Faster RCNN从问世到现在, 期间诞生了众多优秀的物体检测算法, 但凭借其优越的性能, 目前依然是物体检测领域主流的框架之一。尤其是在高精度、 多尺度和小物体等物体检测领域的难点问题上, 新型算法基本都是在Faster RCNN的基础上优化完善的。
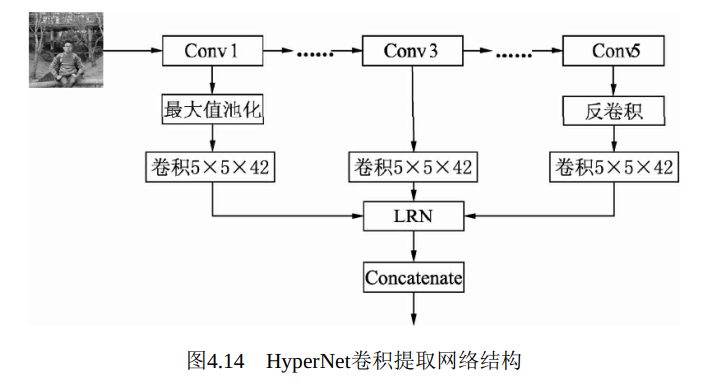
本节将首先分析Faster RCNN的特点及可以优化的方向, 然后从特征提取网络、 RoI Pooling等多个角度, 陆续讲解几个在Faster RCNN基础上优化改进的经典算法, 如HyperNet、 Mask RCNN、 R-FCN及Cascade RCNN算法, 如图4.13所示
1. 审视Faster RCNN
Faster RCNN之所以生命力如此强大, 应用如此广泛, 离不开以下几个特点:
·性能优越: Faster RCNN通过两阶网络与RPN, 实现了精度较高的物体检测性能。
·两阶网络: 相比起其他一阶网络, 两阶更为精准, 尤其是针对高精度、 多尺度以及小物体问题上, 两阶网络优势更为明显。
·通用性与鲁棒性: Faster RCNN在多个数据集及物体任务上效果都很好, 对于个人的数据集, 往往Fine-tune后就能达到较好的效果。
·可优化点很多: Faster RCNN的整个算法框架中可以进行优化的点很多, 提供了广阔的算法优化空间。
·代码全面: 各大深度学习框架都有较好的Faster RCNN源码实现,使用方便。
当然, 原始的Faster RCNN也存在一些缺点, 而这些缺点也恰好成为了后续学者优化改进的方向, 总体来看, 可以从以下6个方面考虑:
·卷积提取网络: 无论是VGGNet还是ResNet, 其特征图仅仅是单层的, 分辨率通常也较小, 这些都不利于小物体及多尺度的物体检测, 因此多层融合的特征图、 增大特征图的分辨率等都是可以优化的方向。
·NMS: 在RPN产生Proposal时为了避免重叠的框, 使用了NMS, 并以分类得分为筛选标准。 但NMS本身的过滤对于遮挡物体不是特别友好, 本身属于两个物体的Proposal有可能因为NMS而过滤为1个, 造成漏检, 因此改进优化NMS是可以带来检测性能提升的。
·RoI Pooling: Faster RCNN的原始RoI Pooling两次取整带来了精度的损失, 因此后续Mask RCNN针对此Pooling进行了改进, 提升了定位的精度。
·全连接: 原始Faster RCNN最后使用全连接网络, 这部分全连接网络占据了网络的大部分参数, 并且RoI Pooling后每一个RoI都要经过一遍全连接网络, 没有共享计算, 而如今全卷积网络是一个发展趋势, 如何取代这部分全连接网络, 实现更轻量的网络是需要研究的方向。
·正负样本: 在RPN及RCNN部分, 都是通过超参数来限制正、 负样本的数量, 以保证正、 负样本的均衡。 而对于不同任务与数据, 这种正、 负样本均衡方法是否都是最有效的, 也是一个研究的方向。
