一.where和having
1.where 后不能跟聚合函数,因为where执行顺序大于聚合函数。
2. where 子句的作用是在对查询结果进行分组前,将不符合where条件的行去掉,即在分组之前过滤数据,条件中不能包含聚组函数,使用where条件显示特定的行。
3.having 子句的作用是筛选满足条件的组,即在分组之后过滤数据,条件中经常包含聚组函数,使用having 条件显示特定的组,也可以使用多个分组标准进行分组。
二.视图
1.概念
-
视图是一种虚拟存在的表,行和列的数据来自自定义视图的查询中使用的表,并且在使用视图时动态生成的,只保存SQL的逻辑,不保存查询结果。
2.应用场景
-
多个地方用到同样的查询结果
-
该查询结果使用的SQL语句比较复杂
3.使用
(1)创建视图
-
语法:
create view 视图名 as 查询语句;
-
例子:
# 查询邮箱中包含a字符的员工名、部门名和工种信息 # 创建 create view myv1 as select last_name,department_name,job_title from employees e join departments d on e.department_id = d.department_id join jobs j on j.job_id = e.job_id; #使用 select * from myv1 where last_name like '%a%';
(2)修改视图
-
方式一:
-
语法:
create or replace view 视图名 as 查询语句;
-
例子:
create or replace view myv3 as select AVG(salary) , job_id from employees group by job_id;
-
-
方式二:
-
语法:
alter view 视图名 as 查询语句;
-
例子:
alter view myv3 as select * from employees;
-
(3)删除视图
-
语法:
drop view 视图名1, 视图名2, ...;
-
例子:
drop view myv1,myv2,myv3;
(4)查看视图
-
方式一:
desc myv3; -
方式二:
show create view myv3;
4.视图的好处
-
重用SQL语句
-
简化复杂的SQL操作,不必知道它的查询细节
-
保护数据,提高安全性
三.SQL执行顺序
1.手写顺序
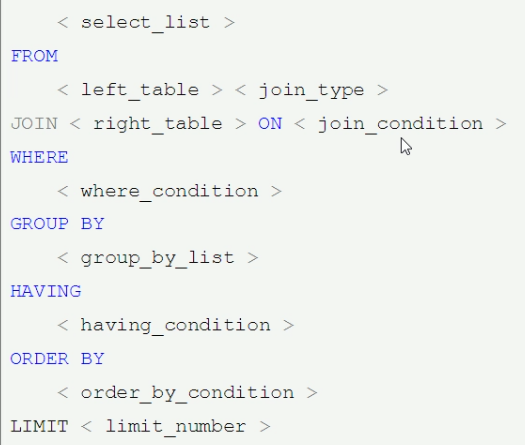
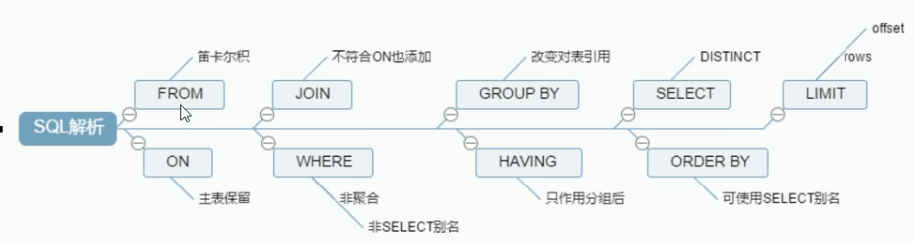
2.机器读顺序

