NUMPY
什么是numpy
- 帮助我们处理数值型数据
- 快速
- 方便
- 科学计算的基础库
一个在Python中做科学计算的基础库,重在数值计算,是大部分Python科学计算库的基础库,多用于大型,多维数组上执行数值运算
1.numpy创建数组(矩阵)
在 NumPy 数组中,维数称为秩(rank),一维数组的秩为 1,二维数组的秩为 2,以此类推。在 NumPy 中,每一个线性的数组称为一个轴(axes),其实秩就是描述轴的数量。
1.1 numpy生成数据类型
import numpy as np
a = np.array([1, 2, 3, 4, 5])
b = np.array(range(1, 6)) # a,b,c内容相同,注意arange和range的区别
c = np.arange(1, 6) # 运行结果
print(a) [1 2 3 4 5]
print(type(a)) <class 'numpy.ndarray'>
print(b) [1 2 3 4 5]
print(type(b)) <class 'numpy.ndarray'>
print(c) [1 2 3 4 5]
print(type(c)) <class 'numpy.ndarray'>
print(d.dtype) int32 # 通过dtype属性获取列表中数据的类型
在Numpy中,有许多新增的类型:
| 类型 | 类型代码 | 说明 |
|---|---|---|
| int8,uint8 | i1,u1 | 有符号和无符号的8位(1个字节)整型 |
| int16,uint16 | i2,u2 | 有符号和无符号的16位(2个字节)整型 |
| int32,uint32 | i4,u4 | 有符号和无符号的32位(4个字节)整型 |
| int64,uint64 | i8,u8 | 有符号和无符号的64位(8个字节)整型 |
| float16 | f2 | 半精度浮点型 |
| float32 | f4或f | 标准的单精度浮点数,与C的float兼容 |
| float64 | f8或d | 标准的双精度浮点数,与C的doublehe和python的float对象兼容 |
| float128 | f16或g | 扩展精度浮点数 |
| complex64,complex128 | c8,c16 | 分别用两个32位,64位或128位浮点数表示 |
| complex256 | c32 | 复数 |
| bool | ? | 存储True和False的布尔类型 |
可以在代码中指定数组的类型
import numpy as np
# 创建数组的时候可以进行指定类型
a = np.array([1, 2, 3, 4, 5], dtype="int64")
a = np.array([1, 2, 3, 4, 5], dtype="float32")
b = np.array(range(1, 6))
c = np.arange(1, 6)
1.2 numpy调整数据类型
import numpy as np
d = np.array([1, 1, 0, 1], dtype=bool)
print(d)
#调整数据类型 运行结果:
f = d.astype("int8") [ True True False True]
print(f) [ 1 1 0 1 ]
print(type(f)) <class 'numpy.ndarray'>
1.3 numpy数据类型操作
指定创建的数组的数据类型:
In [5]: a = np.array([1,0,1,0],dtype=np.bool) # 或者使用dtype='?'
