1. ReLu作为激活函数
在最初的感知机模型中,输入和输出的关系
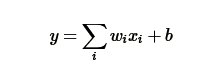
只是单纯的线性关系,这样的网络结构有很大的局限性:即使用很多这样结构的网络层叠加,其输出和输入仍然是线性关系,无法处理有非线性关系的输入输出。因此,对每个神经元的输出做个非线性的转换也就是,将上面就加权求和的结果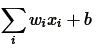
输入到一个非线性函数,也就是激活函数中。 这样,由于激活函数的引入,多个网络层的叠加就不再是单纯的线性变换,而是具有更强的表现能力。

在最初,sigmod和tanh函数是最常用的激活函数。

在网络层数较少时,sigmoid函数的特性能够很好的满足激活函数的作用:它把一个实数压缩至0到1之间,当输入的数字非常大的时候,结果会接近1;当输入非常大的负数时,则会得到接近0的结果。这种特性,能够很好的模拟神经元在受刺激后,是否被激活向后传递信息(输出为0,几乎不被激活;输出为1,完全被激活)。
sigmoid一个很大的问题就是梯度饱和。 观察sigmoid函数的曲线,当输入的数字较大(或较小)时,其函数值趋于不变,其导数变的非常的小。这样,在层数很多的的网络结构中,进行反向传播时,由于很多个很小的sigmoid导数累成,导致其结果趋于0,权值更新较慢。
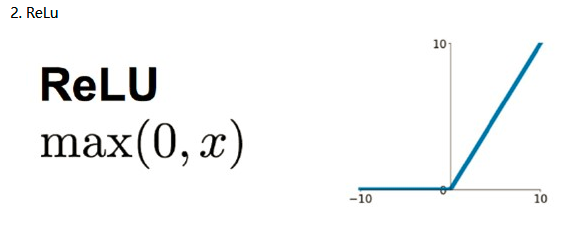
针对Sigmoid梯度梯度饱和导致训练收敛慢的问题,在AlexNet中引入了ReLU。ReLU是一个分段线性函数,小于等于0则输出为0;大于0的则恒等输出。相比Sigmoid,ReLU有以下有点:
- 计算开销下,sigmoid的正向传播有指数运算,倒数运算,而ReLu是线性输出;反向传播中,sigmoid有指数运算,而ReLU有输出的部分,导数始终为1.
- 梯度饱和问题
- 稀疏性。Relu会使一部分神经元的输出为0,这样就造成了网络的稀疏性,并且减少了参数的相互依存关系,缓解了过拟合问题的发生。
问题:前面提到,激活函数要用非线性的,是为了使网络结构有更强的表达的能力。那这里使用ReLU本质上却是个线性的分段函数,是怎么进行非线性变换的?
这里把神经网络看着一个巨大的变换矩阵M,其输入为所有训练样本组成的矩阵A,输出为矩阵B。
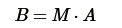
这里的M是一个线性变换的话,则所有的训练样本A进行了线性变换输出为B。
那么对于ReLU来说,由于其是分段的,0的部分可以看着神经元没有激活,不同的神经元激活或者不激活,其神经元处理过组成的变换矩阵是不一样的。
设有两个训练样本a1,a2,其训练时神经网络组成的变换矩阵为M1,M2。 由于M1变换对应的神经网络中激活神经元M2是不一样的,这样M1,M2实际上是两个不同的线性变换。也就是说,每个训练样本使用的线性变换矩阵Mi是不一样的,在整个训练样本空间来说,其经历的是非线性变换。
简单来说,不同训练样本中的同样的特征,在经过神经网络学习时,流经的神经元是不一样的(激活函数值为0的神经元不会被激活)。这样,最终的输出实际上是输入样本的非线性变换。
注:单个训练样本是线性变换,但是每个训练样本的线性变换是不一样的,这样整个训练样本集来说,就是非线性的变换。
参考:https://www.cnblogs.com/wangguchangqing/p/10333370.html