相信大家平时面试都会遇到这个问题:平时你都是怎么对sql进行调优的?
此篇文章相当于一个随便笔记,根据朋友们的聊天记录整理而成,如有不对,请指正!
注意:这篇是以mysql整理的
查看sql计划分析
explain sql语句,根据type key extra进行相应优化
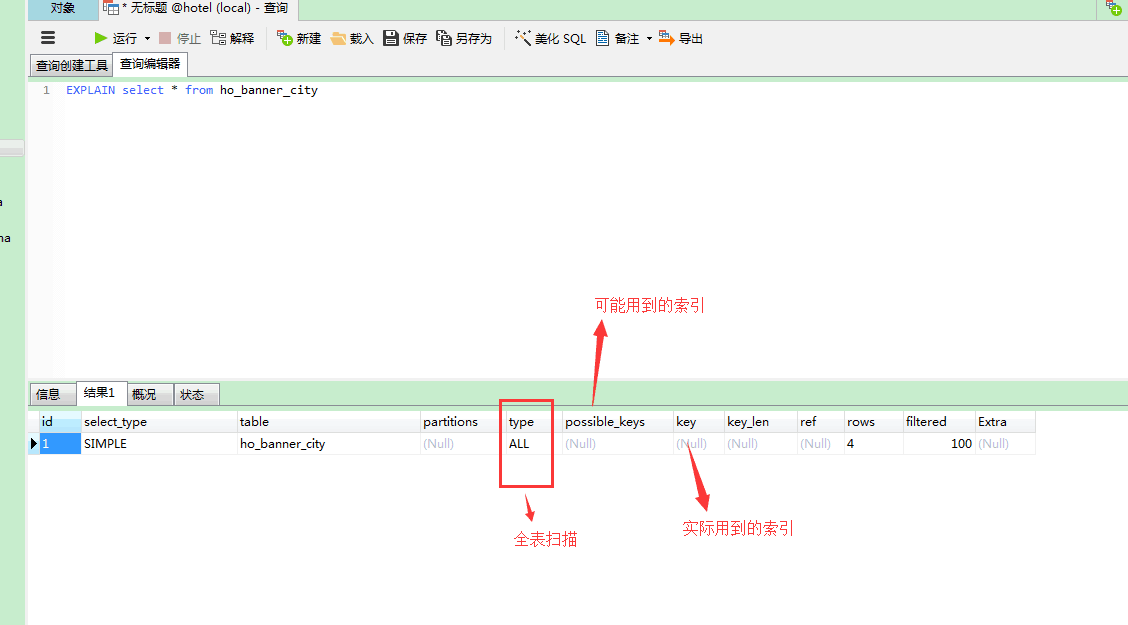
type=all代表 mysql本次查询 进行全表扫描了 就是 把整张表的所有数据都扫描了一遍才给你返回的查询结果 由上至下,效率越来越高 index:索引全扫描 range : 索引范围扫描,常用语<,<=,>=,between等操作 ref :使用非唯一索引扫描或唯一索引前缀扫描,返回单条记录,常出现在关联查询中 eq_ref :类似ref,区别在于使用的是唯一索引,使用主键的关联查询 const/system :单条记录,系统会把匹配行中的其他列作为常数处理,如主键或唯一索引查询 null : MySQL不访问任何表或索引,直接返回结果
extra列 extra列: using index:出现这个说明mysql使用了覆盖索引,避免访问了表的数据行,效率不错! using where:这说明服务器在存储引擎收到行后将进行过滤。有些where中的条件会有属于索引的列,当它读取使用索引的时候,就会被过滤,所以会出现有些where语句并没有在extra列中出现using where这么一个说明。 using temporary:这意味着mysql对查询结果进行排序的时候使用了一张临时表。 using filesort:这个说明mysql会对数据使用一个外部的索引排序,而不是按照表内的索引顺序进行读取。
常规检查
- 不写*
- 不使用sql函数
- 表字段不要为null 等等
- 大数据量的分页 不能使用传统的limit 10,10方式 改成id>xxx 使用索引的方式等