之前在centos7安装hadoop2.2.0集群-环境准备及centos7安装hadoop2.2.0集群-软件安装中讲过从最开始的环境准备及软件安装,从设置hostname到jdk的安装都没有问题,只是在这里重新回顾一下完整版的hadoop安装,验证过的,比较靠谱一点。
因为之前jdk安装之前的都没有问题,所以这里只讲hadoop的安装。
1、首先下载hadoop压缩包,hadoop-2.2.0.tar.gz,解压到安装目录下(自己定),然后设置环境变量,如下:
export HADOOP_HOME=/export/servers/hadoop-2.2.0
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
export PATH=$JAVA_HOME/bin:JRE_HOME/bin:$HADOOP_HOME/bin:$PATH
2、修改配置文件,hadoop2.2的配置文件目录是$HADOOP_HOME/etc/hadoop,主要修改的有以下几个配置文件:
core-site.xml:(后两项是设置oozie的代理)
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop-master</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/export/data/hadoop_tmp</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
</configuration>
hadoop-en.sh:
在文件末尾添加java安装目录,例如:export JAVA_HOME=/usr/local/java/jdk1.7.0_71
hdfs-site.xml:
<configuration>
<property>
<name>dfs.nameservices</name>
<value>ns1</value>
<description>Logical name for this newnameservice</description>
</property>
<property>
<name>dfs.ha.namenodes.ns1</name>
<value>nn1</value>
<description>Unique identifiers for each NameNode in the nameservice</description>
</property>
<property>
<name>dfs.namenode.rpc-address.ns1.nn1</name>
<value>hadoop-master:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.ns1.nn1</name>
<value>hadoop-master:50070</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>--注释:子节点的个数,超出会报错
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/export/data/nn</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/export/data/dfs</value>
</property>
</configuration>
mapred-env.sh:
在文件末尾添加Java安装目录,同上。
mapred-site.xml:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop-master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop-master:19888</value>
</property>
<property>
<name>mapreduce.map.output.compress</name>
<value>false</value>
</property>
<property>
<name>mapreduce.map.output.compress.codec</name>
<value>org.apache.hadoop.io.compress.GzipCodec</value>
</property>
<property>
<name>yarn.app.mapreduce.am.staging-dir</name>
<value>/user</value>
</property>
</configuration>
slaves文件:
hadoop-slave
yarn-env.sh:
在文件末尾添加Java安装目录,同上。
yarn-site.xml:
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>hadoop-master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>hadoop-master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>hadoop-master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>hadoop-master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>hadoop-master:8088</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>/export/data/yarn/logs</value>
</property>
<property>
<name>yarn.nodemanager.log.retain-seconds</name>
<value>86400</value>
</property>
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/tmp/app-logs</value>
</property>
<property>
<name>yarn.nodemanager.remote-app-log-dir-suffix</name>
<value>logs</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
</property>
<property>
<name>yarn.scheduler.fair.allocation.file</name>
<value>/export/servers/hadoop-2.2.0/etc/hadoop/fair-scheduler.xml</value>
</property>
<property>
<name>yarn.scheduler.assignmultiple</name>
<value>true</value>
</property>
<property>
<name>yarn.scheduler.fair.allow-undeclared-pools</name>
<value>false</value>
</property>
<property>
<name>yarn.scheduler.fair.locality.threshold.node</name>
<value>0.1</value>
</property>
<property>
<name>yarn.scheduler.fair.locality.threshold.rack</name>
<value>0.1</value>
</property>
</configuration>
以上,配置已经完成,现在启动hadoop,第一次启动需要初始化:
hdfs namenode -format
进入$HADOOP_HOME/sbin目录,sh start-all.sh
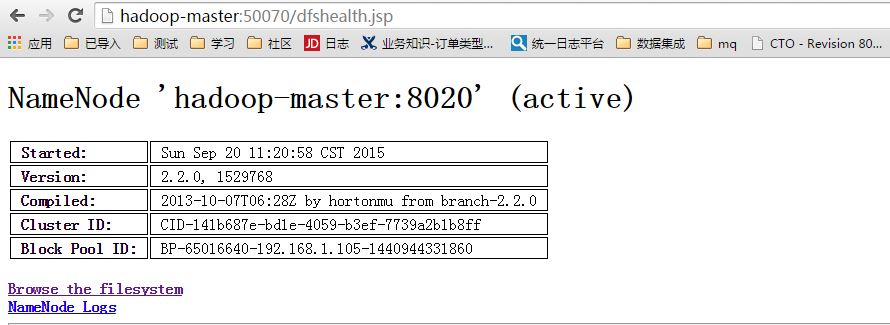
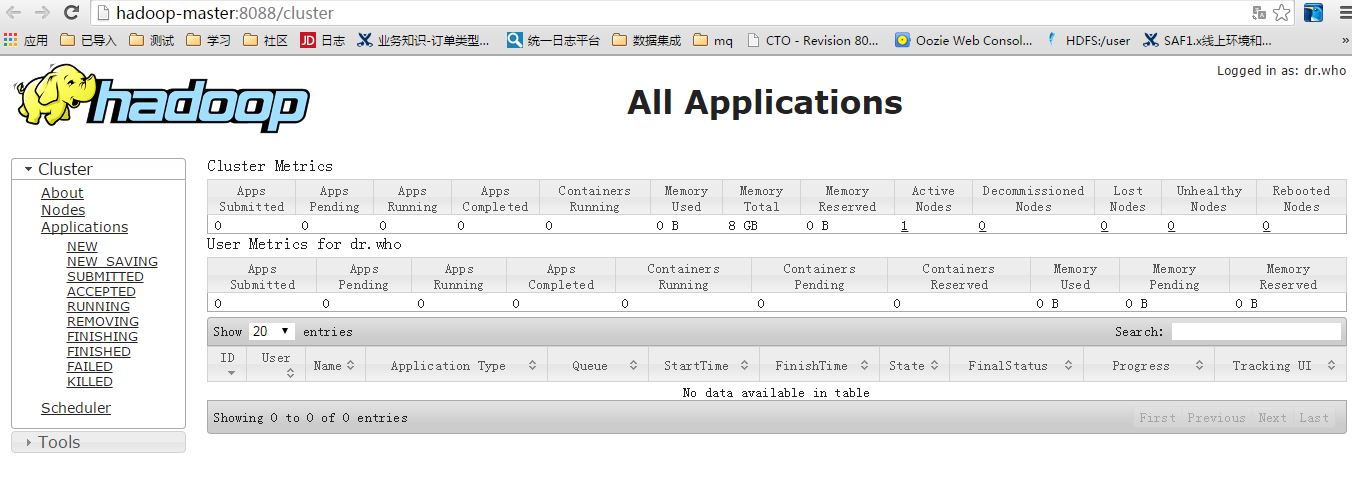
启动后,在浏览器输入以下地址测试,如图表示启动成功:
http://hadoop-master:8088
http://hadoop-master:50070