Note that if you're interested in learning about Oracle Database 12c, there's an updated version of this post here.
When it comes to gathering statistics, one of the most critical decisions you have to make is, what sample size should be used? A 100% sample will ensure accurate statistics but could take a really long time. Whereas a 1% sample will finish quickly but could result in poor statistics.
The ESTIMATE_PERCENT parameter in the DBMS_STATS.GATHER_*_STATS procedures controls the sample size used when gathering statistics and its default value is AUTO_SAMPLE_SIZE.
In an earlier blog post, we talked about the new implementation of AUTO_SAMPLE_SIZE in Oracle Database 11g in terms of its improvements in the speed and accuracy of statistics gathering compared to the old AUTO_SAMPLE_SIZE prior to Oracle Database 11g.
In this post, we will offer a closer look at the how the new AUTO_SAMPLE_SIZE algorithm works and how it affects the accuracy of the statistics being gathered.
Before we delve into how the new algorithm works, let us briefly recap how the old algorithm works and its downsides. The old AUTO_SAMPLE_SIZE used the following approach:
Step 1. Oracle starts with a small sampling percentage. If histograms need to be gathered, Oracle might materialize the sample, depending on the sampling percentage.
Step 2. Oracle gathers basic column statistics on the sample. For example, suppose a table T has only one column C1, then the basic stats gathering query looks like below (this is not the exact syntax we use but a simplified version for illustration purpose):
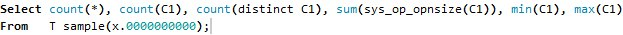
Query 1 Query Gathering Basic Column Statistics Using AUTO_SAMPLE_SIZE Prior to 11g
The select list items in the query correspond to number of rows in table T, number of non-null values, number of distinct values, total column length, minimal and maximal values of column C1respectively. “X.0000000000” in the FROM clause is the sampling percentage determined by Oracle.
Step 3: if histograms need to be gathered, Oracle issues a SQL query on the sample for each column that requires a histogram.
Step 4: For each column that requires a histogram, Oracle uses several metrics to determine whether the current sample is sufficient:
- Non-null value metric: Whether the sample contains sufficient non-null values of this column;
- NDV metric: Whether number of distinct values (NDV) can be properly scaled from the sample.
Step 5: If all metrics in step 4 pass, Oracle concludes that the current sample size is sufficient and the histogram creation for that column is complete. Otherwise, it bumps up the sample size and goes though the above steps again until it finds a satisfactory sample or reaches 100% sampling.
Note that step 3 to step 5 are done per column. For example, if there are 3 columns in the table that require histograms. In the first iteration, we get a sample and materialize it. We issue 3 queries, one per column, on the same materialized sample to gather histograms. Suppose Oracle determines that the sample is sufficient for columns 1 and 2 but insufficient for column 3. Then we bump up the sample size. In the second iteration, only 1 query is issued on the sample to gather histogram for column 3.
As you can see the old AUTO_SAMPLE_SIZE can be inefficient if several iterations are required. A dominating contributor for several iterations is the inability to gather accurate NDVs using a small sample. If there is a skew in the data, a lot of low frequency values may not make into the sample and thus the sample fails the NDV metric.
In Oracle Database 11g, we use a completely different approach for gathering basic column statistics. We issue the following query to gather basic column statistics (again this is a simplified version for illustration purpose).

You will notice in the new basic column statistics gathering query, no sampling clause is used. Instead we do a full table scan. Also, there is no more count(distinct C1) to gather NDV for C1. Instead, during the execution we inject a special statistics gathering row source to this query. The special gathering row source uses a one-pass, hash-based distinct algorithm to gather NDV. More information on how this algorithm works can be found in the paper, “efficient and scalable statistics gathering for large databases in Oracle 11g”. The algorithm requires a full scan of the data, uses a bounded amount of memory and yields a highly accurate NDV that is nearly identical to a 100 percent sampling (can be proven mathematically). The special statistics gathering row source also gathers the number of rows, number of nulls and average column length on the side. Since we do a full scan on the table, the number of rows, average column length, minimal and maximal values are 100% accurate.
AUTO_SAMPLE_SIZE also affects histogram gathering and index statistics gathering in the following ways.
Effect of auto sample size on histogram gathering
- With the new AUTO_SAMPLE_SIZE, histogram gathering is decoupled from basic column statistics gathering (they used to be gathered on the same sample). Therefore when determining whether we need to bump up the sample size, the new AUTO_SAMPLE_SIZE algorithm no longer performs the “NDV metric” check (see step 4 in above description) because we do not derive NDV from the sample. Sample size needs to be bumped up for a histogram only when the sample contains too many nulls or too few rows. This helps to reduce number of iterations of the histogram creation. More information on this can be found in this blog post.
- If the minimal (resp. maximal) value that appears in the sample used for gathering the histogram is not the minimal (resp. maximal) value gathered in basic statistics, we will modify the histogram so that the minmal (resp. maximal) value gathered in basic statistics now appears as the endpoint of the first (resp. last) bucket in the histogram.
Effect of auto sample size on index stats gathering
The new AUTO_SAMPLE_SIZE also affects how index statistics are gathered. The flow chart below shows how index statistics are gathered in 11g when AUTO_SAMPLE_SIZE is specified. Index statistics gathering are sampling based. It could potentially go through several iterations because either the sample contained too few blocks or the sample size was too small to properly gather number of distinct keys (NDKs). With the new AUTO_SAMPLE_SIZE algorithm, however, if the index is defined on a single column, or if the index is defined on multiple columns that correspond to a column group, then the NDV of the column or column group will be used as NDK of the index. The index statistics gathering query will NOT gather NDK in such cases. This helps to alleviate the need to bump up sample size for index statistics gathering.

Summary:
- New AUTO_SAMPLE_SIZE algorithm does a full table scan to gather basic column statistics
- NDV gathered by new AUTO_SAMPLE_SIZE has an accuracy close to 100% sampling
- Other basic column statistics, such as the number of nulls, average column length, minimal and maximal values have an accuracy equivalent to 100% sampling
- Both Histogram and index statistics gathering under new auto sample size algorithm still use sampling. But new auto sample size algorithm helps to alleviate the need to bump up sample size.