1. 简单来讲,就是通过软件访问目标网站,把目标网站上指定的信息获取到,一切都是通过软件实现。
例如,如果想获取豆瓣网上,评分最靠前的250个影片的名称,而不用人工去写,可以参考下面的博客。
http://www.cnblogs.com/huangguifeng/p/7632799.html
2. 基本思路是,通过python代码,掌握豆瓣前250名影片的html的规律。
例如:第一页是:
第二页是:
第三页是:
可以看出基本规律是,每页显示25条,250条就是10页,对应代码如下:

3. 访问每一页,获取http的返回结果,通过解析html文本内容,得到得分和电影名称。
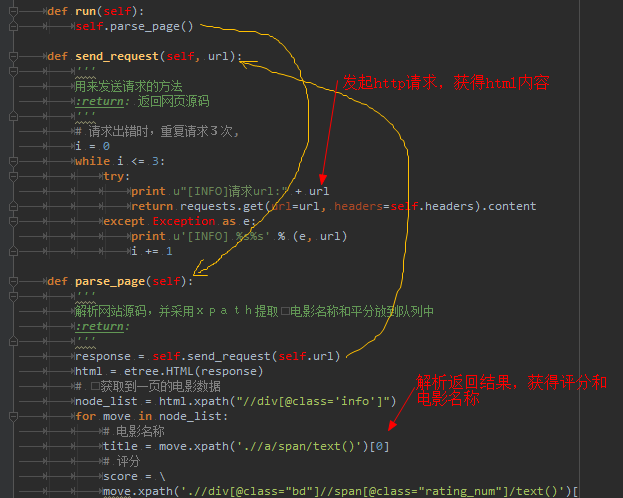
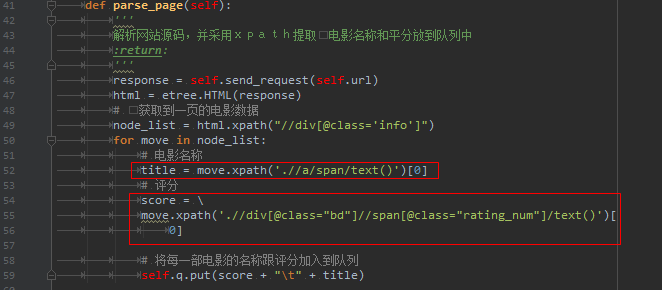
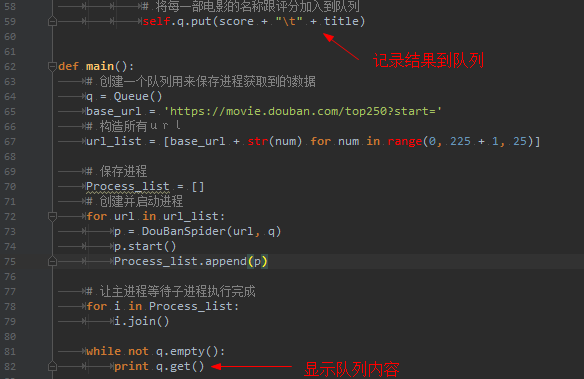
4. 期间,通过队列这种数据结构,将每页的解析结果记录到队列中,最后一次性显示队列内容。