一、K均值聚类算法
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler
X_1 = StandardScaler().fit_transform(X)
X, y = make_blobs(n_samples=40, centers=3, random_state=50, cluster_std=2)
blobs = make_blobs(random_state=1,centers=1)
X_blobs = blobs[0]
kmeans = KMeans(n_clusters=3)
kmeans.fit(X_blobs)
x_min, x_max = X_blobs[:, 0].min()-0.5 , X_blobs[:, 0].max()+0.5
y_min, y_max = X_blobs[:, 0].min()-0.5 , X_blobs[:, 1].max()+0.5
xx, yy = np.meshgrid(np.arange(x_min, x_max, .02),
np.arange(y_min, y_max, .02))
Z = kmeans.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.figure(1)
plt.clf()
plt.imshow(Z, interpolation='nearest',
extent=(xx.min(), xx.max(), yy.min(), yy.max()),
cmap=plt.cm.summer,
aspect='auto', origin='lower')
plt.plot(X_blobs[:, 0], X_blobs[:, 1], 'r.', markersize=5)
centroids = kmeans.cluster_centers_
plt.scatter(centroids[:, 0], centroids[:, 1],
marker='x', s=150, linewidths=3,
color='b', zorder=10)
plt.xlim(x_min, x_max)
plt.ylim(y_min, y_max)
plt.xticks(())
plt.yticks(())
plt.show()


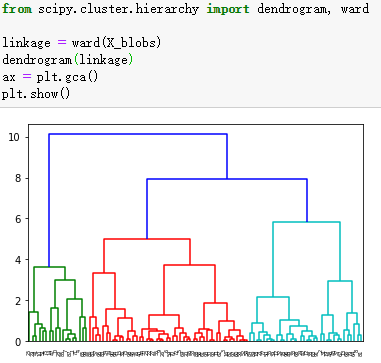
二、凝聚聚类算法工作原理展示
from scipy.cluster.hierarchy import dendrogram, ward
linkage = ward(X_blobs)
dendrogram(linkage)
ax = plt.gca()
plt.show()
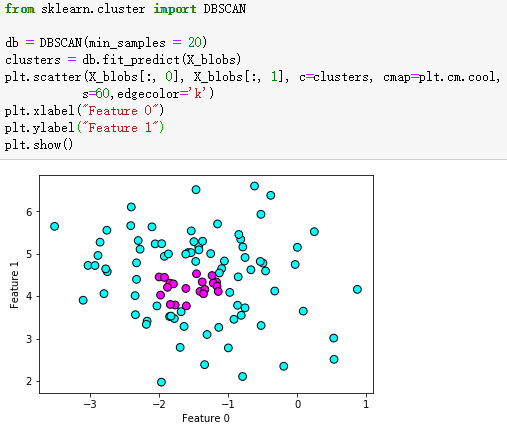
三、DBSCAN算法对make_blobs数据集的聚类结果
from sklearn.cluster import DBSCAN
db = DBSCAN(min_samples = 20)
clusters = db.fit_predict(X_blobs)
plt.scatter(X_blobs[:, 0], X_blobs[:, 1], c=clusters, cmap=plt.cm.cool,
s=60,edgecolor='k')
plt.xlabel("Feature 0")
plt.ylabel("Feature 1")
plt.show()