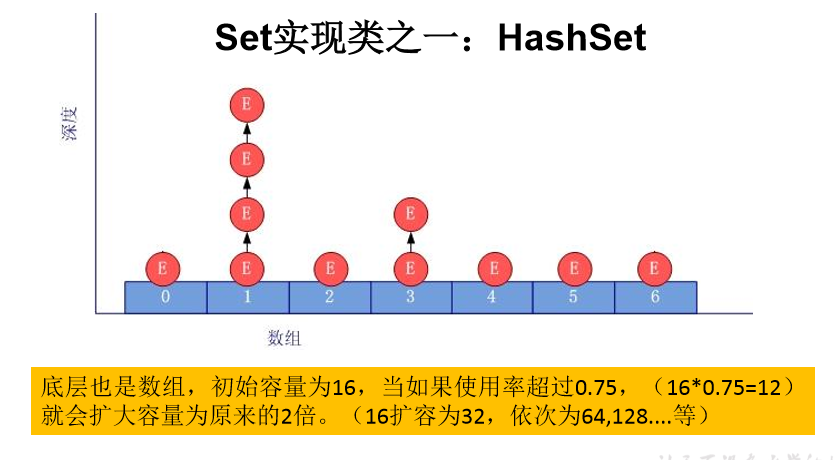
HashSet 是Set的主要实现类 线程不安全可以存储null值 |---- LinkedHashSet 作为HashSet的子类遍历其内部数据结构时可以按照添加顺序遍历 TreeSet 可以按照添加对象的指定属性 进行排序 Set接口中没有添加新的方法 都是使用Collection中的方法 1: 无序性: 不等于随机性 存储的数据再底层中并非按照数组索引的顺序添加,而是根据数据的哈希值来的 2: 不可重复性 :保证添加的元素按照equals()判断时,不能反回true, 即相同的元素只能添加一个 添加元素的过程: 我们向HashSet中添加元素a,首先调用元素a所在类的hashCode()方法,计算元素a的哈希值,此哈希值接着通过某种蒜放计算出 在HashSet底层数组中存放的位置(即为: 索引位置),判断数组此位置上是否已经有其他元素 如果位置上没有其他元素,则把元素a添加到此位置,元素a添加成功 ---->情况1 如果此位置上有其他元素b(或以链表形式存在的多个元素),则比较元素a与元素b的哈希值 如果hash值不同元素a添加成功 ---- > 情况2 如果hash值相同,进而需要田勇元素a所在类的equals()方法: equals()返回true,元素a添加失败, equals()返回false,元素a添加成功 --- > 情况3 对于添加成功的情况2 和3 而言,元素a与已经存在指定索引位置上的数据以链表的形式存储 jdk7: 元素a放在的数组中,指向原来的元素 jdk8: 原来的元素在数组中指向元素a
Set接口是Collection的子接口,set接口没有提供额外的方法
Set 集合不允许包含相同的元素,如果试把两个相同的元素加入同一个 Set 集合中,则添加操作失败。
Set 判断两个对象是否相同不是使用 == 运算符,而是根据 equals() 方法
HashSet
HashSet 是 Set 接口的典型实现,大多数时候使用 Set 集合时都使用这个实现类。 HashSet 按 Hash 算法来存储集合中的元素,因此具有很好的存取、查找、删除 性能。 HashSet 具有以下特点: 不能保证元素的排列顺序 HashSet 不是线程安全的 集合元素可以是 null HashSet 集合判断两个元素相等的标准:两个对象通过 hashCode() 方法比较相 等,并且两个对象的 equals() 方法返回值也相等。 对于存放在Set容器中的对象,对应的类一定要重写equals()和hashCode(Object obj)方法,以实现对象相等规则。即:“相等的对象必须具有相等的散列码”
HashSet添加元素的过程
当向 HashSet 集合中存入一个元素时,HashSet 会调用该对象的 hashCode() 方法 来得到该对象的 hashCode 值,然后根据 hashCode 值,通过某种散列函数决定该对象
在 HashSet 底层数组中的存储位置。(这个散列函数会与底层数组的长度相计算得到在 数组中的下标,并且这种散列函数计算还尽可能保证能均匀存储元素,越是散列分布, 该散列函数设计的越好)
如果两个元素的hashCode()值相等,会再继续调用equals方法,如果equals方法结果 为true,添加失败;如果为false,那么会保存该元素,
但是该数组的位置已经有元素了, 那么会通过链表的方式继续链接。 如果两个元素的 equals() 方法返回 true,但它们的 hashCode() 返回值不相 等,hashSet 将会把它们存储在不同的位置,但依然可以添加成功
重写 hashCode() 方法的基本原则
在程序运行时,同一个对象多次调用 hashCode() 方法应该返回相同的值。 当两个对象的 equals() 方法比较返回 true 时,这两个对象的 hashCode() 方法的返回值也应相等。 对象中用作 equals() 方法比较的 Field,都应该用来计算 hashCode 值。
重写 equals() 方法的基本原则
以自定义的Customer类为例,何时需要重写equals()?