·两阶网络: Faster RCNN的RPN与RCNN两个阶段分工明确, 带来了精度的提升, 但速度相对较慢, 实际实现上还没有达到实时。 因此,网络阶数也是一个值得探讨的问题, 如单阶是否可以使网络的速度更快, 更多阶的网络是否可以进一步提升网络的精度等。
2. 特征融合: HyperNet
卷积神经网络的特点是, 深层的特征体现了强语义特征, 有利于进行分类与识别, 而浅层的特征分辨率高, 有利于进行目标的定位。 原始的Faster RCNN方法仅仅利用了单层的feature map(例如VGGNet的conv5-3) , 对于小尺度目标的检测较差, 同时高IoU阈值时, 边框定位的精度也不高。
在2016 CVPR上发表的HyperNet方法认为单独一个feature map层的特征不足以覆盖RoI的全部特性, 因此提出了一个精心设计的网络结构, 融合了浅、 中、 深3个层次的特征, 取长补短, 在处理好区域生成的同时, 实现了较好的物体检测效果。
HyperNet提出的特征提取网络结构如图4.14所示, 以VGGNet作为基础网络, 分别从第1、 3、 5个卷积组后提取出特征, 这3个特征分别对应着浅层、 中层与深层的信息。 然后, 对浅层的特征进行最大值池化对深层的特征进行反卷积, 使得二者的分辨率都为原图大小的1/4, 与中层的分辨率相同, 方便进行融合。 得到3个特征图后, 再接一个5×5的卷积以减少特征通道数, 得到通道数为42的特征。
在三层的特征融合前, 需要先经过一个LRN(Local ResponseNormalization) 处理, LRN层借鉴了神经生物学中的侧抑制概念, 即激活的神经元抑制周围的神经元, 在此的作用是增加泛化能力, 做平滑处理。
最后将特征沿着通道数维度拼接到一起。 3个通道数为42的特征拼接一起后形成通道数为126的特征, 作为最终输出。
HyperNet融合了多层特征的网络有如下3点好处:
·深层、 中层、 浅层的特征融合到一起, 优势互补, 利于提升检测精度。
·特征图分辨率为1/4, 特征细节更丰富, 利于检测小物体。
·在区域生成与后续预测前计算好了特征, 没有任何的冗余计算。
HyperNet实现了一个轻量化网络来实现候选区域生成。 具体方法是, 首先在特征图上生成3万个不同大小与宽高的候选框, 经过RoI Pooling获得候选框的特征, 再接卷积及相应的分类回归网络, 进而可以得到预测值, 结合标签就可以筛选出合适的Proposal。 可以看出, 这里的实现方法与Faster RCNN的RPN方法很相似, 只不过先进行了RoIPooling, 再选择候选区域。
HyperNet后续的网络与Faster RCNN也基本相同, 接入全连接网络完成最后的分类与回归。 不同的地方是, HyperNet先使用了一个卷积降低通道数, 并且Dropout的比例从0.5调整到了0.25。
由于提前使用了RoI Pooling, 导致众多候选框特征都要经过一遍此Pooling层, 计算量较大, 为了加速, 可以在Pooling前使用一个3×3卷积降低通道数为4, 这种方法在大幅度降低计算量的前提下, 基本没有精度的损失。
