ThreadPoolExecutor ProcessPoolExecutor:
从Python3.2开始,标准库为我们提供了 concurrent.futures 模块,它提供了 ThreadPoolExecutor (线程池)和ProcessPoolExecutor (进程池)两个类。
相比 threading 等模块,该模块通过 submit 返回的是一个 future 对象,它是一个未来可期的对象,通过它可以获悉线程的状态主线程(或进程)中可以获取某一个线程(进程)执行的状态或者某一个任务执行的状态及返回值:
1. 主线程可以获取某一个线程(或者任务的)的状态,以及返回值。
2. 当一个线程完成的时候,主线程能够立即知道。
3. 让多线程和多进程的编码接口一致。
concurrent.Futures模块为异步执行可调用程序提供高级接口。
example1:
from concurrent.futures import ThreadPoolExecutor import time # 参数times用来模拟网络请求的时间 def get_html(times): time.sleep(times) print("get page {}s finished".format(times)) return times executor = ThreadPoolExecutor(max_workers=2) # 通过submit函数提交执行的函数到线程池中,submit函数立即返回,不阻塞 task1 = executor.submit(get_html, (3)) task2 = executor.submit(get_html, (2)) # done方法用于判定某个任务是否完成 print(task1.done()) # cancel方法用于取消某个任务,该任务没有放入线程池中才能取消成功 print(task2.cancel()) time.sleep(4) print(task1.done()) # result方法可以获取task的执行结果 print(task1.result()) # 执行结果 # False # 表明task1未执行完成 # False # 表明task2取消失败,因为已经放入了线程池中 # get page 2s finished # get page 3s finished # True # 由于在get page 3s finished之后才打印,所以此时task1必然完成了 # 3 # 得到task1的任务返回值
ThreadPoolExecutor构造实例的时候,传入max_workers参数来设置线程池中最多能同时运行的线程数目。- 使用
submit函数来提交线程需要执行的任务(函数名和参数)到线程池中,并返回该任务的句柄(类似于文件、画图),注意submit()不是阻塞的,而是立即返回。 - 通过
submit函数返回的任务句柄,能够使用done()方法判断该任务是否结束。上面的例子可以看出,由于任务有2s的延时,在task1提交后立刻判断,task1还未完成,而在延时4s之后判断,task1就完成了。 - 使用
cancel()方法可以取消提交的任务,如果任务已经在线程池中运行了,就取消不了。这个例子中,线程池的大小设置为2,任务已经在运行了,所以取消失败。如果改变线程池的大小为1,那么先提交的是task1,task2还在排队等候,这是时候就可以成功取消。 - 使用
result()方法可以获取任务的返回值。查看内部代码,发现这个方法是阻塞的。
as_completed方法一次取出所有任务的结果。from concurrent.futures import ThreadPoolExecutor, as_completed import time # 参数times用来模拟网络请求的时间 def get_html(times): time.sleep(times) print("get page {}s finished".format(times)) return times executor = ThreadPoolExecutor(max_workers=2) urls = [3, 2, 4] # 并不是真的url all_task = [executor.submit(get_html, (url)) for url in urls] for future in as_completed(all_task): data = future.result() print("in main: get page {}s success".format(data)) # 执行结果 # get page 2s finished # in main: get page 2s success # get page 3s finished # in main: get page 3s success # get page 4s finished # in main: get page 4s success
example3:
import concurrent.futures import urllib.request URLS = ['http://www.foxnews.com/', 'http://www.cnn.com/', 'http://europe.wsj.com/', 'http://www.bbc.co.uk/', 'http://some-made-up-domain.com/'] # Retrieve a single page and report the URL and contents def load_url(url, timeout): with urllib.request.urlopen(url, timeout=timeout) as conn: return conn.read() # We can use a with statement to ensure threads are cleaned up promptly with concurrent.futures.ThreadPoolExecutor(max_workers=5) as executor: # Start the load operations and mark each future with its URL future_to_url = {executor.submit(load_url, url, 60): url for url in URLS} for future in concurrent.futures.as_completed(future_to_url): url = future_to_url[future] try: data = future.result() except Exception as exc: print('%r generated an exception: %s' % (url, exc)) else: print('%r page is %d bytes' % (url, len(data)))
as_completed()方法是一个生成器,在没有任务完成的时候,会阻塞,在有某个任务完成的时候,会yield这个任务,就能执行for循环下面的语句,然后继续阻塞住,循环到所有的任务结束。从结果也可以看出,先完成的任务会先通知主线程。example4:map
from concurrent.futures import ThreadPoolExecutor import time # 参数times用来模拟网络请求的时间 def get_html(times): time.sleep(times) print("get page {}s finished".format(times)) return times executor = ThreadPoolExecutor(max_workers=2) urls = [3, 2, 4] # 并不是真的url for data in executor.map(get_html, urls): print("in main: get page {}s success".format(data)) # 执行结果 # get page 2s finished # get page 3s finished # in main: get page 3s success # in main: get page 2s success # get page 4s finished # in main: get page 4s success
map方法,无需提前使用submit方法,map方法与python标准库中的map含义相同,都是将序列中的每个元素都执行同一个函数。上面的代码就是对urls的每个元素都执行get_html函数,并分配各线程池。可以看到执行结果与上面的as_completed方法的结果不同,输出顺序和urls列表的顺序相同,就算2s的任务先执行完成,也会先打印出3s的任务先完成,再打印2s的任务完成from concurrent.futures import ThreadPoolExecutor, wait, ALL_COMPLETED, FIRST_COMPLETED import time # 参数times用来模拟网络请求的时间 def get_html(times): time.sleep(times) print("get page {}s finished".format(times)) return times executor = ThreadPoolExecutor(max_workers=2) urls = [3, 2, 4] # 并不是真的url all_task = [executor.submit(get_html, (url)) for url in urls] wait(all_task, return_when=ALL_COMPLETED) print("main") # 执行结果 # get page 2s finished # get page 3s finished # get page 4s finished # main
wait方法接收3个参数,等待的任务序列、超时时间以及等待条件。等待条件return_when默认为ALL_COMPLETED,表明要等待所有的任务都结束。可以看到运行结果中,确实是所有任务都完成了,主线程才打印出main。等待条件还可以设置为FIRST_COMPLETED,表示第一个任务完成就停止等待。

