依赖锚框: YOLO v2
针对YOLO v1的不足, 2016年诞生了YOLO v2。 相比起第一个版本, YOLO v2预测更加精准(Better) 、 速度更快(Faster) 、 识别的物体类别也更多(Stronger) , 在VOC 2007数据集上可以得到mAP 10%以上的提升效果。
YOLO v2从很多方面对YOLO做出了改进, 大体可以分为网络结构的改善、 先验框的设计及训练技巧3个方面, 下面主要就这三部分进行讲解。
1. 网络结构的改善
首先, YOLO v2对于基础网络结构进行了多种优化, 提出了一个全新的网络结构, 称之为DarkNet。 原始的DarkNet拥有19个卷积层与5个池化层, 在增加了一个Passthrough层后一共拥有22个卷积层, 精度与VGGNet相当, 但浮点运算量只有VGGNet的1/5左右, 因此速度极快,具体结构如图6.4所示。

相比起v1版本的基础网络, DarkNet进行了以下几点改进:
·BN层: DarkNet使用了BN层, 这一点带来了2%以上的性能提升。BN层有助于解决反向传播中的梯度消失与爆炸问题, 可以加速模型的收敛, 同时起到一定的正则化作用。 BN层的具体位置是在每一个卷积之后, 激活函数LeakyReLU之前。
·用连续3×3卷积替代了v1版本中的7×7卷积, 这样既减少了计算量, 又增加了网络深度。 此外, DarkNet去掉了全连接层与Dropout层。
·Passthrough层: DarkNet还进行了深浅层特征的融合, 具体方法是将浅层26×26×512的特征变换为13×13×2048, 这样就可以直接与深层
13×13×1024的特征进行通道拼接。 这种特征融合有利于小物体的检测,也为模型带来了1%的性能提升。
·由于YOLO v2在每一个区域预测5个边框, 每个边框有25个预测值, 因此最后输出的特征图通道数为125。 其中, 一个边框的25个预测值分别是20个类别预测、 4个位置预测及1个置信度预测值。 这里与v1有很大区别, v1是一个区域内的边框共享类别预测, 而这里则是相互独立的类别预测值。
下面从代码角度介绍如何搭建DarkNet网络, 源代码文件见darknet.py。 和第3章常见的基础结构一样, 在实现时, 可以定义一个_make_layers函数, 通过输入不同的配置, 可以快速搭建整个基础网络。

为了完成整个网络的搭建、 前向与自动反向传播, 在此定义了一个DarkNet19类, 继承自nn.Module, 通过网络配置信息快速构建出每一个模块。

2. 先验框的设计
YOLO v2吸收了Faster RCNN的优点, 设置了一定数量的预选框,使得模型不需要直接预测物体尺度与坐标, 只需要预测先验框到真实物体的偏移, 降低了预测难度。
关于先验框, YOLO v2首先使用了聚类的算法来确定先验框的尺度, 并且优化了后续的偏移计算方法, 下面详细介绍这两部分。先验框的设计为YOLO v2带来了7%的召回率提升。
2.1 聚类提取先验框尺度
Faster RCNN中预选框(即Anchor) 的大小与宽高是由人手工设计的, 因此很难确定设计出的一组预选框是最贴合数据集的, 也就有可能为模型性能带来负面影响。
针对此问题, YOLO v2通过在训练集上聚类来获得预选框, 只需要设定预选框的数量k, 就可以利用聚类算法得到最适合的k个框。 在聚类时, 两个边框之间的距离使用式(6-2) 的计算方法, 即IoU越大, 边框距离越近。

在衡量一组预选框的好坏时, 使用真实物体与这一组预选框的平均IoU作为标准。 值得一提的是, 这一判断标准在手工设计预选框的方法中也可以使用。
至于预选框的数量选取, 显然数量k越多, 平均IoU会越大, 效果会更好, 但相应的也会带来计算量的提升, YOLO v2在速度与精度的权衡中选择了预选框数量为5。
2.2 优化偏移公式
有了先验框后, YOLO v2不再直接预测边框的位置坐标, 而是预测先验框与真实物体的偏移量。 在Faster RCNN中, 中心坐标的偏移公式如式(6-3) 所示。