总体来看, HyperNet最大的特点还是提出了多层融合的特征, 因此, 其检测小物体的能力更加出色, 并且由于特征图分辨率较大, 物体的定位也更精准。 此外, 由于其出色的特征提取, HyperNet的Proposal的质量很高, 前100个Proposal就可以实现97%的召回率。
值得注意, HyperNet使用到了反卷积来实现上采样, 以扩大尺寸。通常来讲, 上采样可以有3种实现方法: 双线性插值、 反池化(Unpooling) 与反卷积。 反卷积也叫转置卷积, 但并非正常卷积的完全可逆过程。 具体实现过程是, 先按照一定的比例在特征图上补充0,然后旋转卷积核, 再进行正向的卷积。 反卷积方法经常被用在图像分割中, 以扩大特征图尺寸。
3. 实例分割: Mask RCNN
基于Faster RCNN, 何凯明进一步提出了新的实例分割网络Mask RCNN, 该方法在高效地完成物体检测的同时也实现了高质量的实例分割, 获得了ICCV 2017的最佳论文。
Mask RCNN的网络结构如图4.15所示, 可以看到其结构与Faster RCNN非常类似, 但有3点主要区别:
·在基础网络中采用了较为优秀的ResNet-FPN结构, 多层特征图有利于多尺度物体及小物体的检测。
·提出了RoI Align方法来替代RoI Pooling, 原因是RoI Pooling的取整做法损失了一些精度, 而这对于分割任务来说较为致命。
·得到感兴趣区域的特征后, 在原来分类与回归的基础上, 增加了一个Mask分支来预测每一个像素的类别。 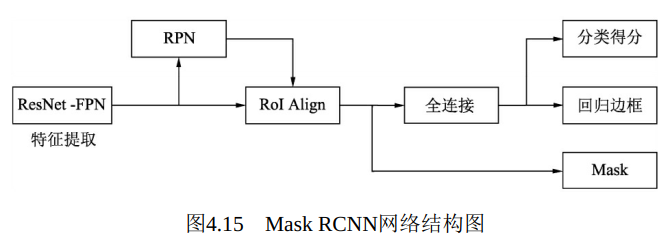
下面将详细介绍这3部分。
3.1 特征提取网络
当前多尺度的物体检测越来越重要, 对于基础的特征提取网络来说, 不同层的特征图恰好拥有着不同的感受野与尺度, 因此可以利用多层特征图来做多尺度的检测, 例如上一节的HyperNet方法。
基于ResNet的FPN基础网络也是一个多层特征结合的结构, 包含了自下而上、 自上而下及横向连接3个部分, 这种结构可以将浅层、 中层、 深层的特征融合起来, 使得特征同时具备强语义性与强空间性, 具体结构参见第3章, 在此不再重复。
原始的FPN会输出P2、 P3、 P4与P5 4个阶段的特征图, 但在MaskRCNN中又增加了一个P6。 将P5进行最大值池化即可得到P6, 目的是获得更大感受野的特征, 该阶段仅仅用在RPN网络中。原始的Faster RCNN使用单层的特征图时, 筛选出的RoI可以直接作用到特征图上进行RoI Pooling, 但如果使用FPN作为基础网络时, 由于其包含了P2、 P3、 P4、 P5这4个阶段的特征图, 筛选出的RoI应该对应到哪一个特征图呢?
对于此问题, Mask RCNN的做法与FPN论文中的方法一致, 从合适尺度的特征图中切出RoI, 大的RoI对应到高语义的特征图中, 如P5, 小的RoI对应到高分辨率的特征图中, 如P3。 式(4-7) 中给出了精确的计算公式:

公式中的224代表着ImageNet预训练图片的大小, k0默认值为4, 表示大小为224×224的RoI应该对应的层级为4, 计算后做取整处理。
