作者:金戈戈
链接:https://www.zhihu.com/question/30643044/answer/48955833
来源:知乎
著作权归作者所有,转载请联系作者获得授权。
链接:https://www.zhihu.com/question/30643044/answer/48955833
来源:知乎
著作权归作者所有,转载请联系作者获得授权。
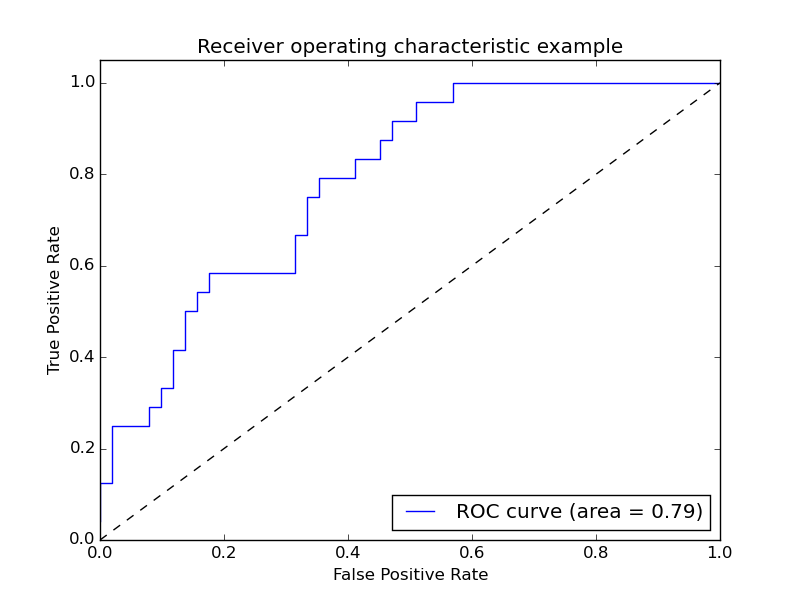
先说ROC,ROC(receiver operating characteristic curve)是曲线。也就是下图中的曲线。同时我们也看里面也上了AUC也就是是面积。一般来说,如果ROC是光滑的,那么基本可以判断没有太大的overfitting(比如图中0.2到0.4可能就有问题,但是样本太少了),这个时候调模型可以只看AUC,面积越大一般认为模型越好。
 再说PRC, precision recall curve。和ROC一样,先看平滑不平滑(蓝线明显好些),在看谁上谁下(同一测试集上),一般来说,上面的比下面的好(绿线比红线好)。F1(计算公式略)当P和R接近就也越大,一般会画连接(0,0)和(1,1)的线,线和PRC重合的地方的F1是这条线最大的F1(光滑的情况下),此时的F1对于PRC就好象AUC对于ROC一样。一个数字比一条线更方便调模型。
再说PRC, precision recall curve。和ROC一样,先看平滑不平滑(蓝线明显好些),在看谁上谁下(同一测试集上),一般来说,上面的比下面的好(绿线比红线好)。F1(计算公式略)当P和R接近就也越大,一般会画连接(0,0)和(1,1)的线,线和PRC重合的地方的F1是这条线最大的F1(光滑的情况下),此时的F1对于PRC就好象AUC对于ROC一样。一个数字比一条线更方便调模型。
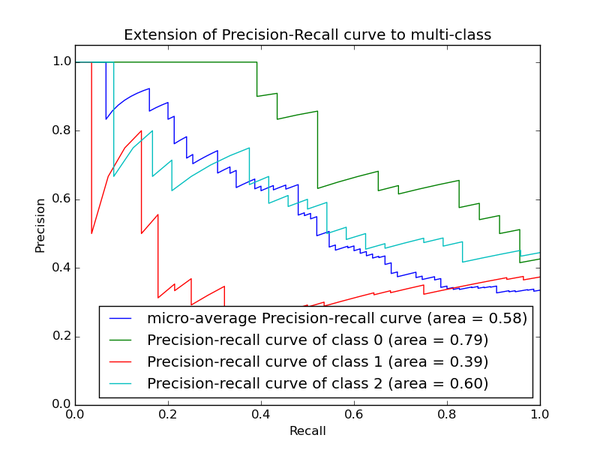 以上两个指标用来判断模型好坏,图有些不恰当。。。但是有时候模型没有单纯的谁比谁好(比如图二的蓝线和青线),那么选择模型还是要结合具体的使用场景。
以上两个指标用来判断模型好坏,图有些不恰当。。。但是有时候模型没有单纯的谁比谁好(比如图二的蓝线和青线),那么选择模型还是要结合具体的使用场景。
下面是两个场景:
1. 地震的预测
对于地震的预测,我们希望的是RECALL非常高,也就是说每次地震我们都希望预测出来。这个时候我们可以牺牲PRECISION。情愿发出1000次警报,把10次地震都预测正确了;也不要预测100次对了8次漏了两次。
2. 嫌疑人定罪
基于不错怪一个好人的原则,对于嫌疑人的定罪我们希望是非常准确的。及时有时候放过了一些罪犯(recall低),但也是值得的。
对于分类器来说,本质上是给一个概率,此时,我们再选择一个CUTOFF点(阀值),高于这个点的判正,低于的判负。那么这个点的选择就需要结合你的具体场景去选择。反过来,场景会决定训练模型时的标准,比如第一个场景中,我们就只看RECALL=99.9999%(地震全中)时的PRECISION,其他指标就变得没有了意义。
如果只能选一个指标的话,肯定是选PRC了。可以把一个模型看的一清二楚。
能想到的暂时就这些了,希望对你有帮助!有错误望纠正。
再说PRC, precision recall curve。和ROC一样,先看平滑不平滑(蓝线明显好些),在看谁上谁下(同一测试集上),一般来说,上面的比下面的好(绿线比红线好)。F1(计算公式略)当P和R接近就也越大,一般会画连接(0,0)和(1,1)的线,线和PRC重合的地方的F1是这条线最大的F1(光滑的情况下),此时的F1对于PRC就好象AUC对于ROC一样。一个数字比一条线更方便调模型。以上两个指标用来判断模型好坏,图有些不恰当。。。但是有时候模型没有单纯的谁比谁好(比如图二的蓝线和青线),那么选择模型还是要结合具体的使用场景。下面是两个场景:
1. 地震的预测
对于地震的预测,我们希望的是RECALL非常高,也就是说每次地震我们都希望预测出来。这个时候我们可以牺牲PRECISION。情愿发出1000次警报,把10次地震都预测正确了;也不要预测100次对了8次漏了两次。
2. 嫌疑人定罪
基于不错怪一个好人的原则,对于嫌疑人的定罪我们希望是非常准确的。及时有时候放过了一些罪犯(recall低),但也是值得的。
对于分类器来说,本质上是给一个概率,此时,我们再选择一个CUTOFF点(阀值),高于这个点的判正,低于的判负。那么这个点的选择就需要结合你的具体场景去选择。反过来,场景会决定训练模型时的标准,比如第一个场景中,我们就只看RECALL=99.9999%(地震全中)时的PRECISION,其他指标就变得没有了意义。
如果只能选一个指标的话,肯定是选PRC了。可以把一个模型看的一清二楚。
能想到的暂时就这些了,希望对你有帮助!有错误望纠正。
作者:金戈戈
链接:https://www.zhihu.com/question/30643044/answer/48955833
来源:知乎
著作权归作者所有,转载请联系作者获得授权。
链接:https://www.zhihu.com/question/30643044/answer/48955833
来源:知乎
著作权归作者所有,转载请联系作者获得授权。
先说ROC,ROC(receiver operating characteristic curve)是曲线。也就是下图中的曲线。同时我们也看里面也上了AUC也就是是面积。一般来说,如果ROC是光滑的,那么基本可以判断没有太大的overfitting(比如图中0.2到0.4可能就有问题,但是样本太少了),这个时候调模型可以只看AUC,面积越大一般认为模型越好。
再说PRC, precision recall curve。和ROC一样,先看平滑不平滑(蓝线明显好些),在看谁上谁下(同一测试集上),一般来说,上面的比下面的好(绿线比红线好)。F1(计算公式略)当P和R接近就也越大,一般会画连接(0,0)和(1,1)的线,线和PRC重合的地方的F1是这条线最大的F1(光滑的情况下),此时的F1对于PRC就好象AUC对于ROC一样。一个数字比一条线更方便调模型。
以上两个指标用来判断模型好坏,图有些不恰当。。。但是有时候模型没有单纯的谁比谁好(比如图二的蓝线和青线),那么选择模型还是要结合具体的使用场景。
下面是两个场景:
1. 地震的预测
对于地震的预测,我们希望的是RECALL非常高,也就是说每次地震我们都希望预测出来。这个时候我们可以牺牲PRECISION。情愿发出1000次警报,把10次地震都预测正确了;也不要预测100次对了8次漏了两次。
2. 嫌疑人定罪
基于不错怪一个好人的原则,对于嫌疑人的定罪我们希望是非常准确的。及时有时候放过了一些罪犯(recall低),但也是值得的。
对于分类器来说,本质上是给一个概率,此时,我们再选择一个CUTOFF点(阀值),高于这个点的判正,低于的判负。那么这个点的选择就需要结合你的具体场景去选择。反过来,场景会决定训练模型时的标准,比如第一个场景中,我们就只看RECALL=99.9999%(地震全中)时的PRECISION,其他指标就变得没有了意义。
如果只能选一个指标的话,肯定是选PRC了。可以把一个模型看的一清二楚。
能想到的暂时就这些了,希望对你有帮助!有错误望纠正。
再说PRC, precision recall curve。和ROC一样,先看平滑不平滑(蓝线明显好些),在看谁上谁下(同一测试集上),一般来说,上面的比下面的好(绿线比红线好)。F1(计算公式略)当P和R接近就也越大,一般会画连接(0,0)和(1,1)的线,线和PRC重合的地方的F1是这条线最大的F1(光滑的情况下),此时的F1对于PRC就好象AUC对于ROC一样。一个数字比一条线更方便调模型。以上两个指标用来判断模型好坏,图有些不恰当。。。但是有时候模型没有单纯的谁比谁好(比如图二的蓝线和青线),那么选择模型还是要结合具体的使用场景。下面是两个场景:
1. 地震的预测
对于地震的预测,我们希望的是RECALL非常高,也就是说每次地震我们都希望预测出来。这个时候我们可以牺牲PRECISION。情愿发出1000次警报,把10次地震都预测正确了;也不要预测100次对了8次漏了两次。
2. 嫌疑人定罪
基于不错怪一个好人的原则,对于嫌疑人的定罪我们希望是非常准确的。及时有时候放过了一些罪犯(recall低),但也是值得的。
对于分类器来说,本质上是给一个概率,此时,我们再选择一个CUTOFF点(阀值),高于这个点的判正,低于的判负。那么这个点的选择就需要结合你的具体场景去选择。反过来,场景会决定训练模型时的标准,比如第一个场景中,我们就只看RECALL=99.9999%(地震全中)时的PRECISION,其他指标就变得没有了意义。
如果只能选一个指标的话,肯定是选PRC了。可以把一个模型看的一清二楚。
能想到的暂时就这些了,希望对你有帮助!有错误望纠正。
准确和召回评价的是两个不同的方面,不好比较,个人感觉在召回方面,工业界比学术界关注得更多。F1是对两者的综合。ROC和AUC是一回事,通常用于二分类的评价,AUC用得比较多的一个重要原因是,实际环境中正负样本极不均衡,PR曲线无法很好反映出分类器性能,而ROC受此影响小。
作者:刘文琦
链接:https://www.zhihu.com/question/30643044/answer/62090327
来源:知乎
著作权归作者所有,转载请联系作者获得授权。
作者:刘文琦
链接:https://www.zhihu.com/question/30643044/answer/62090327
来源:知乎
著作权归作者所有,转载请联系作者获得授权。
作者:巴人
链接:https://www.zhihu.com/question/30643044/answer/62971378
来源:知乎
著作权归作者所有,转载请联系作者获得授权。
链接:https://www.zhihu.com/question/30643044/answer/62971378
来源:知乎
著作权归作者所有,转载请联系作者获得授权。
Calculation formula:
What's the difference:
Precision:P=TP/(TP+FP)
Recall:R=TP/(TP+FN)
F1-score:2/(1/P+1/R)
ROC/AUC:TPR=TP/(TP+FN), FPR=FP/(FP+TN)
What's the difference:
- AUC是ROC的积分(曲线下面积),是一个数值,一般认为越大越好,数值相对于曲线而言更容易当做调参的参照。
- PR曲线会面临一个问题,当需要获得更高recall时,model需要输出更多的样本,precision可能会伴随出现下降/不变/升高,得到的曲线会出现浮动差异(出现锯齿),无法像ROC一样保证单调性。
- real world data经常会面临class imbalance问题,即正负样本比例失衡。根据计算公式可以推知,在testing set出现imbalance时ROC曲线能保持不变,而PR则会出现大变化。引用图(Fawcett, 2006),(a)(c)为ROC,(b)(d)为PR,(a)(b)样本比例1:1,(c)(d)为1:10。
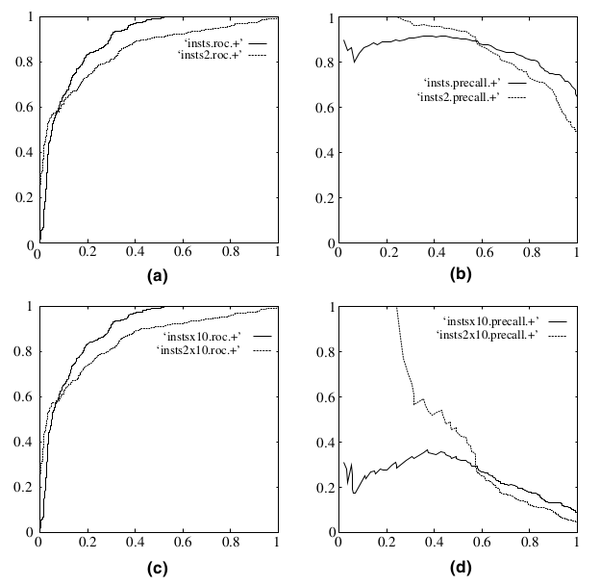
- 结合个人的经验:学术论文在假定正负样本均衡的时候多用ROC/AUC,实际工程更多存在数据标签倾斜问题一般使用F1。