一、HMM模型
1.HMM模型的原理?
马尔科夫假设:当前状态仅与上一个状态有关;
观测独立性假设: 任意时刻的观察状态仅仅依赖于当前时刻的隐藏状态
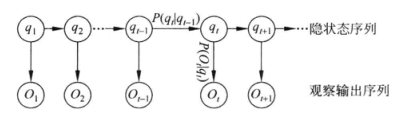
图中Q是状态序列,O是观察序列
举例:词性标注【我爱美丽的中国】
状态集合S={名词N,动词V,形容词A}
状态序列Q={N,V,A}
转移矩阵aij :
N V A
N 0.1 0.2 0.7
V 0.2 0.7 0.1
A 0.7 0.2 0.1
输出观察序列O={N,V,A,N}
求P(O) = P(N)*p(V|N)*P(A|V)*P(N|A)

2.隐状态是什么含义?
模型的状态转换过程是不可观察的,可观察事件是状态的随机函数。
3.三个基本问题?
概率计算问题:前向算法,后向算法 --> 求观察序列O的概率
预测问题:维特比算法-->求解最优路径Q
学习问题:loss函数,最大似然估计-->训练模型参数,如何调节模型(A,B,u)的参数使得P(O|u)最大化
二、CRF模型
1.CRF模型的原理?
(1)假设满足马尔可夫性:当前状态与前一个和后一个状态及观测序列(有线相连的节点)有关,与其他状态无关;
(2)无观测独立性假设;
(3)由于限制更少,CRF利用了更多的信息,如观测序列上下文信息,以及观测序列元素本身的特征(是否是数字,是否大写,是否以某字符串开头或结尾)
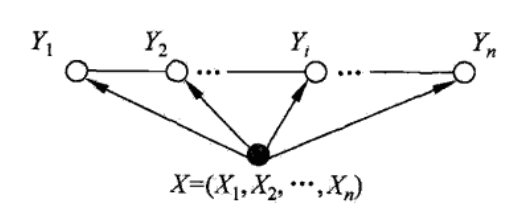
图中Y是输出标注状态序列,X是输入文本的观察序列
举例:词性标注【我爱美丽的中国】
Y = {N,V,A,N}
X = {我,爱,美丽的,中国}
求条件概率P(Y|X)
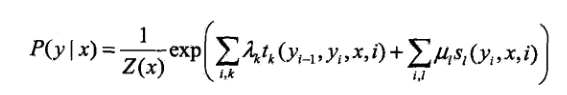
t(y,x,i)是转移函数,表示标注序列Y在i及i-1位置上标记的转移概率。
s(y,x,i)是状态函数,表示观察序列X在i位置的标记概率。
lamda和u分别是各自的权重。
三、综合比较
(1)HMM与CRF都具有三个基本问题:概率计算问题,预测问题,学习问题
(2)CRF没有HMM的独立性假设的严格要求,对序列内部信息和外部观察信息都可以有效利用,避免了标注偏置的问题。
(3)对于概率计算问题,HMM是模拟参数的随机分布,而CRF是求解问题的特征函数。