这样的分配方法保证了大的RoI从高语义的特征图上产生, 有利于检测大尺度物体, 小的RoI从高分辨率的特征图上产生, 有利于小物体
的检测。
3.2 RoI Align部分
Faster RCNN原始使用的RoI Pooling存在两次取整的操作, 导致RoI选取出的特征与最开始回归出的位置有一定的偏差, 称之为不匹配问题(Missalignment) , 严重影响了检测或者分割的准确度。
Maks RCNN提出的RoI Align取消了取整操作, 而是保留所有的浮点, 然后通过双线性插值的方法获得多个采样点的值, 再将多个采样点进行最大值的池化, 即可得到该点最终的值。
由于使用了采样点与保留浮点的操作, RoI Align获得了更好的性能。 这部分在前面已经详细介绍过, 在此不再重复。
3.3 损失任务设计
在得到感兴趣区域的特征后, Mask RCNN增加了Mask分支来进行图像分割, 确定每一个像素具体属于哪一个类别。 具体实现时, 采用了FCN(Fully Convolutional Network) 的网络结构, 利用卷积与反卷积构建端到端的网络, 最后对每一个像素分类, 实现了较好的分割效果。 由于属于分割领域、 在此不对FCN细节做介绍, 感兴趣的读者可以查看相关资料。
假设物体检测任务的类别是21类, 则Mask分支对于每一个RoI, 输出的维度为21×m×m, 其中m×m表示mask的大小, 每一个元素都是二值的, 相当于得到了21个二值的mask。 在训练时, 如果当前RoI的标签别是5, 则只有第5个类别的mask参与计算, 其他的类别并不参与计算这种方法可以有效地避免类间竞争, 将分类的任务交给更为专业的分类分支去处理。
增加了Mask分支后, 损失函数变为了3部分, 如式(4-8) 所示。 公式中前两部分Lcls、 Lbox与Faster RCNN中相同, 最后一部分Lmask代表了分割的损失。 对mask上的每一个像素应用Sigmoid函数, 送到交叉熵损失中, 最后取所有像素损失的平均值作为Lnask。
Mask RCNN算法简洁明了, 在物体检测与实例分割领域都能得到较高的精度, 在实际应用中, 尤其是涉及多任务时, 可以采用MaskRCNN算法。
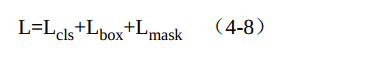
公式中前两部分Lcls、 Lbox与Faster RCNN中相同, 最后一部分Lmask代表了分割的损失。 对mask上的每一个像素应用Sigmoid函数, 送到交叉熵损失中, 最后取所有像素损失的平均值作为Lnask。
Mask RCNN算法简洁明了, 在物体检测与实例分割领域都能得到较高的精度, 在实际应用中, 尤其是涉及多任务时, 可以采用MaskRCNN算法。
4 全卷积网络: R-FCN
Faster RCNN在RoI Pooling后采用了全连接网络来得到分类与回归的预测, 这部分全连接网络占据了整个网络结构的大部分参数, 而目前越来越多的全卷积网络证明了不使用全连接网络效果会更好, 以适应各种输入尺度的图片。