当一个类有自己特有的“逻辑相等”概念,当改写equals()的时候,总是 要改写hashCode(),根据一个类的equals方法(改写后),
两个截然不 同的实例有可能在逻辑上是相等的,但是,根据Object.hashCode()方法, 它们仅仅是两个对象。
因此,违反了“相等的对象必须具有相等的散列码”。
结论:复写equals方法的时候一般都需要同时复写hashCode方法。通 常参与计算hashCode的对象的属性也应该参与到equals()中进行计算。
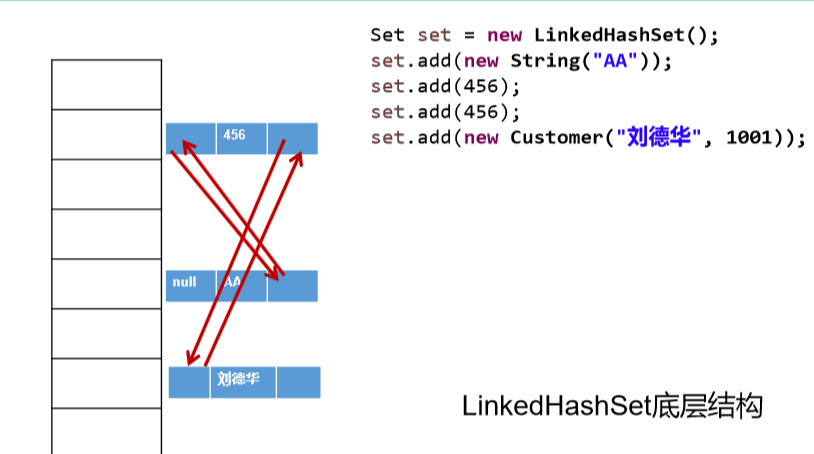
LinkedHashSet
LinkedHashSet 是 HashSet 的子类
LinkedHashSet 根据元素的 hashCode 值来决定元素的存储位置, 但它同时使用双向链表维护元素的次序,这使得元素看起来是以插入 顺序保存的。
LinkedHashSet插入性能略低于 HashSet,但在迭代访问 Set 里的全 部元素时有很好的性能。 LinkedHashSet 不允许集合元素重复。
set 要求:
1: 向set中添加的数据,其所在的类一定要重写hashCode()和equals()方法 2: 重写的hashCode()和equals()尽可能保持一致性, 相等的对象必须具有相等的散列码
LinkedHashSet() 的使用
LinkedHashSet作为HashSet的子类,在添加数据的同时,每个数据还维护了两个引用,记录此数据前和数据后一个数据 优点: 对于频繁的遍历操作, LinkedHashSet的效率高于HashSet
TreeSet 中添加的数据, 要求是相同类的对象
两种排序方式, 自然排序和Comparable接口和Comparator接口
TreeSet中添加元素必须是同一类型的 否则会报错

// TreeSet中添加的元素必须是同一种类型
TreeSet set = new TreeSet();
set.add(123);
set.add(456);
// set.add("AA"); // 报错 因为类型不一致
System.out.println(set.size());
Iterator iterator = set.iterator();
while (iterator.hasNext()){
System.out.println(iterator.next());
}P