In [6]: a
Out[6]: array([ True, False, True, False])
修改数组的数据类型:
In [8]: a.astype("i1") #或者使用a.astype(np.int8)
Out[8]: array([1, 0, 1, 0], dtype=int8)
修改浮点型的小数位数:np.rand()时对其取小数,下面是把b数组的每一项取两位小数
In [17]: b
Out[17]: array([0.022, 0.333, 0.78 ])
In [18]: np.round(b,2)
Out[18]: array([0.02, 0.33, 0.78])
2.numpy数组的形状
几行几列称为数组的形状 例如下图中数组的形状是2行6列:
In [23]: a = np.array([[3,4,5,6,7,8],[4,5,6,7,8,9]])
In [24]: a
Out[24]: array([[3, 4, 5, 6, 7, 8], [4, 5, 6, 7, 8, 9]])
In [26]: a.shape # 查看数组形状
Out[26]: (2, 6)
数组形状也可以是三维数组:
a.reshape(2,4,3)是将24个值的一维数组转换位 2块,4行,3列的三维数组
In [29]: a = np.arange(24)
In [30]: a
Out[30]: array([0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23])
In [32]: a = a.reshape(2,4,3) # 将a数组转换位三维数组
In [33]: a
Out[33]: array([[[ 0, 1, 2],
[ 3, 4, 5],
[ 6, 7, 8],
[ 9, 10, 11]],
[[12, 13, 14],
[15, 16, 17],
[18, 19, 20],
[21, 22, 23]]])
三维数组也可转换为二维或别的维度的数组。注意: reshape中间参数的值的积必须是数组中元素的总数 reshape函数是有返回值的
In [33]: a
Out[33]: array([[[ 0, 1, 2],
[ 3, 4, 5],
[ 6, 7, 8],
[ 9, 10, 11]],
[[12, 13, 14],
[15, 16, 17],
[18, 19, 20],
[21, 22, 23]]])
In [34]: a.reshape(2,2,3,2)
Out[34]:array([ [ [[ 0, 1],[ 2, 3],[ 4, 5]],
[[ 6, 7],[ 8, 9],[10, 11]] ],
[ [[12, 13],[14, 15],[16, 17]],[[18, 19], [20, 21], [22, 23]]]])
将多维数组进行展开a = a.flatten() 有返回值,并不是引用修改,和reshape()一样
In [35]: a
Out[35]: array([[[ 0, 1, 2],
[ 3, 4, 5],
[ 6, 7, 8],
[ 9, 10, 11]],
[[12, 13, 14],
[15, 16, 17],
[18, 19, 20],
[21, 22, 23]]])
In [36]: a = a.flatten() # 将其展开一维数组
In [37]: a
Out[37]: array([0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23])
3.numpy数组计算
3.1 数组和数字进行计算
数组和数字加减乘除都是可以直接计算的
In [39]: a
Out[39]: array([0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23])
In [40]: a = a + 2
In [41]: a
Out[41]: array([2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25])
如何和0进行计算,可以看到0/0是nan,这里只的是no num即不是一个数字,inf是无穷的意思
In [46]: a
Out[46]: array([0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23])
In [47]: a/0
Out[47]:array([nan,inf,inf,inf...,,inf,inf,inf])
3.2 数组和数组进行计算
数组结构一模一样的时候,对应位置进行计算
In [48]: t5 = np.arange(24)
In [49]: t6 = np.arange(24)
In [50]: t5+t6
