在ECMAscript数据类型有基本类型和引用类型,基本类型有Undefined、Null、Boolean、Number、String,引用类型有Object,所有的的值将会是6种的其中之一.
引用类型的值,也就是对象,一个对象是某个引用对象的实例,可以用new操作符以字面量的方式创建。
ECMA里面有很多原生的引用类型,就是查文档的时候看见的那些:Function、Number(是原是类型Number的引用类型)、String(是对于原是类型String的引用类型)、Date、Array、Boolean(...)、Math、RegExp等等。
1、变量存储
在程序运行的时候,整块内存可以划分为常量池(存放基本类型的值)、栈(存放变量)、堆(存放对象)、运行时环境
基本数据类型的值是直接在常量池里面可以拿到,而引用类型是拿到的是对象的引用
var a = 1; var b = 'helllo'; var c = a;
基本类型数据的赋值,c = a, 只是重新复制一份独立的副本,在变量的对象上创建一个新值,再把值复制到新变量的位置,a、c 它们各自的操作不会影响到对方。
obj1 和 obj2
var obj1 = new Object(); obj1.name = 'obj1' var obj2 = obj1 console.log(obj2)
内存示意图如下:

对于vue,为什么data必须是一个返回一个对象的函数,也是这个道理,避免所有的vue实例共用一套data.
代码片段1
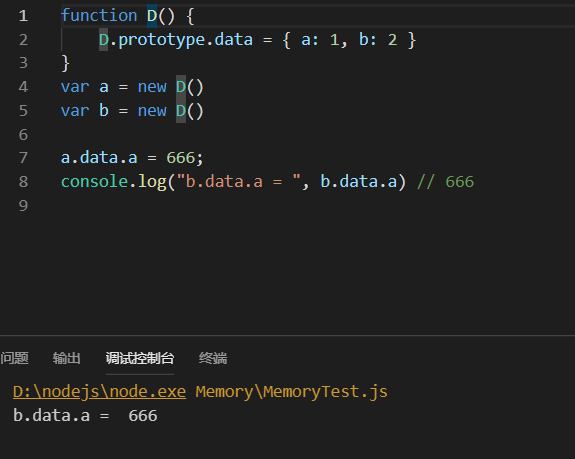
// data是一个对象的时候,共用一套data function D(){ D.prototype.data = {a:1,b:2} var a = new D() var b = new D() a.data.a = 666; console.log("b.data.a = ",b.data.a) // 666 }
执行效果:
代码片段2
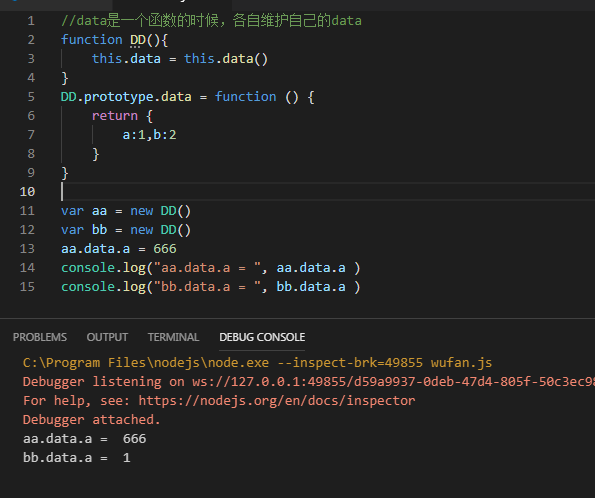
//data是一个函数的时候,各自维护自己的data function DD(){ this.data = this.data() } DD.prototype.data = function () { return { a:1,b:2 } } var aa = new DD() var bb = new DD() aa.data.a = 666 console.log("aa.data.a = ", aa.data.a ) console.log("bb.data.a = ", bb.data.a )
执行效果:
2、函数执行
大家常听说的先定义后执行,其实就是在栈中先开辟一块内存空间,然后在拿到他所对应的值,基本类型去常量池,引用类型去堆拿到他的引用。
为什么引用类型值要放在堆中,而原始类型值要放在栈
在计算机数据结构中,栈比堆的运算速度快,Object是一个复杂的结构且可以扩展:数组可以扩充,对象可以添加属性,将这些引用类型放在堆中是为了不影响栈的效率,而是通过引用的方式查找到堆中的实际对象再进行操作。
先抛出一个问题
function a(){
console.log(2)
};
var a = function(){console.log(1)}; a()
覆盖?那么交换的结果又是什么呢?
var a = function(){
console.log(1)
};
function a(){console.log(2)};
a()
执行效果:

执行效果:

可以看到,两次执行结果都是1
先定义后执行,
先去栈查找
变量提升,
其实也是如此。
先定义(开辟一块内存空间,此时值可以是undefined)后执行(从上到下,该赋值的就赋值,该执行操作的就去操作),就近原则。
下面这段代码;
var a = 10; function() { console.log(a);//undefined var a = 1; console.log(a)//1 }
函数执行时的准确顺序:
var a console.log(a);//undefined a = 1; console.log(a)//1
为什么不出去找全局的a?
因为就近原则。
什么是就近原则?都确定函数内部有定义了,就不会再去外面白费力气。其实是,函数在自己的作用域内找到就不会再再继续找,类似原型链一样,在构造函数里面找到某个属性就不会去原型找,找不到才去,再找不到就再往上。函数也是,沿着作用域链查找。
垃圾回收:
进行前端开发几乎不需要关心内存问题,v8限制的内存几乎不会出现用完的问题,另外,只要关闭了浏览器,一切都结束了。如果是node后端,后端程序往往更加复杂的操作,加上长期运行在服务器不重启,如果不关注内存管理,积少成多就会导致内存泄漏。node中的内存第一个部分和上面还是一样,有栈,堆,运行时环境,另外还有一个缓冲区存放Buffer.你可以通过process.memoryUsage()查看node里面进行内存使用情况。堆中的对象被分为新生代和老生代,它们会被不同的垃圾回收机制清理掉。