为了insightface和mxnet较劲的一天
mxnet环境:
官网下载pyhton2.7版本的anaconda,随便找个安装教程
sh Anacondaxxxx.sh #一路默认即可,第二个回车符后修改自己想要安装的路径 #安装完毕后重启命令行,再次打开切换成了(base) conda create -n mxnet python=2.7 #等待配置,完成以后继续: conda activate mxnet cat /usr/local/cuda/version.txt #输出9.0.xxx pip install mxnet-cu90
按insightface readme操作,每次加载完数据开始执行时报错out of memory, batchsize改成1也不行,issue#32有关于这个报错的讨论,结合其他资源各种瞎试,目测是mxnet-cu90的锅。
conda清华源不支持的解决:
conda info

删除.condarc里跟清华源有关的网址并保存就可以了
或者也可以一条一条删除:
conda config --remove channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
有些环境配不上可能是源的问题,半年没用,机器默认镜像被改成阿里源了, scikit-image就一直装不上,要求python2装0.15以下版本,按报错提示还是装不成,灵机一动加上-i清华源就好了:
pip install 'scikit-image<0.15' -i https://pypi.tuna.tsinghua.edu.cn/simple some-package
----------2019.05.02 还真不是,后来同事说刚好那台机器有块卡坏了,今天在另外一台也是cu90的机器上装了,没啥问题......----------
错误信息:
[14:15:31] src/storage/./pooled_storage_manager.h:143: cudaMalloc failed: out of memory
未果的尝试如下:
1. 强制安装mxnet-cu92 - 跑不了,cuda版本和mxnet不一致;
在一个有cuda9.2版本的机器上好不容易装好了mxnet-cu92,报错如下:
OSError: libcudart.so.9.2: cannot open shared object file: No such file or directory
解决方案:
export LD_LIBRARY_PATH=/usr/local/cuda-9.0/lib64
然后各种环境配齐,还是错:
Check failed: e == cudaSuccess || e == cudaErrorCudartUnloading CUDA: CUDA driver version is insufficient for CUDA runtime version
cuda有个对应版本,显卡太老不支持9.2
2. 直接pip install mxnet - 就是装了cpu版本,跑不了,程序会强烈要求设置cuda=1;
3. 执行如下指令:
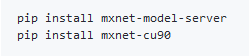
- 一样的out of memory问题
4. 用conda create -n mxnet python=3.6搭建python3环境,运行时各种版本不对导致的xrange ascii错误
最后找了一个cuda版本7.5的,重复上述步骤改为pip install mxnet-cu75就可以跑了,K80的卡resnet50网络batchsize=32显存也就用了一半。
实际训练batchsize=32会导致lossval=Nan,改成128*8块卡,每块卡占8319MB,loss比较稳定的开始下降了
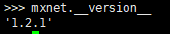
5. (2019.10.29)在cuda-9.0的机器上装了1.2.1版本的mxnet,用triplet finetune结果很诡异,loss在第一个bag不降,然后骤降,测试结果还不如原始模型。不太确定当时怎么配的环境了,pip install mxnet-cu90换成1.5.1就正常
 --->
---> 
其他环境:
1. No module named memonger
git clone https://github.com/dmlc/mxnet-memonger.git
export PYTHONPATH=$PYTHONPATH:/clone下来的memonger路径
2. pip install sklearn pillow opencv-python等,如果出现 Read timed out. 后加--default-timeout
pip install mxnet-cu80 --default-timeout=1000
3. 安装Anaconda后推出shell也不自动进入conda环境:
vi ~/.bashrc export PATH=$PATH:/home/xxx/anaconda2/bin #输入以后保存退出 source ~/.bashrc
再次退出shell再进入就好了。
4. openBlas安装
运行insightface:
训练
可以用src/train_softmax.py r100网络K80的卡要设batchsize=64
config.py里面的num_classed要和数据里面的id数匹配(不匹配的症状是lossvalue到4000个batch会慢慢变大,最后nan)
CUDA_VISIBLE_DEVICES是一种临时环境变量,用来指示mxnet哪些gpu是可用的。
数据准备
mxnet生成rec的正确姿势:
python im2rec.py /xxx/data/celeb /ddd/FR/celebrity --list --recursive
python im2rec.py --num-thread 28 /xxx/data/celeb.lst /ddd/FR/celebrit
prefix和root放在前边,list和recursive如果显示指定就是True,否则作为False,应有如下打印信息和输出:


lst格式如下,Label从0开始需要连续:
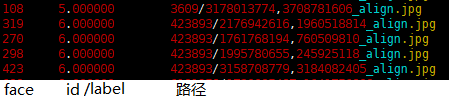
其他问题
bind报错,"RuntimeError: softmax_label is not presented"
参考这里:
provide_data = test_dataiter.provide_data provide_label = test_dataiter.provide_label model.bind( data_shapes=provide_data, label_shapes=provide_label, for_training=False ) model.set_params(arg_params, aux_params, allow_missing=True) #加上allow_missing=True就可以了
资源:
本来是要趁着五一小长假撸一遍论文系统整理一下的,发现资源已经很丰富了:
最开始的几篇经典整理如下:

测试指标:
先看1再看2,窃以为,把相同id做为P;不同id作为N,TAR相当于TPR;FAR相当于FPR,人脸识别领域的TAR和分类的TPR以及检测的Recall是同一个指标。
测试时如果在万分之一之前都正常,到某个量级突然阈值变得很大,TPR骤降,多半是测试数据集标注错误比例过高(相对于测试量级),如果测试id本身不够多,比如只有2000个id,负例对只有约400万个,要测百万分之一,就要取分数的倒数第4个作为阈值,而测试样本里有几个明明是同一个人被标成了不同人,取到的阈值就会很大,导致正例对中大量阈值稍小的样本对被误判为不同人。
经查是切图代码bug,有的id对应的原始图像是坏的,try except里没有continue,导致保存了上一次处理的图像作为这个id。
tricks:
苏宁:只微调最后一层特征,在调整到一定程度之后,才会放开所有的参数,微调整个模型。
-------------------------
paddlepaddle的环境,懒得建新文档,就放这里吧,按照官方的来,不管复杂的安装手续,直接执行:
pip install paddlepaddle-gpu==1.7.1.post97 -i https://mirror.baidu.com/pypi/simple
傻瓜式安装,不知道百度给装了什么依赖库,装好以后服务器的消息都是中文的了,暂未发现其他影响,然后按官方提供方式验证:
import paddle.fluid
paddle.fluid.install_check.run_check()
果然报错了,libcublas找不到
locate libcublas.so #找到本地地址
根据找到的地址,执行:
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH://usr/local/cuda-9.0/targets/x86_64-linux/lib/
就可以了。