Out[50]: array([0,2,4,6,8,10,12,14,16,18,20,22,24,26,28,30,32,34,36,38,40,42,44,46])
如果数组结构不一样的时候,只计算维度相同的那一部分,如下图,t5是4行6列,t7是1行6列,列相同 .t5每一行和t7这一行进行计算,也就是说,只要列相同就可以进行计算 :t5的第一行分别和t7进行计算 t5的第二行分别和t7进行计算 ...
In [59]: t5
Out[59]: array([[ 0, 1, 2, 3, 4, 5],
[ 6, 7, 8, 9, 10, 11],
[12, 13, 14, 15, 16, 17],
[18, 19, 20, 21, 22, 23]])
In [60]: t7
Out[60]: array([0, 1, 2, 3, 4, 5])
In [61]: t5-t7
Out[61]: array([[ 0, 0, 0, 0, 0, 0],
[ 6, 6, 6, 6, 6, 6],
[12, 12, 12, 12, 12, 12],
[18, 18, 18, 18, 18, 18]])
当只有列维度一样的时候,t5是4行6列,t8是4行1列,行相同 ,进行运算的时候t5的每一列和t8进行运算
In [59]: t5
Out[59]: array([[ 0, 1, 2, 3, 4, 5],
[ 6, 7, 8, 9, 10, 11],
[12, 13, 14, 15, 16, 17],
[18, 19, 20, 21, 22, 23]])
In [62]: t8=np.arange(4).reshape((4,1))
In [63]: t8
Out[63]: array([[0],
[1],
[2],
[3]])
In [64]: t5-t8
Out[64]: array([[ 0, 1, 2, 3, 4, 5],
[ 5, 6, 7, 8, 9, 10],
[10, 11, 12, 13, 14, 15],
[15, 16, 17, 18, 19, 20]])
可以进行计算的情况:
In [114]: a # 2行6列的数组 Out[114]: array([[ 3, 4, 5, 6, 7, 8], [ 4, 5, 6, 7, 8, 9]]) In [115]: c # 2行1列的数组 Out[115]: array([[1], [2]]) In [116]: c+a # 相加 Out[116]: array([[ 4, 5, 6, 7, 8, 9], [ 6, 7, 8, 9, 10,11]]) In [117]: a*c #相乘 Out[117]: array([[ 3, 4, 5, 6, 7, 8], [ 8,10,12,14,16,18]]) In [118]: c*a #相乘 Out[118]: array([[ 3, 4, 5, 6, 7, 8], [ 8, 10,12,14,16,18]])计算广播原则:
下图中轴长相等,下例子中shape为(3,3,2)和shape为(3,2)从末尾开始的维度,也就是在(3,2)这个维度上是一样的,则是可以计算的,或者有一方长度为1,比如说有一个维度是1,比如说第二个shape(3,1)或者(1,2)都是可以和(3,3,2)进行计算的
如果两个数组后缘维度(trailing dimension,即从末尾开始算起的难度)的轴长度相符或其中一方的长度为1,则认为他们是广播兼容的。广播会在缺失和长度为1的维度上进行。
shape为(3,3,3)的数组能够和(3,2)进行计算么? 不可以
shape为(3,3,2)的数组能够和(3,2)进行计算么? 可以
4.轴的概念
在numpy中可以理解为方向,使用1,2...数字表示,对于一个一维数组,只有一个0轴,对于二维数组(shape(2,2)),有0轴和1轴,对于三维数组(shape(2,2,3)),有012轴,几维数组,就是几个轴
数组的轴
二维数组只有两个轴 三维数组有3个轴,0轴表示块

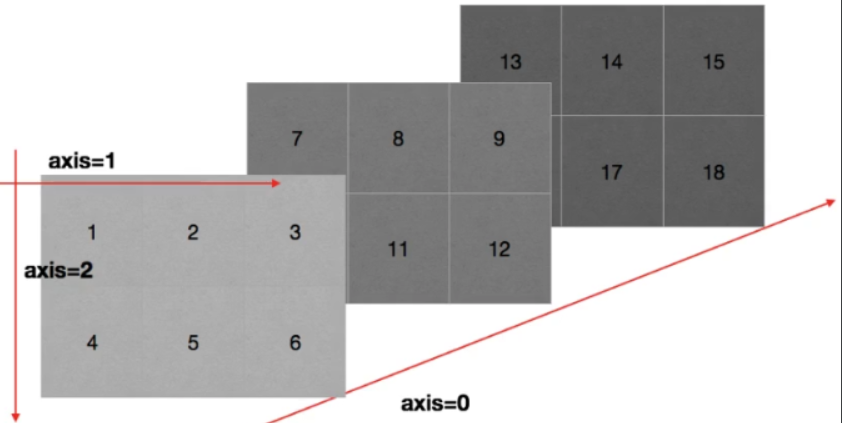
5.numpy读取本地数据
numpy从csv中读取数据:
CSV: 逗号分隔值文件,其显示形式是表格状态,源文件是换行和逗号分隔列的格式化文本,每一行的数据标识一条记录。
读取数据:
import numpy as np """ @:param frame 文本文件,文件路径 @:param dtype 数据读出来之后指定的类型,比如说要把读出的数据指定为float @:param delimiter 数据是用什么分割开的,读csv文件用逗号 @:param skiprows 跳过哪一行 @:param useclos 使用哪一列 @:param unpack 专制 """ np.loadtxt(frame,dtype=np.float,delimiter=None,skiprows=0,usecols=None,unpack=False)