一个很自然的想法就是去掉RoI Pooling后的全连接, 直接连接到分类与回归的网络中, 但通过实验发现这种方法检测的效果很差, 其中一个原因就是基础的卷积网络是针对分类设计的, 具有平移不变性, 对位置不敏感, 而物体检测则对位置敏感。
针对上述“痛点”, 微软亚洲研究院的代季峰团队提出了RFCN(Region-based Fully Convolutional Networks) 算法, 利用一个精心设计的位置敏感得分图(position-sensitive score maps) 实现了对位置的敏感, 并且采用了全卷积网络, 大大减少了网络的参数量。图4.16所示为R-FCN的网络结构图, 首先R-FCN采用了ResNet-101网络作为Backbone, 并在原始的100个卷积层后增加了一个1×1卷积, 将通道数降低为1024。
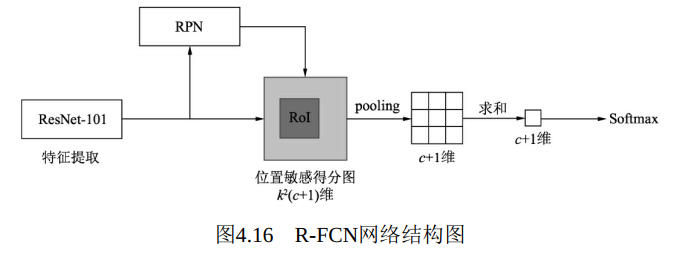
此外, 为了增大后续特征图的尺寸, R-FCN将ResNet-101的下采样率从32降到了16。 具体做法是, 在第5个卷积组里将卷积的步长从2变为1, 同时在这个阶段的卷积使用空洞数为2的空洞卷积以扩大感受野。 降低步长增加空洞卷积是一种常用的方法, 可以在保持特征图尺寸的同时, 增大感受野。
在特征图上进行1×1卷积, 可以得到位置敏感得分图, 其通道数为k2(c+1)。 这里的c代表物体类别, 一般需要再加上背景这一类别。 k的含义是将RoI划分为k2个区域, 如图4.17分别展示了k为1、 3、 5的情况。 例如当k=3时, 可以将RoI分为左上、 中上、 右上等9个区域, 每个区域对特征区域的信息敏感。 因此, 位置敏感得分图的通道包含了所有9个区域内所有类别的信息。
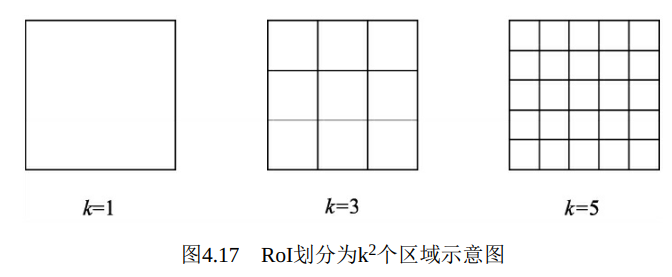
对于一个位置敏感得分图上的点, 假设其坐标为m×n, 通道在右上区域, 类别为人, 则该点表示当前位置属于人并且在人这个“物体”的右上区域的特征, 因此这样就包含了位置信息。
在RPN提供了一个感兴趣区域后, 对应到位置敏感得分图上, 首先将RoI划分为k×k个网格, 如图4.18所示, 左侧为将9个不同区域展开后的RoI特征, 9个区域分别对应着不同的位置, 在Pooling时首先选取其所
在区域的对应位置的特征, 例如左上区域只选取其左上角的特征, 右下区域只选取右下角的特征, 选取后对区域内求均值, 最终可形成右侧的一个c+1维的k×k特征图。
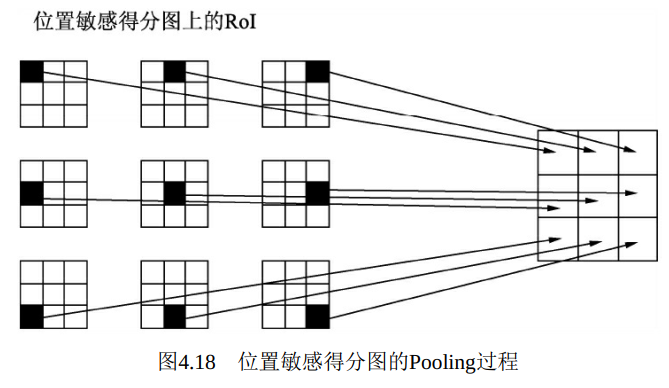
接下来再对这个c+1维的k×k特征进行逐通道求和, 即可得到c+1维的向量, 最后进行Softmax即可完成这个RoI的分类预测。
至于RoI的位置回归, 则与分类很相似, 只不过位置敏感得分图的通道数为k2(c+1), 而回归的敏感回归图的通道数为k2×4, 按照相同的方法进行Pooling, 可形成通道数为4的k×k特征, 求和可得到1×4的向量,即为回归的预测。
由于R-FCN去掉了全连接层, 并且整个网络都是共享计算的, 因此速度很快。 此外, 由于位置敏感得分图的存在, 引入了位置信息, 因此R-FCN的检测效果也更好。
