一、python2和python3区别
python2和python3区别:https://www.cnblogs.com/weikunzz/p/6857971.html
1)print 语句区别
python2:print是个class,所以可以不用加括号,print 1,2+3
python3:print是个内置函数,必须加括号,print(1,2+3,end=" ")
2)input区别
python2:input输入的是int类型,raw_input输入是str类型
python3:input输入的是str类型,没有raw_input
另外几种输入方法:
a)sys.stdin.readlines() 输入最后包含' '
b)input().split()-------->map(int,input().split()) python2:返回的是列表 python3:返回的是迭代器
3)整除
python2:print 1/2 得0
python3:print (1/2) 得0.5 print(1//2) 得0
4)range和xrange
python2:range返回的列表,xrange返回的是class xrange,用于for循环
python3:range返回的是class range, 用于for循环, 想要列表使用list(range(0,4))
5)try except
python2:


try: ...... except Exception,e: ......
python3:
try: ...... except Exception as e: ......
6)编码
这一篇内容写的很好:Python问题编码大终结:https://www.cnblogs.com/vipchenwei/p/6993788.html
首先清楚几个问题:
1、 编码和编码方式
编码是字符集,编码方式是从字符集的实现,有gbk,utf-8,ascii等等
python2的字符串类型:unicode和str,不区分str和bytes的,如果开头写# -*- coding:utf8 -*- 按照utf8读写文件,以及字符串也默认按照这个编码,否则默认按照ascii编码
x='abc' 这里abc按照ascii编码的str # -*- coding:utf8 -*- x='abc' 这里abc按照utf8编码
python3的编码:str和bytes类型,str默认是unicode字符集,bytes是str的实现,可以是gbk,utf8,utf16,utf32
2.编码和解码
编码:把字符串变成二进制(明文-------->密文)
解码:把二进制变成字符串(密文-------->明文)
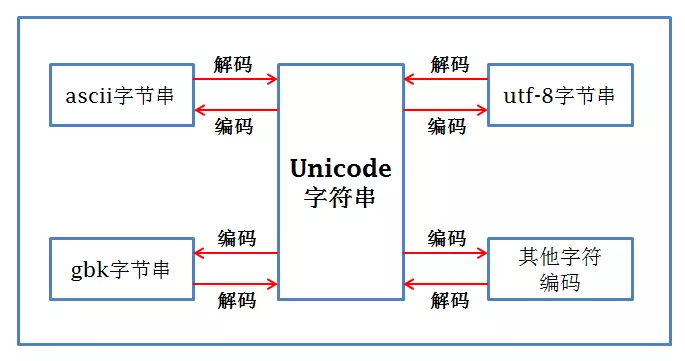
python2可以从任何一个地方带入字符串,如果从ascii,utf8,gbk,其他字符编码的时候,要先解码成Unicode,然后在encode成其他字符串编码
python3默认从Unicode进入,所以直接可以encode成其他编码
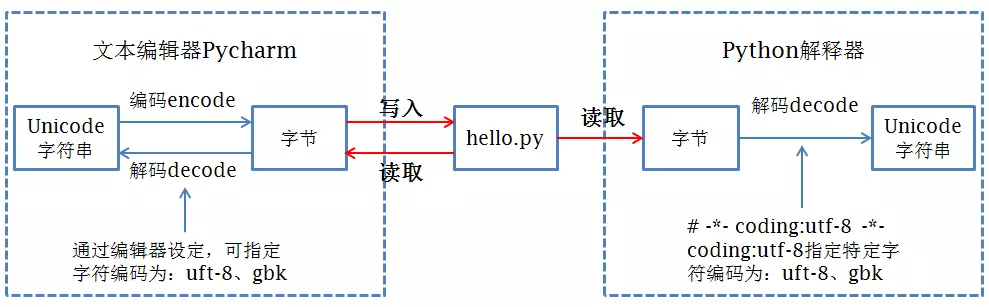
3.文件编码和解码
文件编码:就是把在文档编辑器的文档保存到硬盘,windows默认是gbk,linux默认是utf8,可以通过locale查看,
文件解码:把文件从硬盘读到内存,按照什么方法读,就是解码方式
解释器解码:和文件解码一致,python2默认是ascii,python3默认utf8
一般来说解码和编码方式要一致,否则容易乱码或者错误
print("中")
#python2中,如果保存之后执行,不加# -*- coding:utf8 -*- 的情况下会报错, 文件编码(保存)是按照utf8或者gbk编码成二进制,但是执行时候按照ascii,没有相对应字符,所以出错
#python3中,“中”是unicode字符,保存按照utf8,打开执行正常(默认utf8解码),如果按照gbk保存,打开则会报错,但是加上# -*- coding:gbk -*-,就会正常执行
#所以编码和解码尽量一致,python中尽量都表明用utf8存储
4.输出到屏幕
这个是内存到内存的转换,所以编码错乱会乱码或者报错
python2:没有bytes,所以转为utf8的仍然是字符串,想看二进制码用repr
python3:只有bytes,所以转为utf8之后是二进制码,想看字符串,在decode回去