参数 解释 frame 文件,字符串或产生器,可以是.gz或者bz2压缩文件 dtype 数据类型,可选,csv的字符串以什么数据类型读入数组中,默认np.float delimiter 分隔字符串,默认是任何空格,可以改为逗号(在csv中都是以逗号分隔的) skiprows 跳过前x行,一般跳过第一行表头 usecols 读取指定的列,索引,元组类型 unpack 如果True,读入属性将分别写入不通数组变量,False读入数据只写入一个数组变量,默认False
示例:
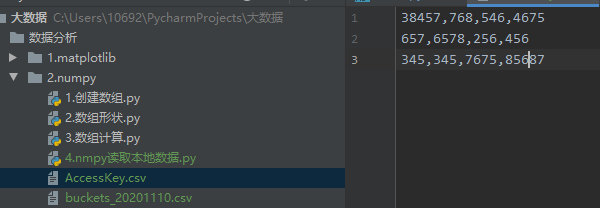
现在有两个csv文件,进行读取操作,csv文件结构如图:
import numpy as np #运行结果:[[3857, 768,546,4675], us_file_path = "./a.csv" [657 ,6578,256 ,456 ], # 将所有数据读为int类型,默认情况下unpack为false [345,345 ,7675,85678]] t1=np.loadtxt(us_file_path, delimiter=",", dtype="int") print(t1)如果将unpack设置为True,可以看到结果集进行了旋转,原来的行变为列了
import numpy as np # 运行结果:[[38257 657 345] [ 768 6578 345] us_file_path = "./a.csv" [ 546 256 7656] # 将所有数据读为int类型 [ 4675 456 85678]] t1 = np.loadtxt(us_file_path, delimiter=",", dtype="int",unpack=True) print(t1)
读取数据时注意:
- 注意其中添加
delimiter和dtype以及unpack的效果
delimiter: 指定边界符号是什么,不指定会导致每行数据为一个整体的字符串而报错dtype: 默认情况下对于较大的数据会将其变为科学计数的方式- unpack的效果:
- 默认是False(0),默认情况下,有多少条数据,就会有多少行。
- 为True(1)的情况下,没一列的数据会组成一行,原始数据有多少列,加载出来的数据就会有多少行,相当于转置的效果
转置:转置是一种变换,对于numpy中的数组来说,就是在对角线方向交换数据,目的也是为了更方便的去处理数据
In [4]: t Out[4]: array([[ 0, 1, 2, 3, 4, 5], [ 6, 7, 8, 9, 10, 11], [12, 13, 14, 15, 16, 17]]) In [5]: t.transpose() Out[5]: array([[ 0, 6, 12], [ 1, 7, 13], [ 2, 8, 14], [ 3, 9, 15], [ 4, 10, 16], [ 5, 11, 17]]) In [6]: t.swapaxes(1,0) Out[6]: array([[ 0, 6, 12], [ 1, 7, 13], [ 2, 8, 14], [ 3, 9, 15], [ 4, 10, 16], [ 5, 11, 17]]) In [7]: t.T Out[7]: array([[ 0, 6, 12], [ 1, 7, 13], [ 2, 8, 14], [ 3, 9, 15], [ 4, 10, 16], [ 5, 11, 17]])
transpose()方法:将行变为列- T : 和上述
transpose一样swapaxes()方法: 交换轴,swapaxes(1,0)是将1轴和0轴进行交换
6.numpy索引和切片
numpy的切片和python中类似:
取行:
In [27]: a Out[27]: array([[ 0, 1, 2, 3], [ 4, 5, 6, 7], [ 8, 9, 10, 11]]) In [28]: a[1] # 取一行 Out[28]: array([4, 5, 6, 7]) In [29]: a[:,2] # 取一列 Out[29]: array([ 2, 6, 10]) In [30]: a[1:3] #取多行 Out[30]: array([[ 4, 5, 6, 7], [ 8, 9, 10, 11]]) In [31]: a[:,2:4] #取多列 Out[31]: array([[ 2, 3], [ 6, 7], [10, 11]]) In [32]: a[1:] # 取连续多行 Out[32]: array([[ 4, 5, 6, 7], [ 8, 9, 10, 11]]) In [36]: a[[0,2]] # 不连续取多行 Out[36]: array([[ 0, 1, 2, 3], [ 8, 9, 10, 11]])
