一、BN 的作用
1、具有快速训练收敛的特性:采用初始很大的学习率,然后学习率的衰减速度也很大
2、具有提高网络泛化能力的特性:不用去理会过拟合中drop out、L2正则项参数的选择问题
3、不需要使用使用局部响应归一化层,BN本身就是一个归一化网络层
4、可以把训练数据彻底打乱
神经网络训练开始前,都要对输入数据做一个归一化处理,原因在于神经网络学习过程本质就是为了学习数据分布,一旦训练数据与测试数据的分布不同,那么网络的泛化能力也大大降低;另外一方面,一旦每批训练数据的分布各不相同(batch 梯度下降),那么网络就要在每次迭代都去学习适应不同的分布,这样将会大大降低网络的训练速度,这也正是为什么我们需要对数据都要做一个归一化预处理的原因。网络中间层在训练过程中,数据分布的改变称之为:“Internal Covariate Shift”。Batch Normalization就是要解决在训练过程中,中间层数据分布发生改变的情况
二、启发来源:白化
所谓白化,就是对输入数据分布变换到0均值,单位方差的正态分布——那么神经网络会较快收敛。经过白化预处理后,数据满足条件:a、特征之间的相关性降低,这个就相当于pca;b、数据均值、标准差归一化,也就是使得每一维特征均值为0,标准差为1。如果数据特征维数比较大,要进行PCA,也就是实现白化的第1个要求,是需要计算特征向量,计算量非常大,于是为了简化计算,忽略第1个要求,仅仅使用了下面的公式进行预处理,也就是近似白化预处理:
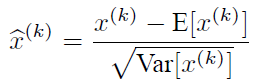
BN可以理解为对深层神经网络每个隐层神经元的激活值做简化版本的白化操作。
三、BN的本质
深层神经网络在做非线性变换前的激活输入值(就是那个x=WU+B,U是输入)随着网络深度加深或者在训练过程中,其分布逐渐发生偏移或者变动,之所以训练收敛慢,一般是整体分布逐渐往非线性函数的取值区间的上下限两端靠近(对于Sigmoid函数来说,意味着激活输入值WU+B是大的负值或正值),所以这导致后向传播时低层神经网络的梯度消失,这是训练深层神经网络收敛越来越慢的本质原因。
BN则是对于每个隐层神经元,把逐渐向非线性函数映射后向取值区间极限饱和区靠拢的输入分布强制拉回到均值为0方差为1的比较标准的正态分布,使得非线性变换函数的输入值落入对输入比较敏感的区域,以此避免梯度消失问题。因为梯度一直都能保持比较大的状态,所以很明显对神经网络的参数调整效率比较高,就是变动大,就是说向损失函数最优值迈动的步子大,也就是收敛地快。
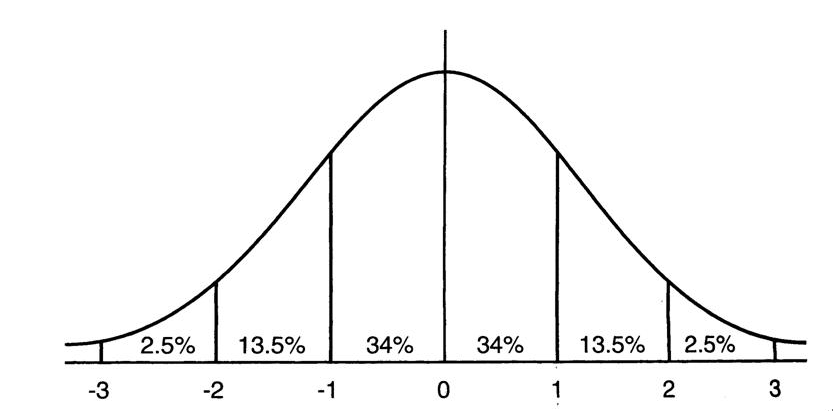
均值为0方差为1的标准正态分布图
这意味着在一个标准差范围内,64%的概率x其值落在[-1,1]的范围内,在两个标准差范围内,95%的概率x其值落在了[-2,2]的范围内。激活值x=WU+B,U是真正的输入,x是某个神经元的激活值,假设非线性函数是sigmoid,那么看下sigmoid(x)其图形:
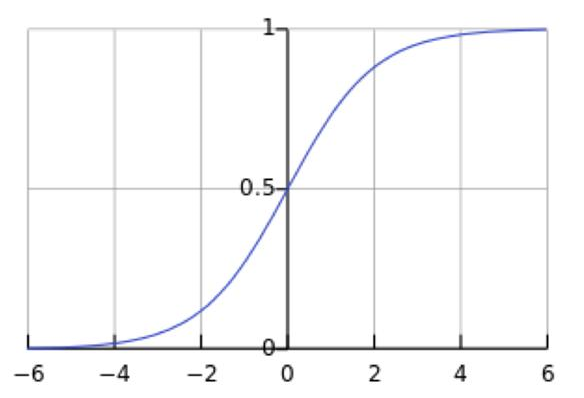
Sigmoid(x)
假设没有经过BN调整前x的原先正态分布均值是-6,方差是1,那么意味着95%的值落在了[-8,-4]之间,那么对应的Sigmoid(x)函数的值明显接近于0,这是典型的梯度饱和区,在这个区域里梯度变化很慢。sigmoid(x)如果取值接近0或者接近于1的时候对应导数函数取值,接近于0,意味着梯度变化很小甚至消失。而假设经过BN后,均值是0,方差是1,那么意味着95%的x值落在了[-2,2]区间内,很明显这一段是sigmoid(x)函数接近于线性变换的区域,意味着x的小变化会导致非线性函数值较大的变化,也即是梯度变化较大,对应导数函数图中明显大于0的区域,就是梯度非饱和区。经过BN后,目前大部分Activation的值落入非线性函数的线性区内,其对应的导数远离导数饱和区,这样来加速训练收敛过程。BN为了保证非线性的获得,对变换后的满足均值为0方差为1的x又进行了scale加上shift操作(y=scale*x+shift),即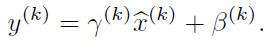 每个神经元增加了两个参数scale和shift参数,这两个参数是通过训练学习到的,通过scale和shift把这个值从标准正态分布左移或者右移一点并长胖一点或者变瘦一点,每个实例挪动的程度不一样,这样等价于非线性函数的值从正中心周围的线性区往非线性区动了动。
