概述
每个分区有n个副本,可以承受n-1个节点故障。
每个副本都有自己的leader,其余都是follower。
zk中存放分区的leader和 follower replica的信息。(get /brokers/topics/mytest2/partitions/0/state)
每个副本存储消息的部分数据在本地的log和offset中,周期性同步到disk,确保消息写入全部副本或不写入任何一个。
leader故障时,消息或者在写入本地log,或者在producer收到ack消息前,resent partition到new leader。
kafka支持的副本模型
a)同步复制:producer从zk中找leader,并发送消息,消息立即写入本地log,而且follower开始pull消息。每个follower将消息写入各自的log后,向leader发送确认回执,leader在本地副本的写入工作均完成并且收到所有follower的确认回执后,再向producer发送确认回执。
b)异步复制:leader的本地log写入完成后即向producer发送确认回执。
原文——摘自《[PACKT]Apache Kafka.pdf》
Replication in Kafka
Before we talk about replication in Kafka, let's talk about message partitioning.In Kafka, message partitioning strategy is used at the Kafka broker end. The decisionabout how the message is partitioned is taken by the producer, and the broker storesthe messages in the same order as they arrive. The number of partitions can beconfigured for each topic within the Kafka broker.
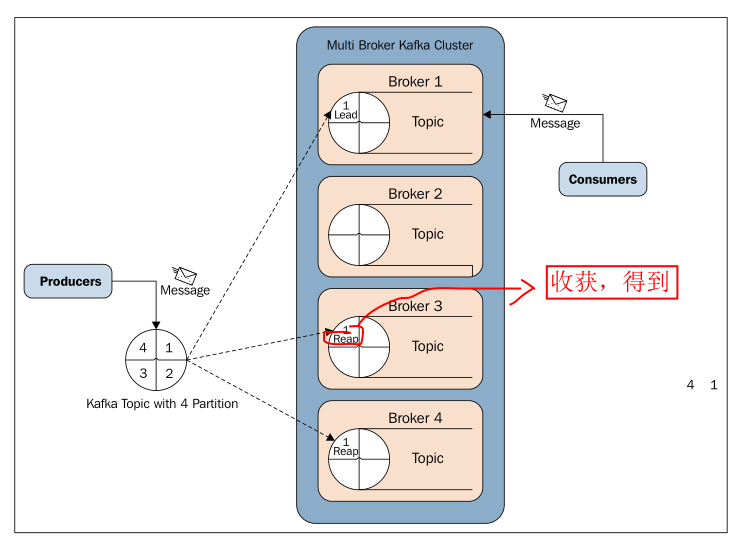
Kafka replication is one of the very important features introduced in Kafka 0.8.Though Kafka is highly scalable, for better durability of messages and high availability of Kafka clusters, replication guarantees that the message will be published and consumed even in case of broker failure, which may be caused by any reason. Here, both producers and consumers are replication aware in Kafka.The following diagram explains replication in Kafka:
Let's discuss the preceding diagram in detail.
In replication, each partition of a message has n replicas and can afford n-1 failures to guarantee message delivery. Out of the n replicas, one replica acts as the lead replica for the rest of the replicas. ZooKeeper keeps the information about the lead replica and the current in-sync follower replica (lead replica maintains the list of all in-sync follower replicas).
Each replica stores its part of the message in local logs and offsets, and is periodically synced to the disk. This process also ensures that either a message is written to all the replicas or to none of them.
If the lead replica fails, either while writing the message partition to its local log or before sending the acknowledgement to the message producer, a message partition is resent by the producer to the new lead broker.
The process of choosing the new lead replica is that all followers' In-sync Replicas (ISRs) register themselves with ZooKeeper. The very first registered replica becomes the new lead replica, and the rest of the registered replicas become the followers.
Kafka supports the following replication modes:
• Synchronous replication: In synchronous replication, a producer first identifies the lead replica from ZooKeeper and publishes the message.As soon as the message is published, it is written to the log of the lead replica and all the followers of the lead start pulling the message, and by using a single channel,the order of messages is ensured. Each follower replica sends an acknowledgement to the lead replica once the message is written to its respective logs. Once replications are complete and all expected acknowledgements are received, the lead replica sends an acknowledgement to the producer.On the consumer side, all the pulling of messages is done from the lead replica.
• Asynchronous replication: The only difference in this mode is that as soon as a lead replica writes the message to its local log, it sends the acknowledgement to the message client and does not wait for the acknowledgements from follower replicas. But as a down side, this mode does not ensure the message delivery in case of broker failure.
翻译
kafka的副本机制
在我们讨论Kafka的副本机制之前,让我们来谈谈消息分区。
在Kafka中,消息分区发生在broker端。
如何分区消息是由producer决定的。
broker存储消息的顺序与它们到达的顺序相同。
可以为broker中的每个主题配置分区数量。
Kafka副本策略是Kafka 0.8中引入的非常重要的功能之一。
虽然Kafka具有高度可扩展性,但副本是为了kafka集群有更好的消息持久性和高可用性。
副本保证了即使在某个broker故障时也可以发布和消费消息。
在这里,生产者和消费者都可以在Kafka中识别副本。
下图说明了Kafka中的副本策略:
我们将详细讨论上图。
在副本策略中,消息的每个分区都有n个副本,并且可以承受n-1个节点故障,保证消息分发。
在n个副本中,1个副本充当其余副本的lead。
ZooKeeper保存关于lead副本和当前同步的follower副本的信息(lead副本维护所有的同步follower副本的列表)
每个副本将消息的一部分存储在本地logs和offsets中,并定期同步到磁盘。此过程还确保可以将消息写入所有副本或不写入任何副本。
如果lead副本故障,则在将消息分区写入其本地log时或在向producer发送确认之前,producer将消息分区重新分发给新的lead broker。
推选新的leader过程就是followers在ZooKeeper中的注册过程,第一个注册的就是leader,其余注册成为followers。
Kafka支持以下复制模式:
•同步复制:在同步复制中,producer首先从ZooKeeper中识别lead副本并发布消息。消息一发布,就会将其写入lead副本的日志中,并且所有follwers都会开始拉消息,并通过使用单信道,确保消息的顺序。一旦将消息写入其各自的日志,每个follwers副本就向该lead副本发送确认。一旦复制完成并且收到所有预期的确认,lead副本就向priducer发送确认。在consumer方面,所有消息的拉取都是从lead副本完成的。
•异步复制:此模式与同步复制的唯一区别是,只要lead副本将消息写入其本地日志,它就会将确认发送到消息客户端,而不会等待来自followers副本的确认。但缺点是,这种模式不能确保在broker故障的情况下传递消息。
练习
1.搭建单节点多broker的kafka后,启动zk和kafka。
[root@hadoop ~]# cd /usr/local/kafka [root@hadoop kafka]# zookeeper-server-start.sh config/zookeeper.properties ... [root@hadoop kafka]# kafka-server-start.sh config/server0.properties & ... [root@hadoop kafka]# kafka-server-start.sh config/server1.properties & ... [root@hadoop kafka]# kafka-server-start.sh config/server2.properties & ... [root@hadoop ~]# jps 6416 QuorumPeerMain 7362 Kafka 6707 Kafka 7034 Kafka 7690 Jps
2.创建主题(3个分区2个副本)
[root@hadoop ~]# cd /usr/local/kafka [root@hadoop kafka]# kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 2 --partitions 3 --topic mytest2 Created topic "mytest2".
2.1 查看主题
[root@hadoop ~]# kafka-topics.sh --describe --zookeeper localhost:2181 --topic mytest2 Topic:mytest2 PartitionCount:3 ReplicationFactor:2 Configs: Topic: mytest2 Partition: 0 Leader: 1 Replicas: 1,2 Isr: 1,2 #副本0在broker1和broker2上,leader是broker1 Topic: mytest2 Partition: 1 Leader: 2 Replicas: 2,0 Isr: 2,0 Topic: mytest2 Partition: 2 Leader: 0 Replicas: 0,1 Isr: 0,1
2.2 查看zk上面topic信息(与 查看主题 信息对应)
[root@hadoop ~]# cd /usr/local/kafka [root@hadoop kafka]# zkCli.sh -server hadoop:2181 #启动zk客户端 ... [zk: localhost:2181(CONNECTED) 0] ls /brokers/topics/mytest2/partitions [0, 1, 2] [zk: localhost:2181(CONNECTED) 1] get /brokers/topics/mytest2/partitions/0/state {"controller_epoch":32,"leader":1,"version":1,"leader_epoch":0,"isr":[1,2]} ... [zk: localhost:2181(CONNECTED) 2] get /brokers/topics/mytest2/partitions/1/state {"controller_epoch":32,"leader":2,"version":1,"leader_epoch":0,"isr":[2,0]} ... [zk: localhost:2181(CONNECTED) 3] get /brokers/topics/mytest2/partitions/2/state {"controller_epoch":32,"leader":0,"version":1,"leader_epoch":0,"isr":[0,1]} ...
2.3 查看3个broker的日志目录
[root@hadoop ~]# ls /tmp/kafka-logs0 mytest2-1 mytest2-2 ... [root@hadoop ~]# ls /tmp/kafka-logs1 mytest2-0 mytest2-2 ... [root@hadoop ~]# ls /tmp/kafka-logs2 mytest2-0 mytest2-1 ...
可见 主题是按照replication-factor 2 * partitions 3 = 6 然后在broker中均衡分配的
3.修改主题的副本位置
[root@hadoop kafka]# kafka-topics.sh --alter --zookeeper localhost:2181 replica-assigment 0:0,1:1,2:2 --topic mytest2
再次查看主题,发现没变,按理说这个命令没错啊?未完待续。。。