取列:
In [17]: t1[:,1] # 取第一列,左边为:代表所有行 Out[17]: array([ 657, 6578, 256, 456]) In [20]: t1[:,[1,2]] # 取第1列,第2列,左边为:代表所有行 Out[20]: array([[ 657, 345], [ 6578, 345], [ 256, 7675], [ 456, 85687]]) In [38]: t1 Out[38]: array([[38457, 657, 345], [ 768, 6578, 345], [ 546, 256, 7675], [ 4675, 456, 85687]]) In [39]: t1[0:2,1:2] # 行0-2,列1-2 Out[39]: array([[ 657], [6578]]) In [40]: t1[[0,2],[0,1]] # 取的是0,0点和2,1点 Out[40]: array([38457, 256]) In [41]: t1[[0,2,1],[0,1,1]] # 取0,0;2,1;1,1三个点 Out[41]: array([38457, 256, 6578])
7.numpy数值修改
In [29]: t1
Out[29]: array([[38457, 657, 345],
[ 768, 6578, 345],
[ 546, 256, 7675],
[ 4675, 456, 85687]])
In [30]: t1[:,[1,2]] = 0
In [31]: t1
Out[31]: array([[38457, 0, 0],
[ 768, 0, 0],
[ 546, 0, 0],
[ 4675, 0, 0]])
In [32]: t1<10
Out[32]: array([[False, True, True],
[False, True, True],
[False, True, True],
[False, True, True]])
In [33]: t1[t1<10] = 3 #将小于10的改为3
In [34]: t1
Out[34]: array([[38457, 3, 3],
[ 768, 3, 3],
[ 546, 3, 3],
[ 4675, 3, 3]])
In [35]: t1[t1 > 10] # 取大于10的数
Out[35]: array([38457, 768, 546, 4675])
7.1 np三元运算符:
np.where(t<10,0,10) t1小于10的换为0,大于等于10的改为10
In[37]: t1
Out[37]: array([[38457, 3, 3],
[ 768, 3, 3],
[ 546, 3, 3],
[ 4675, 3, 3]])
In[38]: np.where(t1 < 10, 0, 10) # t1小于10的换为0,大于等于10的改为10
Out[38]: array([[10, 0, 0],
[10, 0, 0],
[10, 0, 0],
[10, 0, 0]])
7.2 np裁剪
numpy中的裁剪(clip): t.clip(10,18) 将t中比10小的替换为10,比18大的替换为18
numpy中赋值nan,nan意思为不是一个数,但是属于float类型
In [44]: t1 = t1.astype(np.float)
In [45]: t1
Out[45]: array([[3.8457e+04, 3.0000e+00, 3.0000e+00],
[7.6800e+02, 3.0000e+00, 3.0000e+00],
[5.4600e+02, 3.0000e+00, 3.0000e+00],
[4.6750e+03, 3.0000e+00, 3.0000e+00]])
In [46]: t1[0,0] = np.nan
In [47]: t1
Out[47]: array([[ nan, 3.000e+00, 3.000e+00],
[7.680e+02, 3.000e+00, 3.000e+00],
[5.460e+02, 3.000e+00, 3.000e+00],
[4.675e+03, 3.000e+00, 3.000e+00]])
8.numpy数组拼接
案例:将两个csv进行拼接
In [13]: t1
Out[13]: array([[ 0, 1, 2, 3, 4, 5],
[ 6, 7, 8, 9, 10, 11]])
In [14]: t2
Out[14]: array([[12, 13, 14, 15, 16, 17],
[18, 19, 20, 21, 22, 23]])
In [15]: np.vstack((t1,t2)) # 竖直拼接
Out[15]: array([[ 0, 1, 2, 3, 4, 5],
