爬虫得例子:
百度、谷歌、360搜索等(把关键字相关得网页提取出来)
爬虫是什么:
爬虫是一个模拟人类请求网站行为的程序,自动请求网页,把数据抓取下来,使用一定的规则提取有价值的数据。
爬虫的种类:
分为通用爬虫和聚焦爬虫
通用爬虫是利用搜索引擎来抓取的;聚焦爬虫是利用程序进行抓取,并进行抓取有用的信息。
为什么选择python来进行爬虫:
在学过的几种语言中,c和c++运行效率很高,但是学习和开发成本很大;java的语言代码量很大,一个爬虫程序会随着网址及内容的改变而需要重构,重构时需要花费很多的成本;php并发处理能力弱,速度和效率都达不到爬虫的要求。
urllib库:是一个基本的网络请求库,可以模拟浏览器的行为,向指定的服务器发送一个请求,并可以保存服务器返回的数据
urlopen函数:网络请求的方法
使用:
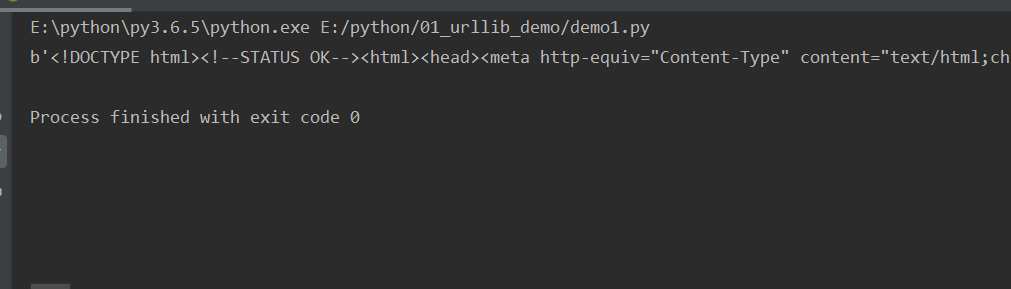
from urllib import request //导入request resp = requset.urlopen("http://baidu.com")//想要抓取的网站 print(resp.read()) //可以读取网站了内容
urlopen函数
read(10)读取10个字节

readline()读取一行
readlines()读取多行
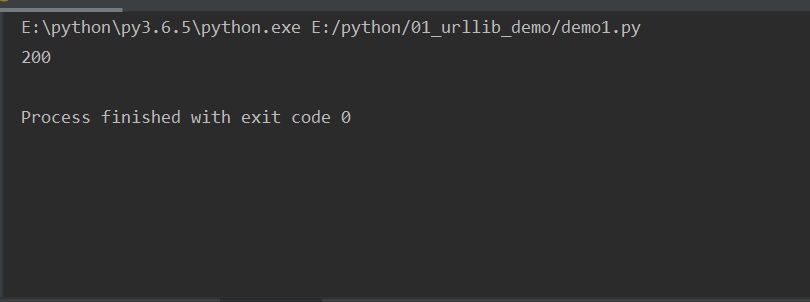
getcode()返回状态值
urlretrieve函数:把网页上的文件保存导本地
request.urlretrieve('http://www.baidu.com/','baidu.html')
这个函数中第一个引号里面的是要下载的网址,第二个引号里面的是对要下载的文件的命名
运行之后就会出现一个baidu.html文件

打开之后,可以选择打开该网页的浏览器
选择浏览器之后:

ulrencode函数:对浏览器发送请求时,如果url中包含了中文或者其他特殊字符,浏览器会自动进行便阿门,如果使用代码发送请求,就需要我们手动编码,所以使用urlencode函数来实现,把字典数据转换为url编码数据。
params ={'name':'张三',"age":18,'greet':"hello world"}//hello world中间又空格,所以要进行编码
result =parse.urlencode(params)//使用urlencode函数对其进行编码
print(result)
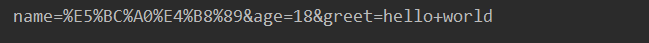
例如:
url='http://www.baidu.com/s?wd=刘德华' resp=request.urlopen(url) print(resp.read())
结果:
未进行编码,代码运行报错,显示ascii不能识别
url='http://www.baidu.com/s' params={'wd':'刘德华'}//把汉字的部分拿出来 ps=parse.urlencode(params)//进行编码 url =url+"?"+ps//拼接 resp =request.urlopen(url)//请求网址 print(resp.read())//读取
结果得到网址的内容:

parse_qs函数:将经过编码后的url进行解码。
params ={'name':'张三',"age":18,'greet':"hello world"}
qs=parse.urlencode(params)//编码
result=parse.parse_qs(qs)//解码
print(result)
结果:
