主流的序列到序列模型都是基于含有encoder和decoder的复杂的循环或者卷积网络。而性能最好的模型在encoder和decoder之间加了attentnion机制。本文提出一种新的网络结构,摒弃了循环和卷积网络,仅基于attention机制。
self-attention是一种attention机制,它是在单个序列中计算每个位置与其他不同位置关系从而计算序列。Transformer是第一个完全依靠self-attention机制来计算输入和输出表示。
模型架构
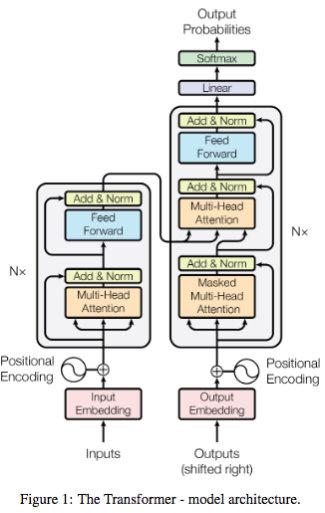
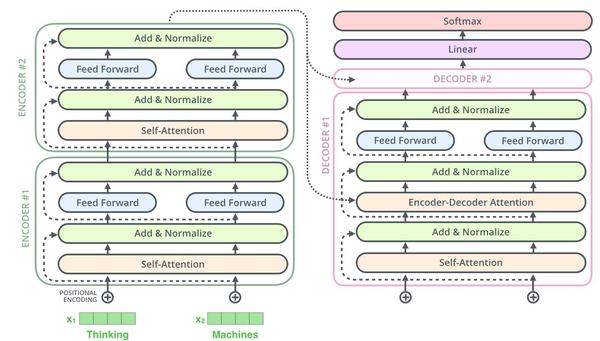
encoder
编码器由6个完全相同的层堆叠而成,每一层有两个子层,第一层是multi-head self-attention机制,第二层是简单的、位置完全连接的前馈神经网络。对每个子层都使用残差网络连接[必要性],接着进行Layer Normalization。也就是说,每个子层的输出都是LayerNorm(x + Sublayer(x)), 其中Sublayer(x)是具体子层的具体实现函数。为了方便残差连接,模型中所有子层以及嵌入层产生的输出维度都是dmodel = 512。
残差网络的优势
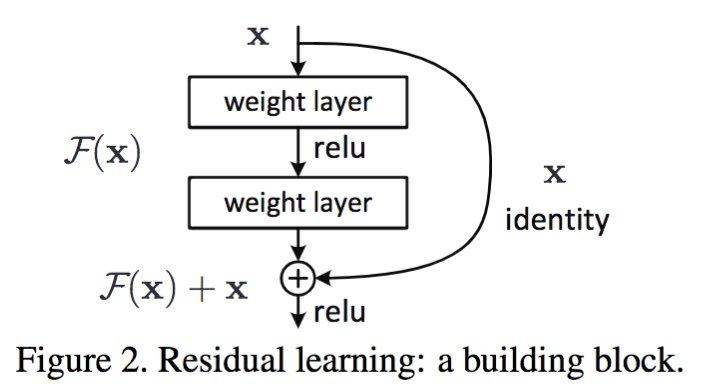
残差网络使用网络学习的是残差,能够解决网络极深度条件下性能退化问题。残差网络论文中提到残差网络不是解决梯度消失和梯度膨胀,残差网络用来解决网络层数加深,在训练集上性能变差的问题。 [为什么可以解决?] 残差网络是多个浅层网络的集成,从x到最后的输出y可以有多个路径,每个路径看作一种模型。[个人理解]
Layer Normalization
decoder
解码器同样由N=6个完全相同的层堆叠而成。除了编码器的两个子层之外,在解码器中还插入第三个子层, 该层对编码器的输出进行multi-head self-attention(中间部分),与编码器类似,解码器每个子层采用残差连接,并加LayerNormalization。在解码器中的self-attention子层需要修改,因为后面位置是不可见。具体修改就是对后面位置进行mask
attention
attention可以描述为将query和一组key-value对映射到输出,query,key, value都是向量。输出就是value的加权和,每部分的权重通过query和key之间点积或其他运算而来。
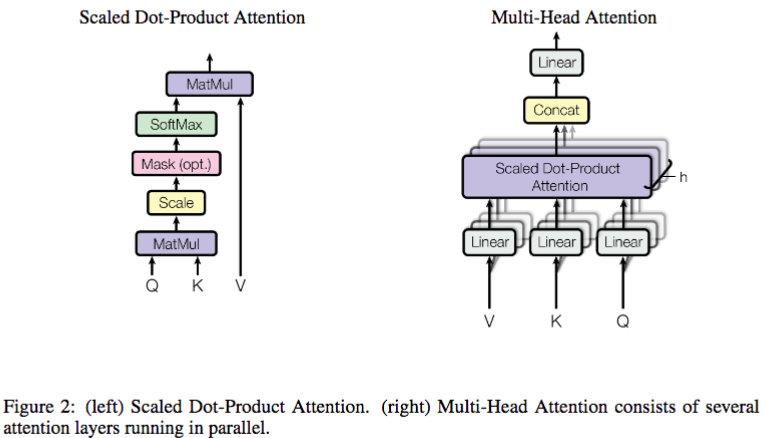
Scaled Dot-Product Attention(缩放的点积attention)
图二左边所示为Scaled Dot-Product Attention。输入包含query、dk维的keys和dv维的values。我们通过计算query和所有的keys的点积,每一个再除以根号dk,最后使用softmax获取每一个value的权重。
【为什么除以dk?】 假设两个 dk 维向量每个分量都是一个相互独立的服从标准正态分布的随机变量,那么他们的点乘的方差就是 dk,每一个分量除以 sqrt(d_k) 可以让点乘的方差变成 1。
在实际中,可以通过使用矩阵相乘的方式同时计算一组query,只需将query,keys,values打包成一个矩阵Q,K, V即可。