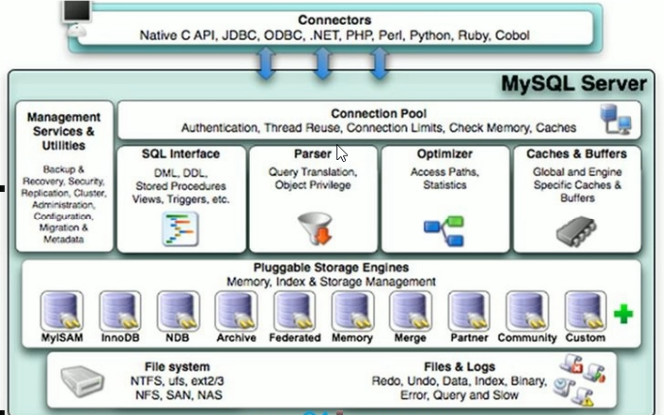
四.MySQL逻辑架构简介
-
和其他数据库相比,MySQL与众不同。它的架构可以在多种不同场景中应用并发挥良好作用。主要体现在存储引擎的架构上。插件式的存储引擎架构将查询处理和其他的系统以及数据的存储提取相分离。这种架构可以根据业务的需求和实际需要选择合适的存储引擎。
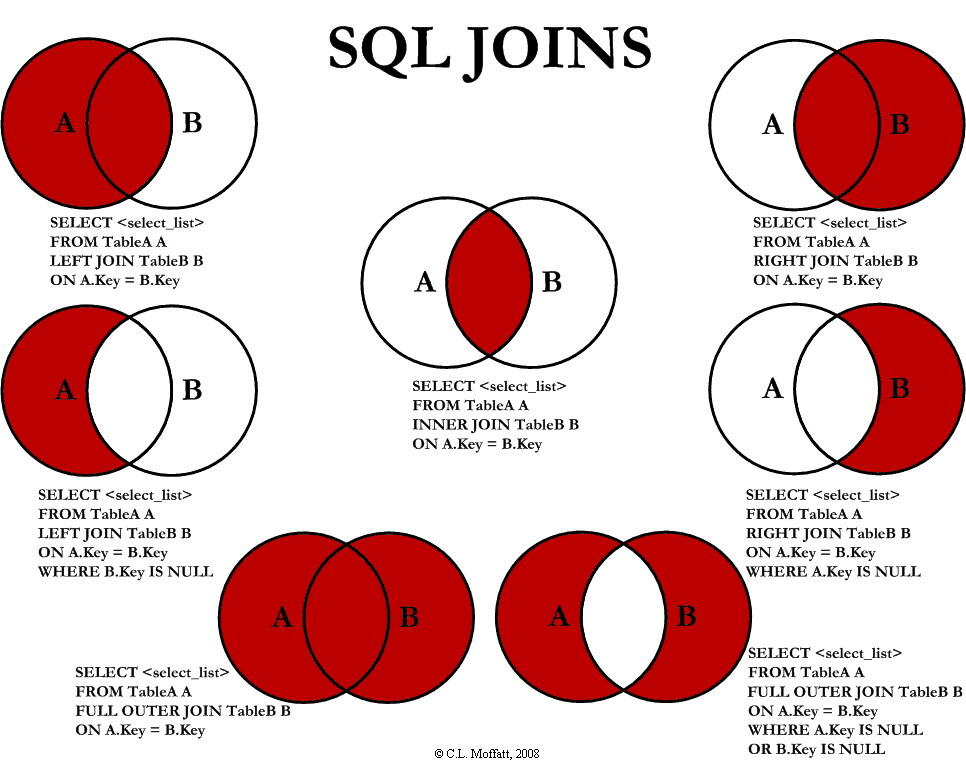
五.SQL-JIONS
六.索引
1.概念
-
索引是一种高效获取数据的数据结构
-
除了数据本身之外,数据库还维护着一个满足特定查找算法的数据结构,这些数据结构以某种方式指向数据,这样就可以在这些数据结构的基础上实现高级查找算法,这种数据结构是索引。
-
一般来说索引本身也很大,不能全部存储在内存中,因此索引往往以索引文件的形式存储在磁盘上
-
我们平时说的索引没有特别指明一般都是B树
2.优势
-
提高数据检索的效率,降低数据库的IO成本
-
通过索引列对数据进行排序,降低数据排序的成本,降低CPU的消耗
3.劣势
-
多占用了内存空间
-
索引提高了查询速度,降低了更新速度
-
根据业务变化,要改变索引建立更加优化的索引
4.索引的分类
-
单值索引:一个索引只包含单个列,一个表可以有多个单列索引
-
唯一索引:索引列的值必须唯一,但是允许有空值
-
复合索引:一个索引包含多个列
-
基本语法:
-
创建:
-
创建语法: create [unique] index indesName on tableName(columnName1,....);
-
例子:
create index UQ_Clu_StuNo --索引名称 on Student(S_StuNo); --数据表名称(建立索引的列名)
-
添加语法: alter tableName add [unique] index [indexName] on (columnName1,...);
-
-
删除: drop index [indexName] on tableName;
-
查看: show index [indexName] on tableNameG;
-
使用alter命令:

-
5.索引结构:
-
BTree索引
-
Hash索引
-
full-text索引
-
R-Tree索引
6.需要建立索引的情况

7.不需要创建索引的情况
