伪分布式模式的配置是按照完全分布式模式来搭建的,但是他只有一台服务器,适合用于学习。
下面的文件配置都是尚硅谷课程中做的笔记:
配置集群:
需要配置文件:
第一个文件:

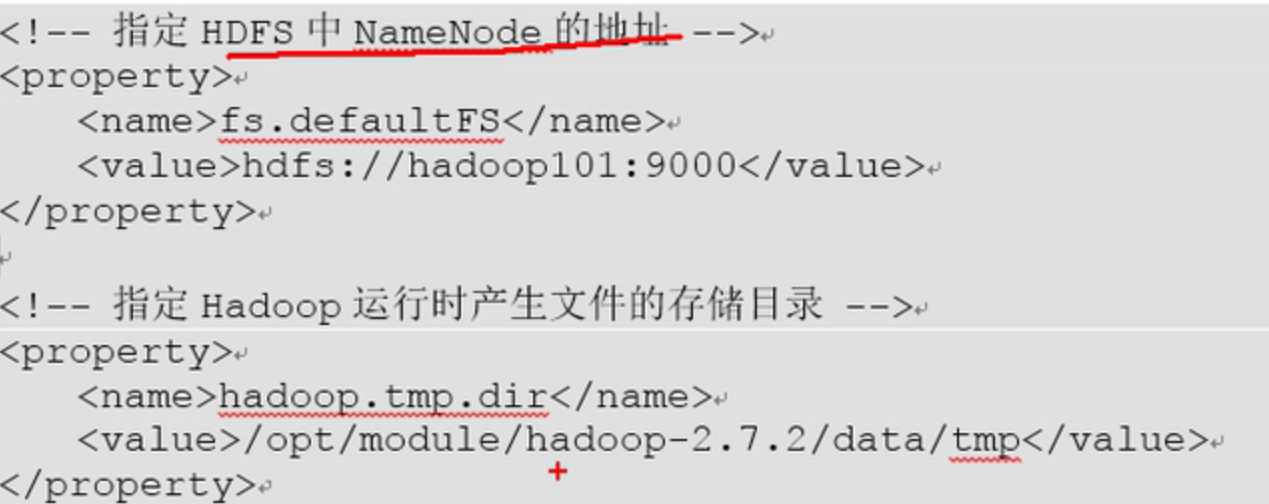
第二个文件:

第三个文件:
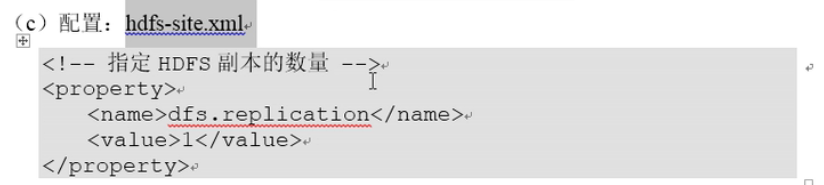
默认的副本数是3,
接下来就要启动集群,
第一步:格式化namenode(只有第一次需要格式化,格式化就是把集群上的数据全部清空)
bin/hdfs namenode -format
第二部 :启动NameNode
sbin/hadoop-daemon.sh start namenode

查看是否启动成功
第三步:启动DataNode
sbin/hadoop-daemon.sh start datanode

检查是否可以工作了,通过 netstat -ntlp 命令查看端口号:

在windows的浏览器中输入网址:hadoop1:9870

如果这个网址出不来,可以检查防火墙是否关闭,检查windows和虚拟机是否相互可以ping通。
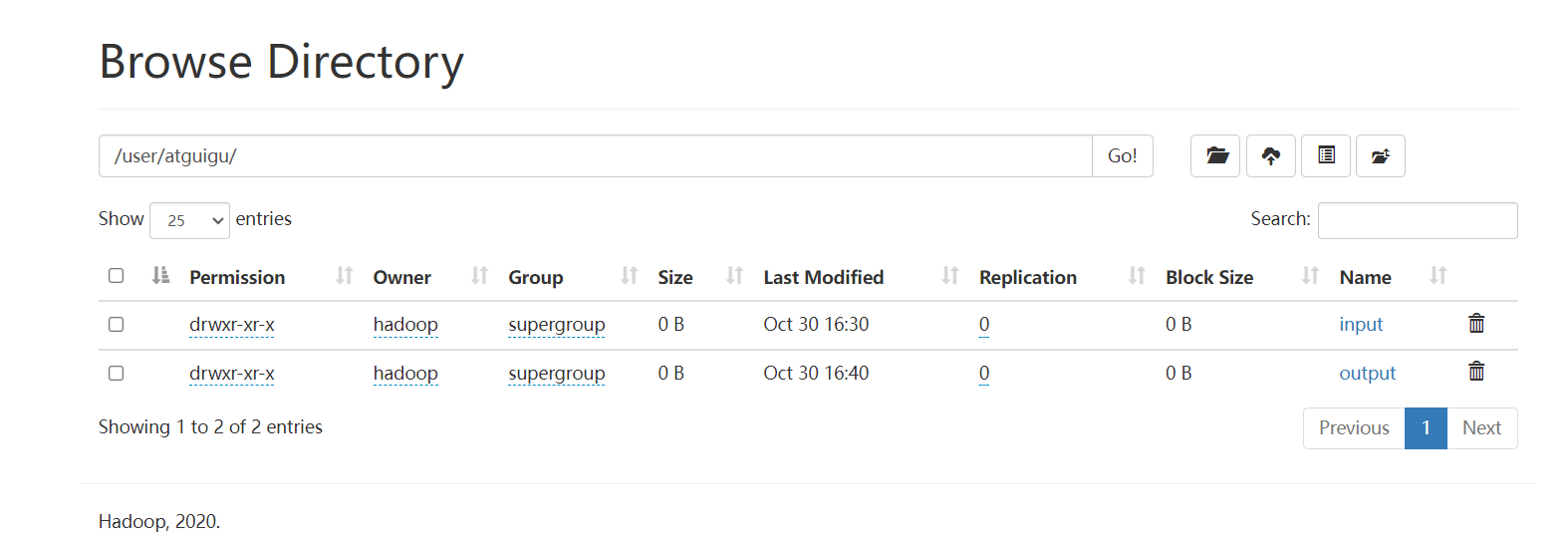
在伪分布式模式下,创建文件:
bin/hdfs dfs -mkdir -p /uesr/atguigu/input
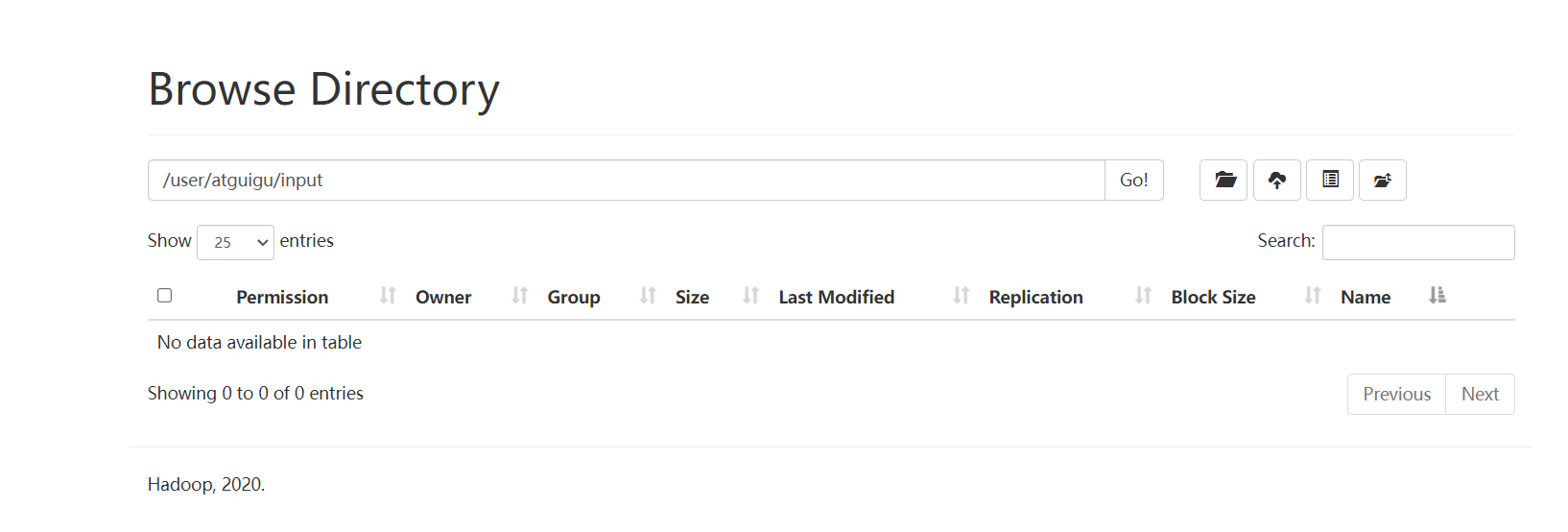
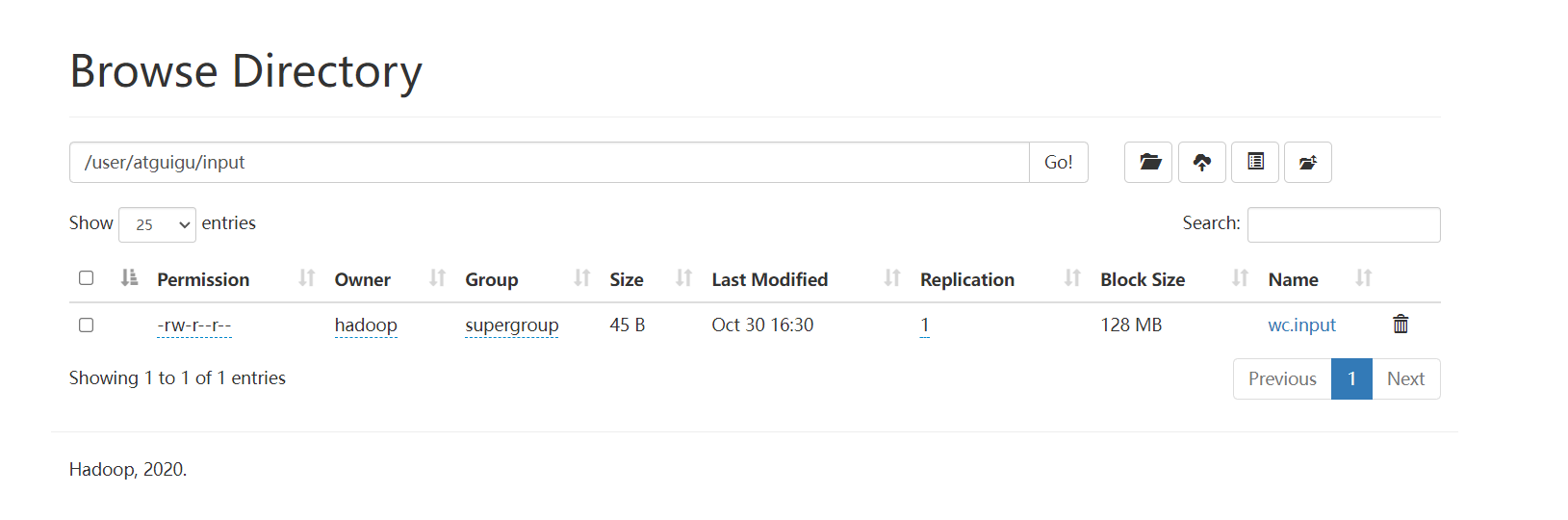
在这个网站里就可以看到刚刚创建的内容。
现在这里就相当于本地文件,要把本地文件wcinput上传到hdfs,
bin/hdfs dfs -put wcinput/wc.input /user/atguigu/input
接下来在hdfs上运行一个wordcount
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar wordcount /user/atguigu/input /user/atguigu/output