每个神经元增加了两个参数scale和shift参数,这两个参数是通过训练学习到的,通过scale和shift把这个值从标准正态分布左移或者右移一点并长胖一点或者变瘦一点,每个实例挪动的程度不一样,这样等价于非线性函数的值从正中心周围的线性区往非线性区动了动。
四、BN算法概述
(1)
要对每个隐层神经元的激活值做BN,可以想象成每个隐层又加上了一层BN操作层,它位于X=WU+B激活值获得之后,非线性函数变换之前,其图示如下:
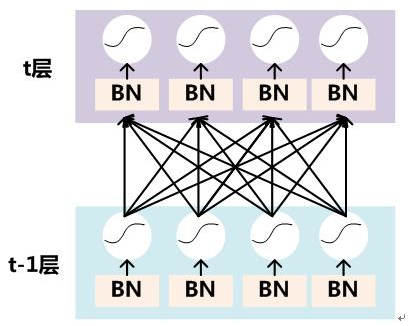
具体BN操作就是对于隐层内每个神经元的激活值来说,进行如下变换:
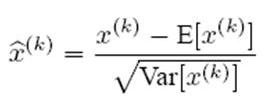
经过这个变换后某个神经元的激活x形成了均值为0,方差为1的正态分布,目的是把值往后续要进行的非线性变换的线性区拉动,增大导数值,增强反向传播信息流动性,加快训练收敛速度(这里t层某个神经元的x(k)不是指原始输入,就是说不是t-1层每个神经元的输出,而是t层这个神经元的激活x=WU+B,这里的U才是t-1层神经元的输出)。
(2)
如果是仅仅使用上面的归一化公式对网络(t-1)层的输出数据做归一化,然后送入网络下一层 t,这样是会影响到本层网络(t-1)所学习到的特征的。所以引入了可学习参数γ、β
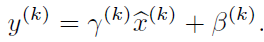
每一个神经元xk都会有一对这样的参数γ、β,根据这两个参数恢复出原始的某一层所学到的特征:
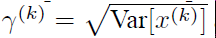
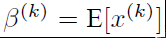
Batch Normalization网络层的前向传导过程公式就是(m指的是mini-batch size):
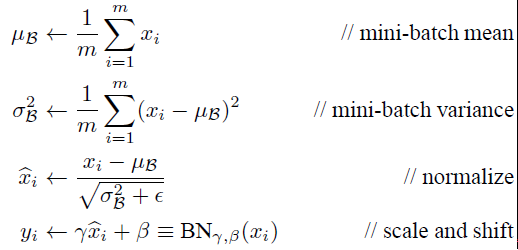
(3)
网络一旦训练完毕,参数都是固定的,这个时候即使是每批训练样本进入网络,那么BN层计算的均值u、和标准差都是固定不变的。我们可以采用这些数值来作为测试样本所需要的均值、标准差,于是最后测试阶段的u和σ 计算公式如下:
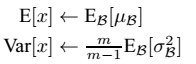
对于均值来说直接计算所有batch u值的平均值;然后对于标准偏差采用每个batch σB的无偏估计。最后测试阶段,BN的使用公式就是:
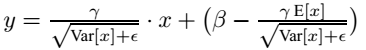
五、Tensorflow的Batch Normalization
tensorflow中关于BN(Batch Normalization)的函数主要有两个,分别是:
• tf.nn.moments
• tf.nn.batch_normalization
(1)tf.nn.moments函数
def moments(x, axes, name=None, keep_dims=False)
• x 可以理解为我们输出的数据,形如 [batchsize, height, width, kernels]
• axes 表示在哪个维度上求解,是个list,例如 [0, 1, 2]
• name 就是个名字
• keep_dims 是否保持维度
• 两个输出:
Two Tensor objects: mean(均值) and variance(方差).
