字符串是软件开发中最常用的对象,通常,String对象或者其等价的char数组对象,在内存中总是占据了最大的空间快。所以如何高效地处理字符串必将是提高系统整体性能的关键。
一:String对象及其特点
String对象是java里重要的数据类型,其实不光是java,笔者最近写python等语言也大量的运用了String,不过本文只讲java中的String特性;
在c语言里,处理字符串都是直接操作char数组,这种做法弊端很明显,无法封装字符串操作的基本方法,java在很多地方都是封装的牛逼,String对象在java里主要由三部分组成:char数组,偏移量和String的长度。
如图(JDK的String源码):

char数组表示String的内容,它是String对象所表示字符串的超集,String的真实内容需要由偏移量和长度在这个char数组里面进行定位和截取,理解这点很重要,有助于更好的理解接下来要阐述的String.subString()方法导致内存泄漏的问题,
java设计者在当前的高级JDK版本中,已经做了大量的优化,主要表现在以下方面:
1.不变性;
2.针对常量池的优化;
3.类的final定义;
(1)不变性:
指的是String对象一旦生成,不能再对它进行改变,这种模式的最大好处是当一个对象被多线程共享,并且访问频繁时,可以省略同步和锁等待的时间,从而大幅度提高性能,这也是一种设计模式,叫不变模式。
实例:
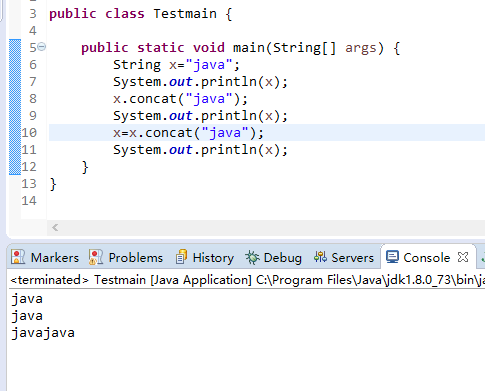
上面代码很好说明了不变性,改变的只是内存地址,内容不会变,任何操作都是产生新的实例。
(2)常量池的优化
针对常量池的优化就是说当两个String对象拥有相同的内容时,它们只引用常量池的同一个拷贝,当一个字符串反复出现的时候,这个特性会大幅度节省内存空间。
实例:

上面的代码分析:str1和str2引用了相同的地址,而str3开辟了新的内存空间,但是常量池的位置和str1是一样的,也就是说虽然str3单独的占用了堆空间,但是它所指向的实体和str1一模一样,最后一行的intern()方法返回的是String对象在常量池的引用。
(3)类的final定义
final修饰的类俗称太监类,不可能有任何子类,这是对系统安全性的保护,在JDK5之前,使用final有助于帮助虚拟机寻找机会内联所有的final方法提高系统效率,但是在JDK5之后,效果并不明显。
二:subString()方法可能导致内存泄漏
源码:

测试代码:
1 public class Testmain { 2 3 public static void main(String[] args) { 4 List<String> handler = new ArrayList<String>(); 5 for (int i = 0; i < 1000; i++) { 6 BadStr str = new BadStr(); 7 // GoodStr str = new GoodStr(); 8 handler.add(str.getSubString(1, 5)); 9 } 10 } 11 12 static class BadStr { 13 private String str = new String(new char[100000]); 14 15 public String getSubString(int begin, int end) { 16 return str.substring(begin, end); 17 } 18 } 19 20 static class GoodStr { 21 private String str = new String(new char[100000]); 22 23 public String getSubString(int begin, int end) { 24 return new String(str.substring(begin, end)); 25 } 26 } 27 }
subString()的源码可以看出,这是个包作用域的构造函数,以偏移量来截取字符串,如果原始字符串很大,而截取的很短,那么截取的字符串中包含了对原生字符串的所有内容。,并占据了相应的内存空间,而仅仅通过偏移量和长度决定自己的实际取值,这汇总方法提高了运算速度却浪费了大量的内存空间,典型的以时间换空间策略;
所以以上的测试代码,BadStr产生了内存泄漏,GC日志打印发现GC很不稳定,最后几次FULLGC几乎没有释放任何内存,而GoodStr表现良好是因为每次都new的新的对象,substring()返回的存在内存泄漏的对象就失去了强引用而被GC垃圾回收,就保证了系统的稳定,不过由于是包内私有的构造,程序不会调用,因此在实际使用中不用担心它带来的麻烦,不过我们仍然要警惕java.lang包的对象对substring的调用可能引发内存泄漏;
三:字符串分割和查找
1 public class Testmain { 2 3 public static void main(String[] args) { 4 String orgStr = null; 5 StringBuffer sb = new StringBuffer(); 6 for (int i = 0; i < 1000; i++) { 7 sb.append(i); 8 sb.append(";"); 9 10 } 11 orgStr = sb.toString(); 12 for (int i = 0; i < 10000; i++) { 13 orgStr.split(";"); 14 } 15 } 16 17 }
以上代码是最普通的split()方法,在我的计算机上显示运行时间为3703ms,有没有更快的方法呢,来看一下StringTokenizer类
备注:String.split()虽然使用简单功能强大,但是在性能敏感的系统里频繁使用这个方法是不可取的。
1 public class Testmain { 2 3 public static void main(String[] args) { 4 String orgStr = null; 5 StringBuffer sb = new StringBuffer(); 6 for (int i = 0; i < 1000; i++) { 7 sb.append(i); 8 sb.append(";"); 9 10 } 11 orgStr = sb.toString(); 12 13 StringTokenizer st = new StringTokenizer(orgStr, ";"); 14 for (int i = 0; i < 10000; i++) { 15 while (st.hasMoreTokens()) { 16 st.nextToken(); 17 } 18 st = new StringTokenizer(orgStr, ";"); 19 } 20 } 21 22 }
以上代码执行时间为2704ms,即使这段代码不断销毁创建对象,还是比split效率高、
更优化的字符串分割方式:
1 public class Testmain { 2 3 public static void main(String[] args) { 4 String orgStr = null; 5 StringBuffer sb = new StringBuffer(); 6 for (int i = 0; i < 1000; i++) { 7 sb.append(i); 8 sb.append(";"); 9 10 } 11 orgStr = sb.toString(); 12 13 String temp = orgStr; 14 for (int i = 0; i < 10000; i++) { 15 while (true) { 16 String splitStr = null; 17 int j = temp.indexOf(";"); 18 if (j < 0) 19 break; 20 splitStr = temp.substring(0, j); 21 temp = temp.substring(j + 1); 22 23 } 24 temp = orgStr; 25 } 26 } 27 28 }
以上的自定义算法,仅用了671ms就搞定了同样的测试代码,这个例子说明indexof和substring执行速度非常快,很适合作为高频函数使用。
以上三种方法对比,在能够使用StringTokenizer的模块中就没有必要使用split,而自己定义的算法不好维护,可读性也很差。
另外用cahrAt()方法性能也显著高于startWith和endWith();
四:StringBuffer和StringBuider
由于String对象的不可变性,因此,在需要对字符串进行修改操作时,总是会生成新的对象,所以性能较差,为此,JDK专门出了用于修改String的工具类,StringBuffer和StringBuider类。
对于String直接操作和StringBuffer操作来说,有以下几个有意思的地方。
1 String result = "String" + "and" + "String" + "append"; 2 StringBuffer buffer = new StringBuffer(); 3 buffer.append("String"); 4 buffer.append("and"); 5 buffer.append("String"); 6 buffer.append("append");
如图,其实这两种方式去拼接字符串,看似String直接操作性能低一些,但是循环5万次这个代码,第一种拼接方式耗时0ms,第二段代码耗时15ms,其实String常量字符串的累加,在编译器就充分的优化了,编译器就能确定的取值,在编译器就可以做计算了,而反编译之后发现StringBuffer对象和append方法都被如是调用,所以第一段代码效率才这么高。
那么如果是字符串都用变量接收,再用变量相加,编译器就无法在运行时确定取值,同样运行5万次,发现两种方法耗时一样,反编译发现,直接操作String相加也是调用了StringBuffer的append方法,底层来说两者都是用了StringBuffer处理字符串拼接。
但是有意思的是,String的底层拼接调用StringBuffer是不断的new新的StringBuffer,所以编译器还是不够聪明,构造特大的String时,这种性能就远低于维护一个StringBuffer实例,所以String的操作中应该少用+ -等符号,使用StringBuffer。
StringBuffer和StringBuilder的选择:
StringBuilder是异步的,线程不安全。
StringBuffer同步,线程安全。
还有最后一点就是StringBuffer和Builder的使用,最好是能预估容量大小,使用带容量参数的构造,这样能够避免很多的扩容,频繁的扩容操作会带来数组的频繁复制,频繁内存空间的申请,带来性能的问题
其它的String方面的小方法,在另外一篇博文里也有介绍