[ 6, 7, 8, 9, 10, 11],
[12, 13, 14, 15, 16, 17],
[18, 19, 20, 21, 22, 23]])
In [16]: np.hstack((t1,t2)) # 水平拼接
Out[16]: array([[ 0, 1, 2, 3, 4, 5, 12, 13, 14, 15, 16, 17],
[ 6, 7, 8, 9, 10, 11, 18, 19, 20, 21, 22, 23]])
将不同的行和列进行交换:
In [19]: t
Out[19]: array([[12, 13, 14, 15],
[16, 17, 18, 19],
[20, 21, 22, 23]])
In [21]: t[[1,2],:] = t[[2,1],:] # 行交换
In [22]: t
Out[22]: array([[12, 13, 14, 15],
[20, 21, 22, 23],
[16, 17, 18, 19]])
In [23]: t[:,[0,2]] = t[:,[2,0]] # 列交换
In [24]: t
Out[24]: array([[14, 13, 12, 15],
[22, 21, 20, 23],
[18, 17, 16, 19]])
案例:将前面两个文件放到一起来研究,同时保留不同文件的信息
文件内容如下:
AccessKey.csv
38457 , 768 , 546 , 4675
657 ,6578 , 256 , 456
345 , 345 ,7675 , 85687
buckets_20201110.csv
218379123 , 382374 , 43298420394 ,844
923849348 , 342934 , 34934 ,349234
3123 , 4325 , 6467 ,474
代码如下:
import numpy as np
us_file_path = "./a.csv"
ns_file_path = "./buckets_20201110.csv"
# 将所有数据读为int类型
t1 = np.loadtxt(us_file_path, delimiter=",", dtype="int", unpack=False)
t2 = np.loadtxt(ns_file_path, delimiter=",", dtype=np.int, unpack=False)
print(t1)
print(t2)
# 创建一个全部为0的数组,t1的行,1列
zero_data = np.zeros((t1.shape[0], 1)).astype(np.int)
print(zero_data)
# 创建一个全部为1的数组,t2的行,1列
ones_data = np.ones((t2.shape[0], 1)).astype(np.int)
print(ones_data)
# 拼接列 ,t1添加一列全为0的
t1 = np.hstack((t1, zero_data))
print(t1)
# 拼接列 ,t2添加一列全为1的
t2 = np.hstack((t2, ones_data))
print(t2)
# 拼接数组,垂直添加
final_data = np.vstack((t1, t2))
print(final_data)
结果集:
# t1
[[38457 768 546 4675]
[ 657 6578 256 456]
[ 345 345 7675 85687]]
# t2
[[ 218379123 382374 43298420394 844]
[ 923849348 342934 34934 349234]
[ 3123 4325 6467 474]]
# 创建一个全部为0的数组,t1的行,1列
[[0]
[0]
[0]]
# 创建一个全部为1的数组,t2的行,1列
[[1]
[1]
[1]]
# 拼接列 ,t1添加一列全为0的
[[38457 768 546 4675 0]
[ 657 6578 256 456 0]
[ 345 345 7675 85687 0]]
# 拼接列 ,t2添加一列全为1的
[[ 218379123 382374 43298420394 844 1]
[ 923849348 342934 34934 349234 1]
[ 3123 4325 6467 474 1]]
# 拼接数组
[[ 38457 768 546 4675 0]
[ 657 6578 256 456 0]
[ 345 345 7675 85687 0]
[ 218379123 382374 43298420394 844 1]
[ 923849348 342934 34934 349234 1]
[ 3123 4325 6467 474 1]]
9.numpy更多好用的方法
-
获取最大值最小值的位置
