elasticsearch节点可能很快产生问题。
我们可以通过修改elasticsearch配置文件(es_home/config/jvm.options)
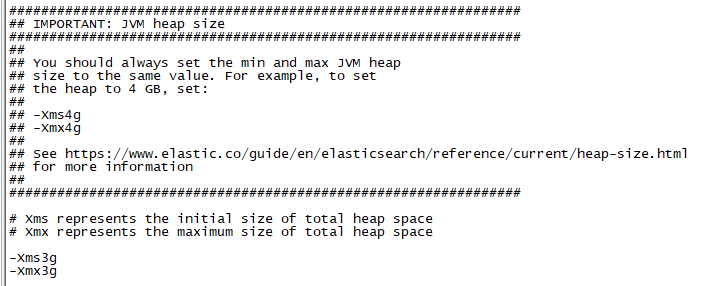
注:需要确保Xmx和Xms的大小一致,防止java立即回收机制清理完堆空间后重新分隔计算堆空间的大小而浪费资源,可以减轻伸缩堆大小带来的压力
一般将50%的内存分给堆空间(不超过32G),剩下的50%会被lucence用于文件缓存
这里有另外一个原因不分配大内存给Elasticsearch,事实上jvm在内存小于32G的时候会采用一个内存对象指针压缩技术。
在java中,所有的对象都分配在堆上,然后有一个指针引用它。指向这些对象的指针大小通常是CPU的字长的大小,不是32bit就是64bit,这取决于你的处理器,指针指向了你的值的精确位置。
对于32位系统,你的内存最大可使用4G。对于64系统可以使用更大的内存。但是64位的指针意味着更大的浪费,因为你的指针本身大了。浪费内存不算,更糟糕的是,更大的指针在主内存和缓存器(例如LLC, L1等)之间移动数据的时候,会占用更多的带宽。
Java 使用一个叫内存指针压缩的技术来解决这个问题。它的指针不再表示对象在内存中的精确位置,而是表示偏移量。这意味着32位的指针可以引用40亿个对象,而不是40亿个字节。最终,也就是说堆内存长到32G的物理内存,也可以用32bit的指针表示。
一旦你越过那个神奇的30-32G的边界,指针就会切回普通对象的指针,每个对象的指针都变长了,就会使用更多的CPU内存带宽,也就是说你实际上失去了更多的内存。事实上当内存到达40-50GB的时候,有效内存才相当于使用内存对象指针压缩技术时候的32G内存。
这段描述的意思就是说:即便你有足够的内存,也尽量不要超过32G,因为它浪费了内存,降低了CPU的性能,还要让GC应对大内存。
当有一个大内存的机器时:
首先,我们建议编码使用这样的大型机
其次,如果你已经有了这样的机器,你有两个可选项:
-
你主要做全文检索吗?考虑给Elasticsearch 32G内存,剩下的交给Lucene用作操作系统的文件系统缓存,所有的segment都缓存起来,会加快全文检索。
-
你需要更多的排序和聚合?你希望更大的堆内存。你可以考虑一台机器上创建两个或者更多ES节点,而不要部署一个使用32+GB内存的节点。仍然要 坚持50%原则,假设 你有个机器有128G内存,你可以创建两个node,使用32G内存。也就是说64G内存给ES的堆内存,剩下的64G给Lucene。
如果你选择第二种,你需要配置cluster.routing.allocation.same_shard.host:true。这会防止同一个shard的主副本存在同一个物理机上(因为如果存在一个机器上,副本的高可用性就没有了)。