1 # Copyright 2009 Brian Quinlan. All Rights Reserved. 2 3 # Licensed to PSF under a Contributor Agreement. 4 5 6 7 """Implements ThreadPoolExecutor.""" 8 9 10 11 __author__ = 'Brian Quinlan (brian@sweetapp.com)' 12 13 14 15 import atexit 16 17 from concurrent.futures import _base 18 19 import itertools 20 21 import queue 22 23 import threading 24 25 import weakref 26 27 import os 28 29 30 31 # Workers are created as daemon threads. This is done to allow the interpreter 32 33 # to exit when there are still idle threads in a ThreadPoolExecutor's thread 34 35 # pool (i.e. shutdown() was not called). However, allowing workers to die with 36 37 # the interpreter has two undesirable properties: 38 39 # - The workers would still be running during interpreter shutdown, 40 41 # meaning that they would fail in unpredictable ways. 42 43 # - The workers could be killed while evaluating a work item, which could 44 45 # be bad if the callable being evaluated has external side-effects e.g. 46 47 # writing to a file. 48 49 # 50 51 # To work around this problem, an exit handler is installed which tells the 52 53 # workers to exit when their work queues are empty and then waits until the 54 55 # threads finish. 56 57 58 59 _threads_queues = weakref.WeakKeyDictionary() 60 61 _shutdown = False 62 63 64 65 def _python_exit(): 66 67 global _shutdown 68 69 _shutdown = True 70 71 items = list(_threads_queues.items()) 72 73 for t, q in items: 74 75 q.put(None) 76 77 for t, q in items: 78 79 t.join() 80 81 82 83 atexit.register(_python_exit) 84 85 86 87 88 89 class _WorkItem(object): 90 91 def __init__(self, future, fn, args, kwargs): 92 93 self.future = future 94 95 self.fn = fn 96 97 self.args = args 98 99 self.kwargs = kwargs 100 101 102 103 def run(self): 104 105 if not self.future.set_running_or_notify_cancel(): 106 107 return 108 109 110 111 try: 112 113 result = self.fn(*self.args, **self.kwargs) 114 115 except BaseException as exc: 116 117 self.future.set_exception(exc) 118 119 # Break a reference cycle with the exception 'exc' 120 121 self = None 122 123 else: 124 125 self.future.set_result(result) 126 127 128 129 130 131 def _worker(executor_reference, work_queue, initializer, initargs): 132 133 if initializer is not None: 134 135 try: 136 137 initializer(*initargs) 138 139 except BaseException: 140 141 _base.LOGGER.critical('Exception in initializer:', exc_info=True) 142 143 executor = executor_reference() 144 145 if executor is not None: 146 147 executor._initializer_failed() 148 149 return 150 151 try: 152 153 while True: 154 155 work_item = work_queue.get(block=True) 156 157 if work_item is not None: 158 159 work_item.run() 160 161 # Delete references to object. See issue16284 162 163 del work_item 164 165 continue 166 167 executor = executor_reference() 168 169 # Exit if: 170 171 # - The interpreter is shutting down OR 172 173 # - The executor that owns the worker has been collected OR 174 175 # - The executor that owns the worker has been shutdown. 176 177 if _shutdown or executor is None or executor._shutdown: 178 179 # Flag the executor as shutting down as early as possible if it 180 181 # is not gc-ed yet. 182 183 if executor is not None: 184 185 executor._shutdown = True 186 187 # Notice other workers 188 189 work_queue.put(None) 190 191 return 192 193 del executor 194 195 except BaseException: 196 197 _base.LOGGER.critical('Exception in worker', exc_info=True) 198 199 200 201 202 203 class BrokenThreadPool(_base.BrokenExecutor): 204 205 """ 206 207 Raised when a worker thread in a ThreadPoolExecutor failed initializing. 208 209 """ 210 211 212 213 214 215 class ThreadPoolExecutor(_base.Executor): 216 217 218 219 # Used to assign unique thread names when thread_name_prefix is not supplied. 220 221 _counter = itertools.count().__next__ 222 223 224 225 def __init__(self, max_workers=None, thread_name_prefix='', 226 227 initializer=None, initargs=()): 228 229 """Initializes a new ThreadPoolExecutor instance. 