np.argmax(t1.axis=0)np.argmin(t1.axis=1)
-
创建一个全0的数组:
np.zeros((3,4))创建3行4列的数组 -
创建一个全1的数组:
NP.ONES((3,4))创建一个3行4列全为1的数组 -
创建一个对角线为1的正方形数组(方阵):
np.eye(3)创建一个3行3列对角线为1的数组 -
numpy生成随机数
参数 解释 .rand(d0,d1,..dn)创建d0-dn唯独的均匀分布的随机数数组,浮点数,范围从0-1 .randn(d0,d1,...dn)创建d0-dn维度的标准正态分布随机数, 浮点数, 平均数0,标准差1 .randint(low,high,(shape))从给定上下限范围选取随机数整数,范围是low,high,形状是shape .uniform(low,high,(size))产生具有均匀分布的数组(这个不像randint是整数,为小数),low起始值,high结束值,size形状 .normal(loc,scale,(size))从指定正态分布中随机抽取样本,分布中心是Ioc(概率分布的均值),标准差是scale,形状是size .seed(s)随机数种子,s是给定的种子值。因为计算机生成的是伪随机数,所以通过设定相同的随机数种子,可以每次生成相同的随机数
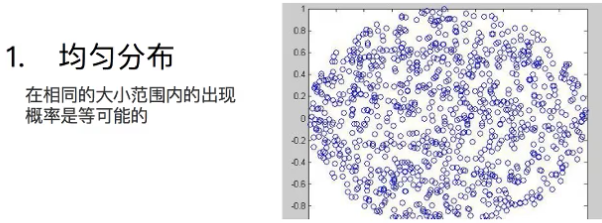
关于均匀分布: 在相同的大小范围内出现概率是等可能的,如图:
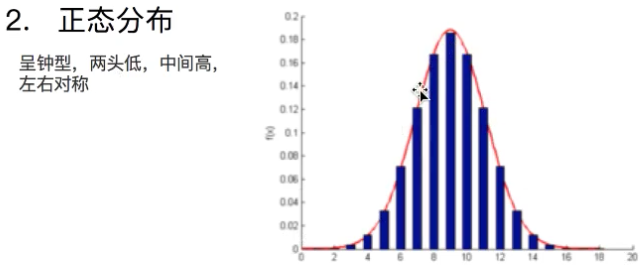
关于正态分布:呈钟形,两头低,中间高,左右对称,如图:
关于标准正态分布:在上图正态分布的基础上,最高点移动到y轴上面,左右关于y轴对称称为标准正态分布。
randint举例(用的最多):
In [2]: np.random.randint(10,20,(2,3)) #从10到20(不包括20)选取随机2行3列数组
Out[2]: array([[12, 17, 11],[14, 15, 11]])
关于随机数种子:
In [6]: np.random.seed(10)
In [7]: np.random.randint(0,20,(2,3)) #加上随机数种子之后,所有的随机数都一样
Out[7]: array([[ 9, 4, 15],[ 0, 17, 16]])
10.numpy中copy和view
a = b完全不复制,a和b相互影响,相当于浅拷贝,如果赋值完毕,改了b,那么a也会改a = b[:], 视图的操作,一种切片,会创建新的对象a,但是a的数据完全由b保管,他们两个的数据变化是一致的,即a中保存了b的地址a = b.copy(),复制,a和b互不影响
11.numpy中nan和inf
nan(NAN,Nan): not a number 表示不是一个数字
什么时候会出现nan:
- 当我们读取本地的文件为float的时候,如果有缺失,就会出现nan
- 当做了一个不合适的计算的时候(比如无穷大inf)减去无穷大(inf)
inf(-inf,inf):infinity inf表示正无穷,-inf表示负无穷
什么时候会出现inf包括(-inf,+inf)
- 比如一个数字除以0,(python中会直接报错,numpy中是一个inf或者-inf
如何指定一个nan或者inf
注意他们的type类型:
In[71]: a = np.inf In[73]: type(a) Out[73]: float In[74]: a = np.nan In[75]: type(a) Out[75]: float
numpy中nan注意的点
两个nan是不相等的
np.nan == np.nan结果为False
np.nan!=np.nan结果为True利用以上的特性,判断数组中nan的个数
t为array([1.,2.,nan])通过nan==nan为Falsenp.count_nozero(t!=t)结果为1由于上述2,可以通过
np.isnan(a)来判断一个数字是否为nan,比如说希望吧nan替换为0,t为array([1,2,nan]),通过t[np.isnan(t)]=0将t中的nan改为0nan和任何值计算都为nan
例如:np.sum(t3,axis=0)是将t3这个二维数组每一列都相加,同理如果axis=1则是计算行上的和In [99]: t3 Out [99]: array([[0,1,2,3],[4,5,6,7],[8,9,10,11]]) In [100]: np.sum(t3) Out[100]: 66 In [101]: np.sum(t3, axis = 0) Out[101]: array([12,15,18,21])如果
sum函数没有指定axis则是整个矩阵的和注意:
在一组数据中单纯的把nan替换为0,合适吗?会带来什么样的影响。比如,全部替换为0后,替换之前的平均值如果大于0,替换后的平均值肯定会变小,所以更一般的方式是把确实的数据值替换为 均值(中值)或者是直接 删除有缺失值的一行,引出问题:如何计算一组数据中的中值或者是均值,如何删除有缺失数据的那一行(列) 在pandas中介绍
12. numpy中常用统计函数
求和 t.sum(axix=None)
均值 t.mean(axis=None) 收离群点的影响较大
中值 np.median(t,axis=None)
最大值 t.max(axis=None)
最小值 t.min(axis=None)
极值 np.ptp(t,axis=None) 即最大值和最小值之差
标准差 t.std(axis=None)
标准差是一组数据平均值分散程度的一种度量。一个较大的标准差,代表大部分数值和其平均值之间差异较大,一个较小的标准差,代表这些数值较接近平均值,反映出数据的波动稳定情况,越大表示波动越大,越不稳定
默认返回多维数组的全部的统计结果,如果指定axis则返回当前轴上的结果
举例 加法,均值,中值,最大值最小值,极值,标准差运算:
# 举例,对数组t2: array([[ 0., 3., 3., 3., 3., 3.], [ 0., 3., 3., 3., 10., 11.], [ 0., 13., 14., 15., 16., 17.], [ 0., 19., 20., nan, 20., 20.]]) # 加法运算: In [11]: t2.sum(axis = 0) Out[11]: array([ 0., 38., 40., nan, 49., 51.]) # 均值运算: In [12]: t2.mean(axis = 0) Out[12]: array([ 0. , 9.5 , 10. , nan, 12.25, 12.75]) # 中值运算: In [13]: np.median(t2, axis = 0) Out[13]: array([ 0. , 8. , 8.5, nan, 13. , 14. ]) # 最大值最小值运算: In [14]: t2.max(axis = 0) Out[14]: array([ 0., 19., 20., nan, 20., 20.]) In [15]: t2.min(axis = 0) Out[15]: array([ 0., 3., 3., nan, 3., 3.]) # 极值运算 In [16]: np.ptp(t2) Out[16]: nan In [17]: np.ptp(t2, axis = 0) Out[17]: array([ 0., 16., 17., nan, 17., 17.]) # 标准差运算: In [18]: t2.std(axis = 0) Out[18]: array([0., 6.83739717, 7.31436942,nan, 6.41774883,6.49519053]) In [19]: t2.std() Out[19]: nan
案例,将数组中所有的nan替换为其均值:
import numpy as np t1 = np.arange(12).reshape((3, 4)).astype("float") t1[1, 2:] = np.nan print(t1) # 拿到数据,首先遍历所有数据,拿到有nan的列 for i in range(t1.shape[1]): t1_col = t1[:, i] # t1的第i列 # 判断当前列有没有nan nan_num = np.count_nonzero(t1_col != t1_col) if nan_num != 0: # 说明当前列有nan col_ = t1_col[t1_col == t1_col] # 当前列中除nan之外的数 mean = col_.mean() # 当前列的均值 # 将当前列中,凡是isnan的全部替换为均值,类比t(t>10) t1_col[np.isnan(t1_col)] = mean # 转换之后 print(t1)结果集:
[[ 0. 1. 2. 3.] [ 4. 5. nan nan] [ 8. 9. 10. 11.]] # 转换之后====== [[ 0. 1. 2. 3.] [ 4. 5. 6. 7.] [ 8. 9. 10. 11.]]
13. numpy与matplotlib总结案例
根据上述的两个cvs图,回执出格子的评论数量的直方图,希望了解第二个文件中评论书和喜欢数的关系,如何绘制该图。下图中,最后一列是评论数
AccessKey.csv 38457,768,546,4675 657,6578,256,456 345,345,7675,85687buckets_20201110.csv 218379123,382374,43298420394,844 923849348,342934,34934,349234 3123,4325,6467,474