python2
# -*- coding:gbk -*- s_gbk = "周" s_utf8 = s_gbk.decode('gbk').encode('utf8') s_unicode = s_gbk.decode('gbk') print("s_utf8: " + s_utf8) #s_utf8: 鍛 utf8输出到cmd,cmd编码方式是gbk,所以乱码 print("s_gbk: " + s_gbk) #s_gbk: 周 print("s_unicode: " + s_unicode) #s_unicode: 周 #文件保存要用gbk或者ansi
python3:
# -*- coding:gbk -*- s_unicode = "zgl周广露无敌" s_gbk = s_unicode.encode('gbk') s_utf8 = s_unicode.encode('utf8') print(s_utf8) #b'zglxe5x91xa8xe5xb9xbfxe9x9cxb2xe6x97xa0xe6x95x8c' print(s_gbk) #b'zglxd6xdcxb9xe3xc2xb6xcexdexb5xd0' print(s_unicode) #zgl周广露无敌
二、命名方式
1)变量命名
- 变量名只能包含数字,字母和下划线_,不能以数字开头
- 不能以关键字作为变量,关键字如下:
and, del, from, not, while, as, elif, global, or, with, assert, else, if, pass, yield, break, except, import, print, class, exec, in, raise, contiue, finally, is, return, def, for, lambda, try
关键字查询:
import keyword print(keyword.kwlist) # 查看关键字 keyword.iskeyword('as') # 查看as是否是关键字
2)命名规范
python命名规范:https://www.cnblogs.com/EmptyRabbit/p/7679093.html
- module_name, 模块
- package_name, 包
- ClassName, 类
- method_name, 方法
- ExceptionName, 异常
- function_name, 函数
- GLOBAL_VAR_NAME, 全局变量
- instance_var_name, 实例
- function_parameter_name, 参数
- local_var_name. 本变量
3)代码规范
代码规范:https://www.cnblogs.com/JZ-Ser/p/7056332.html
三、三种结构
1)顺序结构
2)分支结构
#单分支结构 if <判断条件>: <语句块> #双分支结构 if <判断条件>: <语句块> else: <语句块> #多分支结构 if <判断条件>: <语句块> elif <判断条件>: <语句块> else: <语句块>
竟然没有switch......case......语句
3)循环结构
#while 循环 while <判断语句>: <语句块> #while-else 循环,执行完while,执行else while <判断语句>: <语句块> else: <语句块> #for循环 for i in range(0,4): <语句块> for i in 列表|元祖: <语句块> #for-else循环 for i in range(0,4): <语句块> else: <语句块>
- continue 结束当前循环,继续执行下一次循环(后续代码块不被执行)
- break 跳出并结束整个循环,执行循环后的语句。当有多层循环,使用循环嵌套时,仅能跳出一层循环
注意事项:
- 对于for和while,不算子程序,在里面赋值也不是局部变量,是全局变量
for i in range(2): print("x") x = 3 print(i) #1 print(x) #3 while True: y = 2 break print(y) #2
print(globals())##。。。。。。。。。。。。'i': 1, 'x': 3, 'y': 2}