公式中wa、 ha、 xa及ya代表Anchor的宽高与中心坐标, tx与ty是模型预测的Anchor相对于真实物体的偏移量, 经过计算后得到预测的物体中心坐标x和y。
YOLO v2认为这种预测方式没有对预测偏移进行限制, 导致预测的边框中心可以出现在图像的任何位置, 尤其是在训练初始阶段, 模型参数还相对不稳定。 例如tx是1与-1时, 预测的物体中心点会有两个宽度的差距。
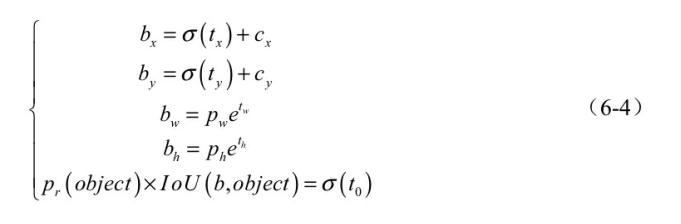
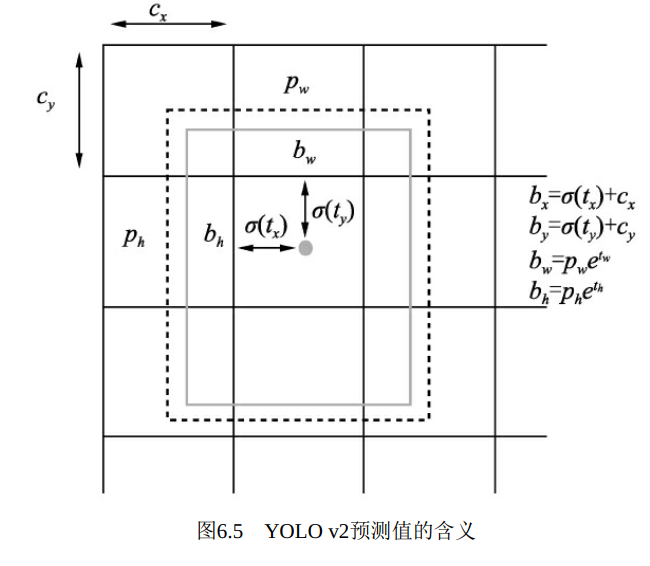
公式中参数的意义可以与图6.5结合进行理解, 图中实线框代表预测框, 虚线框代表先验框:
·cx与cy代表中心点所处区域左上角的坐标, pw与ph代表了当前先验框的宽高, 如图6.5中的虚线框所示。
·σ(tx)与σ(ty)代表预测框中心点与中心点所处区域左上角坐标的距离, 加上cx与cy即得到预测框的中心坐标。
·tw与th为预测的宽高偏移量。 先验框的宽高乘上指数化后的宽高偏移量, 即得到预测框的宽高。
·公式中的σ代表Sigmoid函数, 作用是将坐标偏移量化到(0,1)区间,这样得到的预测边框的中心坐标bx、 by会限制在当前区域内, 保证一个区域只预测中心点在该区域内的物体, 有利于模型收敛。
·YOLO v1将预测值t0作为边框的置信度, 而YOLO v2则是将做Sigmoid变换后的σ(t0)作为真正的置信度预测值。
下面从代码角度介绍一下DarkNet的前向过程, 模型的输出包含每一个预选框的类别预测、 位置预测及置信度预测, 然后再进一步处理为可以方便计算损失的形式。

3. 正、 负样本与损失函数
关于正、 负样本的选取, YOLO v2基本保持了之前的方法, 其基本流程如下:
首先利用式(6-4) , 将预测的位置偏移量作用到先验框上, 得到预测框的真实位置。
如果一个预测框与所有真实物体的最大IoU小于一定阈值(默认为0.6) 时, 该预测框视为负样本。
每一个真实物体的中心点落在了某个区域内, 该区域就负责检测该物体。 具体做法是将与该物体有最大IoU的预测框视为正样本。
确定了正样本与负样本后, 最后是网络损失的计算。 由于利用了先验框, YOLO v2的损失函数也相应的进行了改变, 公式如式(6-5) 所示。
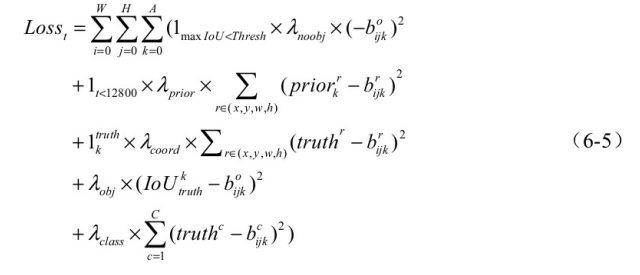
损失一共有5项组成, 意义分别如下:
·第一项为负样本的置信度损失, 公式中1max IoU<Thresh表示最大IoU小于阈值, 即负样本的边框, λnoobj是负样本损失的权重, boijk为置信度σ(to)。
·第二项为先验框与预测框的损失, 只存在于前12800次迭代中, 目的是使预测框先收敛于先验框, 模型更稳定。
·第三项为正样本的位置损失, 表示筛选出的正样本, 为权重。
·后两项分别为正样本的置信度损失与类别损失, 为置信度的真值。
在计算正、 负样本的过程中, 虽然有些预测框的最大IoU可能小于0.6, 即被赋予了负样本, 但如果后续是某一个真实物体对应的最大IoU的框时, 该预测框会被最终赋予成正样本, 以保证recall。
有些预测框的最大IoU大于0.6, 但是在一个区域内又不是与真实物体有最大IoU, 这种预测框会被舍弃掉不参与损失计算, 既不是正样本也不是负样本。