计算卷积神经网络某层的的mean和variance:
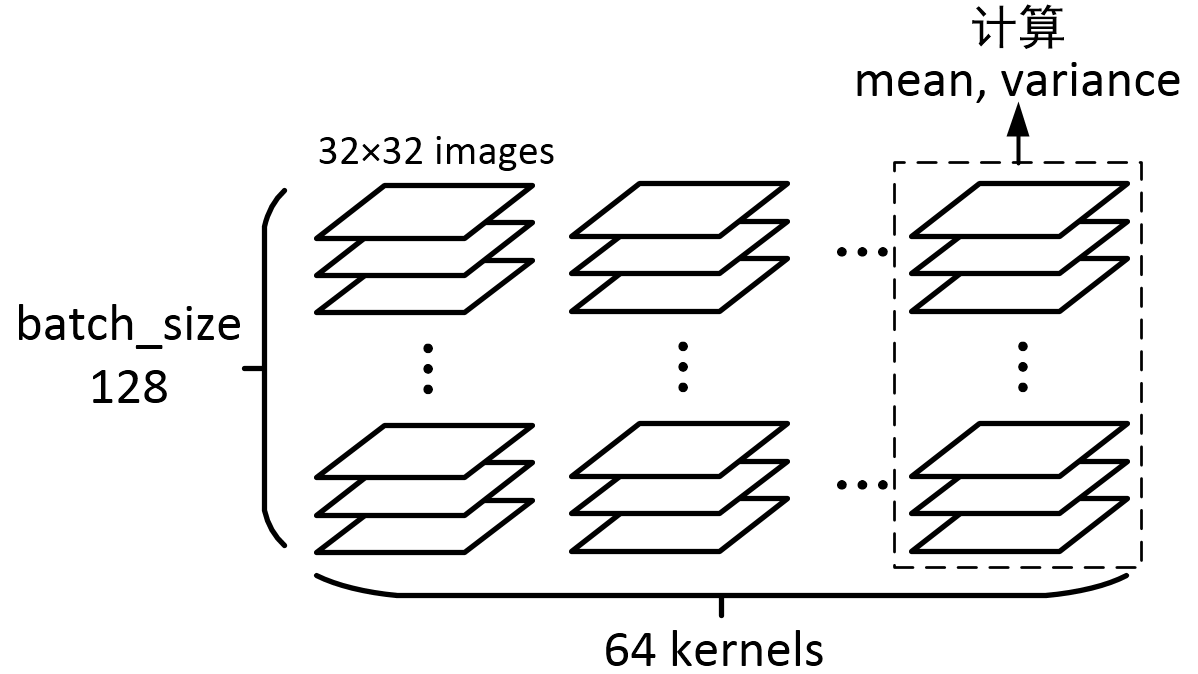
假定我们需要计算数据的形状是 [batchsize, height, width, kernels],例如:
img = tf.Variable(tf.random_normal([128, 32, 32, 64]))
axis = list(range(len(img.get_shape()) - 1))
mean, variance = tf.nn.moments(img, axis)
对应输出为:

一个batch里的128个图,经过一个64 kernels卷积层处理,得到了128×64个图,再针对每一个kernel所对应的128个图,求它们所有像素的mean和variance,因为总共有64个kernels,输出的结果就是一个一维长度64的数组
(2)tf.nn.batch_normalization函数
def batch_normalization(x, mean, variance, offset, scale, variance_epsilon, name=None):
同样返回mean、variance

offset和scale这两个参数是需要训练的,其中offset一般初始化为0,scale初始化为1,另外offset、scale的shape与mean相同。
注意:BN在神经网络进行training和testing的时候,所用的mean、variance是不一样的!(在上文的 “四-(3)”有提及)