5. 级联网络: Cascade RCNN
在前面的讲解中可以得知, 在得到一个RoI后, Faster RCNN通过RoI与标签的IoU值来判断该RoI是正样本还是负样本, 默认的IoU阈值为0.5, 这个阈值是一个超参数, 对于检测的精度有较大影响。
如何选择合适的阈值是一个矛盾的问题。 一方面, 阈值越高, 选出的RoI会更接近真实物体, 检测器的定位会更加准确, 但此时符合条件的RoI会变少, 正、 负样本会更加不均衡, 容易导致训练过拟合; 另一方面, 阈值越低, 正样本会更多, 有利于模型训练, 但这时误检也会增多, 从而增大了分类的误差。
对于阈值的问题, 通过实验可以发现两个现象:
·一个检测器如果采用某个阈值界定正负样本时, 那么当输入Proposal的IoU在这个阈值附近时, 检测效果要比基于其他阈值时好, 也就是很难让一个在指定阈值界定正、 负样本的检测模型对所有IoU的输入Proposal检测效果都最佳。
·经过回归之后的候选框与标签之间的IoU会有所提升。
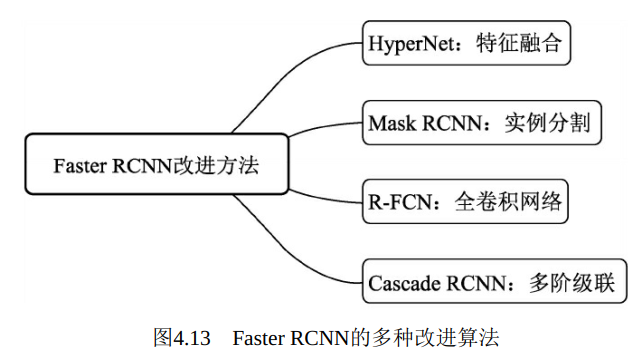
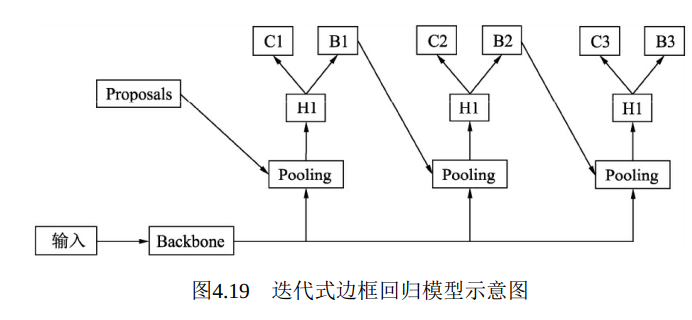
基于以上结果, 2018年CVPR上的Cascade RCNN算法通过级联多个检测器来不断优化结果, 每个检测器都基于不同的IoU阈值来界定正负样本, 前一个检测器的输出作为后一个检测器的输入, 并且检测器越靠后, IoU的阈值越高。级联检测器可以有多种形式, 如图4.19所示为迭代式的边框回归模型示意图, 图中的Pooling代表了RoI Pooling过程, H1表示RCNN部分络, C与B分别表示分类与回归部分网络。 从图中可以看出, 这种方法 将前一个回归网络输出的边框作为下一个检测器的输入继续进行回归,
连续迭代3次才得到结果。
从前面的实验可以得知, 经过一个固定IoU阈值的检测器后, 边框的IoU会提升, 分布也发生了变化, 即越来越靠近真实物体。 如果下一个检测器仍然还是这个IoU阈值的话, 显然不是一个最优的选择, 这也是上述这种级联器的问题所在。
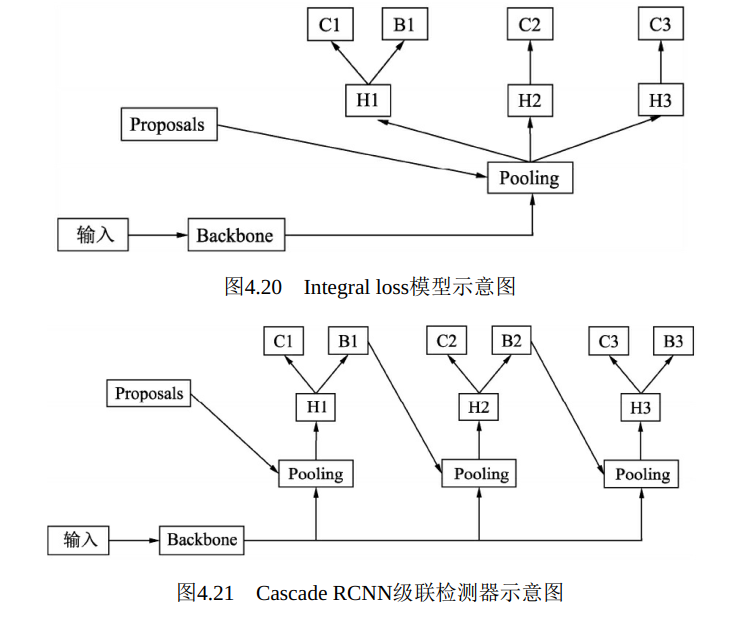
图4.20是另一种多个检测器的组合方式, 称为Integral Loss。 图中H1、 H2与H3分别代表不同的IoU阈值界定正负样本的检测器, 当阈值较高时, 预测的边框会更为精准, 但会损失一些正样本。 这种方法中多个检测器相互独立, 没有反馈优化的思想, 仅仅是利用了多个IoU阈值的检测器。
图4.21的结构则是Cascade RCNN采用的方法, 可以看到每一个检测器的边框输出作为下一个检测器的输入, 并且检测器的IoU阈值是逐渐提升的, 因此这种方法可以逐步过滤掉一些误检框, 并且提升边框的定位精度。
总体来看, Cascade RCNN算法深入探讨了IoU阈值对检测器性能的影响, 并且在不增加任何tricks的前提下, 在多个数据集上都有了明显
的精度提升, 是一个性能优越的高精度物体检测器。