郑昀 201007
原标题:Working on Sentiment Analysis on Twitter with Portuguese Language
原作者:Artificial Intelligence in Motion
原作发表日期:2010年7月20日
原文地址:http://aimotion.blogspot.com/2010/07/working-on-sentiment-analysis-on.html
虽然是讲葡萄牙语下的情感分析,但作为一个入门指导也有可看之处。
摘要翻译如下:
情感分析(Sentiment Analysis,缩写SA)是基于互联网上发布的内容,辨识出人们对某事物的感情或者感觉,如某个产品、公司、地点、人。这种分析方式最终可能会得到一份完整的报告,描述人们对于一个事物的看法,而不需要你寻找并阅读相关的所有意见和新闻。
在机器学习领域,情感分析属于文本分类问题,它需要检测关于某一个特定主题(topic)的正负面意见。挑战主要是,识别文本中各种情感是如何表达的,它们是否是正面或负面意见。
下面列出一些情感分析应用:
公司股票领域的SA:通过对分析人士的意见进行处理和汇总,尝试预测股价的趋势;
产品的SA:一个公司可能会对他们的顾客如何评价某一个产品感兴趣。比如,Google会使用情感挖掘(Sentiment Mining)技术来获知人们如何谈论Android手机Nexus One,它们会被用来促进产品的改进甚至新销售政策。
地点(Places)的SA:一个要出去旅游的人可能想知道最好的游玩地点或者最好的餐馆。意见挖掘(Opinion Mining)可能会帮这些人推荐好的places。
竞选(Elections)的SA:投票者可以用SA来统计其他投票者对某一个候选人的态度。
游戏和电影的SA。
另一个SA应用是分析社会化网络中的状态信息,如Twitter或Facebook。
在这个领域有不少工具,但多数只能处理英文tweets,对于其他语言的往往会分错正负面。
这是一个新领域,特别是处理葡萄牙语时,所以我决定开发一个简单的SA工具来处理tweets。我将使用一个常见的简单的机器学习技术“朴素贝叶斯 Naive Bayes”,来分类tweets影评。
SA如何工作?都需要哪些步骤呢?
1、数据收集和预处理:重要的是,要删除那些仅仅表述事实却没有意见表达的条目。要把注意力集中在用户的意见上。
2、分类(Classification):一般是三个分类:正面(positive)、负面(negative)、中性(neutral)。
3、结果的展现:在这一步里,几种意见的分类必须被归纳好,以便展示。目的是便于理解人们是怎么谈论一个事物的,可以用图形或文字展现。
第一步,数据收集和预处理
需要先提取出文本中的关键词,这些词能让你正确地分类,把它们储存为特征向量(Feature Vector)的形式,F=(f1,f2,…fn)。一个特征向量的每一个坐标代表一个词(word),也被叫做(原文的)特征。
每一个特征的值可能是一个二进制数值,表明这个特征有还是没有,一个整型数可以进一步表示原文中该特征的强度(intensity)。
一定要选择一组好的特征,因为它将影响到随后的机器学习过程。
选择好的特征,需要靠着我们的直觉,垂直领域的知识以及大量的实验。
我们的处理方法包含词袋(Bag of words)的使用。(译注:在信息检索中,Bag of words model假定对于一个文本,忽略其词序和语法,句法,将其仅仅看做是一个词集合,或者说是词的一个组合,文本中每个词的出现都是独立的(unigrams),不依赖于其他词是否出现,或者说当这篇文章的作者在任意一个位置选择一个词汇都不受前面句子的影响而独立选择的。这种假定有时候是不合理的。)这个方法的挑战在于,如何选择适合成为特征的词。
例如,就这个模型而言,“今天我看了电影《暮光之城》,很美丽”,那么可以表达为特征向量:
F={'今天':1,'我':1,'看':1,'电影':1,'暮光之城:1,'很':1,'美丽':1,}
这里我把特征向量表述为一个python的字典。
显然,在实际应用中,一个特征向量将会有大量的词,这种模型将会非常低效。
一个做法是手动选择最重要的关键词,比如“美丽的”(形容词)很好地指明了作者的意见。最重要的词如“优秀”“可怕”都可以被选为特征。但Pang et al.的论文表明手动选词已经被统计模型(statistical models)胜过,该模型是根据在已有的训练语料(corpus)词的出现几率来选择一组词作为特征。这样,选择的质量就依赖于语料的多少,以及某垂直领域训练和测试数据的相似度。
当语料中混杂了不同垂直领域的文本,而它们又和我们要分类的领域没有什么共同特性,那么就会导致不正确的结果。
还需要建立一个停止词表,保存一些没什么用的词,如代词、介词等。
这个模型有局限性,它不能了解词之间的句法关系以及一个词的不同含义。
第二步,分类
分类算法对于SA任务来说是成熟的。
在分类一个新tweet前,需要有一个被标记过的训练集(training set)。训练集的数据需要标记出句子的主观性(subjectivity,即判断这个句子是一个事实的陈述,还是一个意见的表达)和倾向性(polarity)。本文用的是最简单但非常高效的一种机器学习技术:朴素贝叶斯(Naive Bayes,缩写NB)。
朴素贝叶斯模型或者朴素贝叶斯分类器是一个简单的概率分类器。它假定一个特征值对给定分类的影响独立于其他特征值。比如一辆小轿车可以被认为是一个交通工具,如果它有四个轮子,一个引擎,至少两个门。即使这些特征互相依赖,但朴素贝叶斯分类器就是认为这些特征独立地贡献概率。
在我们这儿,tweet中的每一个词都被当成一个独特变量,目的是发现词属于某一个特定类(正面还是负面)的概率。尽管有朴素的设计和简化的假定,但朴素贝叶斯分类器在很多复杂的真实环境里工作得非常好。最常用的就是垃圾过滤。实际上,最流行的包之一SpamAssassin就是用的NB算法。
我用的是Naive Bayesian Classifier的一个简单Python实现。
我们先要训练分类器,所以要创建一个把tweets(或words)已经分好类(分为正负面)的训练集。
第三步,Summarization
最后一步,结果展现。
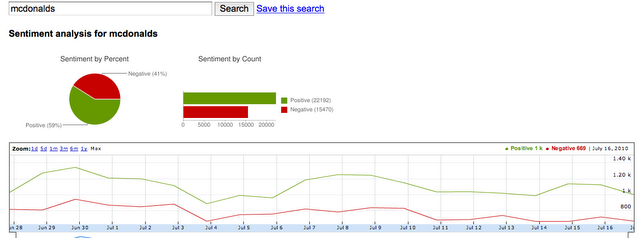
Summarization by TwitterSentiment Analyzer - http://twittersentiment.appspot.com/
我们研究领域:Twitter上的影评
我将提供工程的所有源代码。目前WebService可以像这样请求,返回的格式是JSON:
http://mobnip.appspot.com/api/sentiment/classify?text=Encontro+Explosivo+filme+ruim+Danado&query=encontro+explosivo (注意,它只支持葡萄牙语。查询的电影是危情谍战Knight and Day。)
返回的结果是:
{"results": {"polarity": "negativo", "text": "Encontro Explosivo filme ruim Danado", "query": "encontro explosivo"}}
也就是负面的表达。
小结:
我们可以注意到情感分析是互联网的一个趋势,你可以从微博客或Social networks获得大量包含了意见的数据。
我觉得主观性识别(subjectivity identification,即判断一个文本是一个意见还是事实陈述),和讽刺的识别,是很难做的。拼写错误的词和缩写词,常见于博客和社会化网络,在搜索和分类时,也是大麻烦。