230 231 232 233 Args: 234 235 max_workers: The maximum number of threads that can be used to 236 237 execute the given calls. 238 239 thread_name_prefix: An optional name prefix to give our threads. 240 241 initializer: A callable used to initialize worker threads. 242 243 initargs: A tuple of arguments to pass to the initializer. 244 245 """ 246 247 if max_workers is None: 248 249 # Use this number because ThreadPoolExecutor is often 250 251 # used to overlap I/O instead of CPU work. 252 253 max_workers = (os.cpu_count() or 1) * 5 254 255 if max_workers <= 0: 256 257 raise ValueError("max_workers must be greater than 0") 258 259 260 261 if initializer is not None and not callable(initializer): 262 263 raise TypeError("initializer must be a callable") 264 265 266 267 self._max_workers = max_workers 268 269 self._work_queue = queue.SimpleQueue() 270 271 self._threads = set() 272 273 self._broken = False 274 275 self._shutdown = False 276 277 self._shutdown_lock = threading.Lock() 278 279 self._thread_name_prefix = (thread_name_prefix or 280 281 ("ThreadPoolExecutor-%d" % self._counter())) 282 283 self._initializer = initializer 284 285 self._initargs = initargs 286 287 288 289 def submit(*args, **kwargs): 290 291 if len(args) >= 2: 292 293 self, fn, *args = args 294 295 elif not args: 296 297 raise TypeError("descriptor 'submit' of 'ThreadPoolExecutor' object " 298 299 "needs an argument") 300 301 elif 'fn' in kwargs: 302 303 fn = kwargs.pop('fn') 304 305 self, *args = args 306 307 else: 308 309 raise TypeError('submit expected at least 1 positional argument, ' 310 311 'got %d' % (len(args)-1)) 312 313 314 315 with self._shutdown_lock: 316 317 if self._broken: 318 319 raise BrokenThreadPool(self._broken) 320 321 322 323 if self._shutdown: 324 325 raise RuntimeError('cannot schedule new futures after shutdown') 326 327 if _shutdown: 328 329 raise RuntimeError('cannot schedule new futures after ' 330 331 'interpreter shutdown') 332 333 334 335 f = _base.Future() 336 337 w = _WorkItem(f, fn, args, kwargs) 338 339 340 341 self._work_queue.put(w) 342 343 self._adjust_thread_count() 344 345 return f 346 347 submit.__doc__ = _base.Executor.submit.__doc__ 348 349 350 351 def _adjust_thread_count(self): 352 353 # When the executor gets lost, the weakref callback will wake up 354 355 # the worker threads. 356 357 def weakref_cb(_, q=self._work_queue): 358 359 q.put(None) 360 361 # TODO(bquinlan): Should avoid creating new threads if there are more 362 363 # idle threads than items in the work queue. 364 365 num_threads = len(self._threads) 366 367 if num_threads < self._max_workers: 368 369 thread_name = '%s_%d' % (self._thread_name_prefix or self, 370 371 num_threads) 372 373 t = threading.Thread(name=thread_name, target=_worker, 374 375 args=(weakref.ref(self, weakref_cb), 376 377 self._work_queue, 378 379 self._initializer, 380 381 self._initargs)) 382 383 t.daemon = True 384 385 t.start() 386 387 self._threads.add(t) 388 389 _threads_queues[t] = self._work_queue 390 391 392 393 def _initializer_failed(self): 394 395 with self._shutdown_lock: 396 397 self._broken = ('A thread initializer failed, the thread pool ' 398 399 'is not usable anymore') 400 401 # Drain work queue and mark pending futures failed 402 403 while True: 404 405 try: 406 407 work_item = self._work_queue.get_nowait() 408 409 except queue.Empty: 410 411 break 412 413 if work_item is not None: 414 415 work_item.future.set_exception(BrokenThreadPool(self._broken)) 416 417 418 419 def shutdown(self, wait=True): 420 421 with self._shutdown_lock: 422 423 self._shutdown = True 424 425 self._work_queue.put(None) 426 427 if wait: 428 429 for t in self._threads: 430 431 t.join() 432 433 shutdown.__doc__ = _base.Executor.shutdown.__doc__
cocurrent.future模块中的future的意思是未来对象,可以把它理解为一个在未来完成的操作,这是异步编程的基础 。在线程池submit()之后,返回的就是这个future对象,返回的时候任务并没有完成,但会在将来完成。也可以称之为task的返回容器,这个里面会存储task的结果和状态。那ThreadPoolExecutor内部是如何操作这个对象的呢?
下面简单介绍ThreadPoolExecutor的部分代码:
-
init方法


