“反向传播”是最小化成本函数的神经网络术语,就像我们在logistic回归和线性回归中的梯度下降一样。我们的目标是计算:
![]()
也就是说,我们希望在θ中使用一组最优参数来最小化我们的成本函数j。在这一节中我们将看看我们用来计算J(Θ)的偏导数方程:
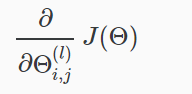
为此,我们使用下面的算法:

反向传播算法实现:
1.得到训练集![]()
2.设置![]() 所有i,j,l(因此你最终有一个矩阵全零)
所有i,j,l(因此你最终有一个矩阵全零)
3.遍历训练样本t = 1到m:
(1)![]()
(2)进行正向传播计算a(j) j从1到m;
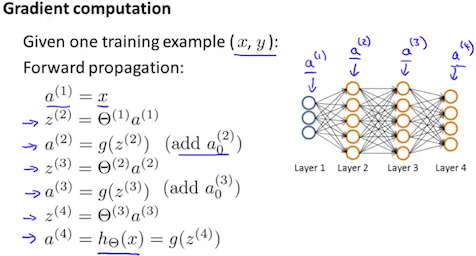
(3)使用y(t),计算![]()
其中L是我们的总层数,而a(l)是最后一层激活单元的输出向量。所以我们最后一层的“误差值”仅仅是我们最后一层的实际结果和y中的正确输出的差值:
(4)![]()
计算出每一层的每个节点的误差
然后我们使用函数,称为G或G-Prime,这是激励函数g评价与输入值的Z(L)。
了G-Prime导数项也可以写出来:
![]()
(5)![]() 或用矢量化
或用矢量化![]() 、
、
因此我们更新我们的新Δ矩阵。
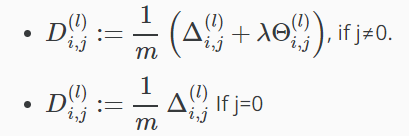
矩阵D作为一个“累加器”来增加我们的价值,因为我们去,并最终计算我们的偏导数。
![]()