刚开始看这方面论文的时候对于各种评价方法特别困惑,还总是记混,不完全统计下,备忘。
关于召回率和精确率,假设二分类问题,正样本为x,负样本为o:
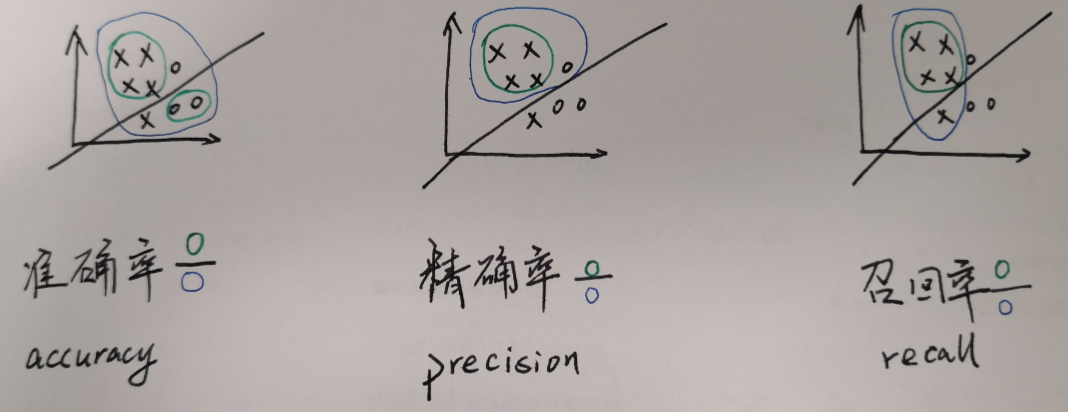
准确率存在的问题是当正负样本数量不均衡的时候:
精心设计的分类器最后算准确率还不如直接预测所有的都是正样本。
用Recall和Precision来衡量分类效果,可以使用F1 Score = 2PR/(P+R)来判断分类效果。
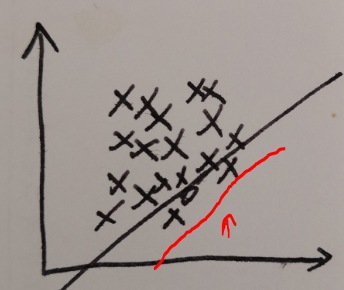
调整分类器,移动到这里:
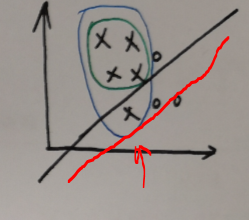
Recall达到百分之一百,但同时Precision也下降了:把不是负样本也分类成了正样本。一般来说,R高,P低,或者R低,P高。大概长这样:
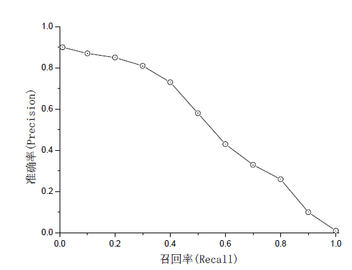
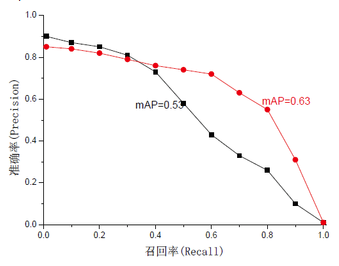
一个好的分类方法当然是希望二者都尽量高,也就是右图红色线那样,所以提出又提出了一个衡量标准:mAP=∫P(R)dR,(PR曲线面积越大越好)。
当然不同应用有不同需求,还是要根据具体应用设计。
记得微软ECCV14的人脸检测就是先用OpenCV里的VJ方法,把Recall调得很高,尽量保证不漏检,同时带来的问题是Precision很低,有很多不是脸的东西,再通过3000帧人脸对齐方法,迭代几次,一边对齐人脸一边把不是脸的排除掉。
另外还有 ROC AUC 及其他各种......
ROC和AUC也是针对正负样本数量不均衡的,参考这里
ROC曲线越靠近左上角,试验的准确性就越高。最靠近左上角的ROC曲线的点是错误最少的最好阈值,其假阳性和假阴性的总数最少。亦可通过分别计算各个试验的ROC曲线下的面积(AUC)进行比较,哪一种试验的 AUC最大,则哪一种试验的诊断价值最佳。
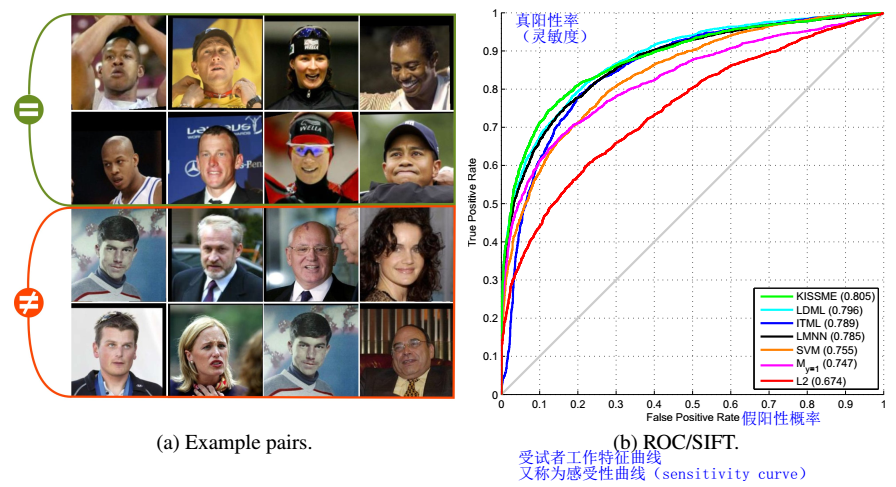
kISSME(cvpr12)里的ROC曲线:
关于Precision和Recall,在Ng的cousera课程 week6 lecture11里有