init方法中主要重要的就是任务队列和线程集合,在其他方法中需要使用到。 -
submit方法
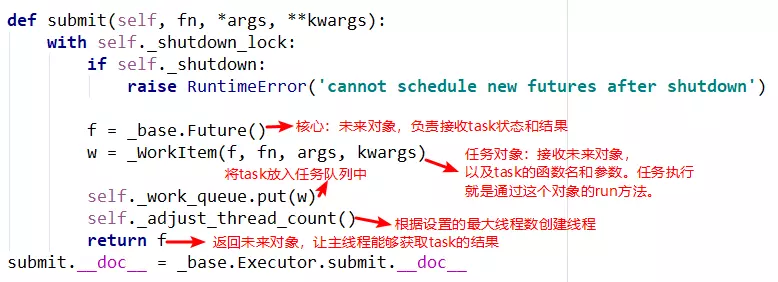

submit中有两个重要的对象,_base.Future()和_WorkItem()对象,_WorkItem()对象负责运行任务和对future对象进行设置,最后会将future对象返回,可以看到整个过程是立即返回的,没有阻塞。 -
adjust_thread_count方法

 这个方法的含义很好理解,主要是创建指定的线程数。但是实现上有点难以理解,比如线程执行函数中的weakref.ref,涉及到了弱引用等概念,留待以后理解。
这个方法的含义很好理解,主要是创建指定的线程数。但是实现上有点难以理解,比如线程执行函数中的weakref.ref,涉及到了弱引用等概念,留待以后理解。 -
_WorkItem对象


_WorkItem对象的职责就是执行任务和设置结果。这里面主要复杂的还是self.future.set_result(result)。 -
线程执行函数--_worker

 这是线程池创建线程时指定的函数入口,主要是从队列中依次取出task执行,但是函数的第一个参数还不是很明白。留待以后。
这是线程池创建线程时指定的函数入口,主要是从队列中依次取出task执行,但是函数的第一个参数还不是很明白。留待以后。




 这是线程池创建线程时指定的函数入口,主要是从队列中依次取出task执行,但是函数的第一个参数还不是很明白。留待以后。
这是线程池创建线程时指定的函数入口,主要是从队列中依次取出task执行,但是函数的第一个参数还不是很明白。留待以后。