有两种attention方法,一种是加法[需要调研],另一种是点积。 加法是使用含有一个隐藏层的前馈神经网络,与加法attention相比,点积在时间和空间上都很高效,因为他可以通过矩阵方式实现优化。
Multi-Head Attention
将query、key和value分别映射h倍到维度dk,dk和dv,在每一个映射空间中query, key和value并行执行attention函数,产生dv维度的结果,最后将每一个空间的结果进行拼接得到 h * dv 维,即原始维度。

意义:Multi-head可以让模型在不同的位置从不同的视角进行学习,与单attention head相比学习到信息更丰富,每一个head可以并行,时间复杂度一致. 【问题】head为什么是8,不是4,16或其他?
attention在transformer中的应用
Transformer在三个地方使用了multi-head attention。 1、在encoder-decoder层,query是上一个decoder层产生,key, value来自于encoder,这可以让decoder中每一个位置都可以学习到输入序列中的信息。 2、在encoder中包含许多self-attention层,在每个self-attention层所有的key, value, query都是由上一层而来,因为每个位置都含有之前层的信息。 3、在decoder中也包含了许多self-attention层,避免看见未来现象,在decoder中加入了mask
前馈神经网络
除了attention层之外,在transformer中还包含前馈神经网络层,每个都是两层线性变换,使用RELU激活函数输入维度是512,第一层全连接的输出是2048,第二层的输出是512

embedding与softmax
同其他的序列模型相同,我们使用学习到的embedding,在网络中也使用了线性变换函数和softmax函数。在transformer中在两个嵌入层之间和pre-softmax线性变换共享相同的权重矩阵。 在嵌入层中,我们将这些权重乘以 根号dmodel??
位置编码[待补充]
why self-attention
attention与rnn,cnn对比
正则化
residual dropout
在每一个单元的输出加一个dropout层,另外在word embedding之后也使用dropout
label smoothing
参考