
图 1 -1 Profiler 入口
要分析独立应用程序 需要勾选以下量两项,否则不精准
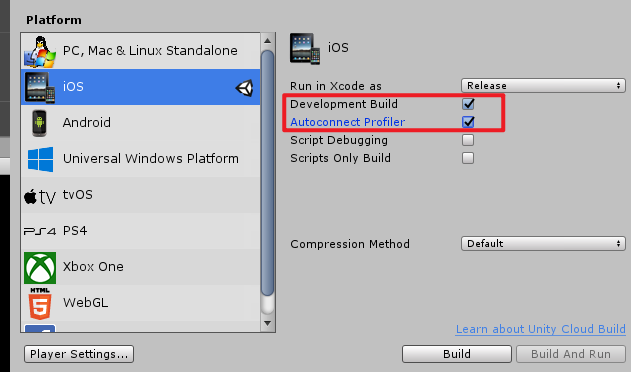
图 1- 2 启动标志
打开Profiler ,
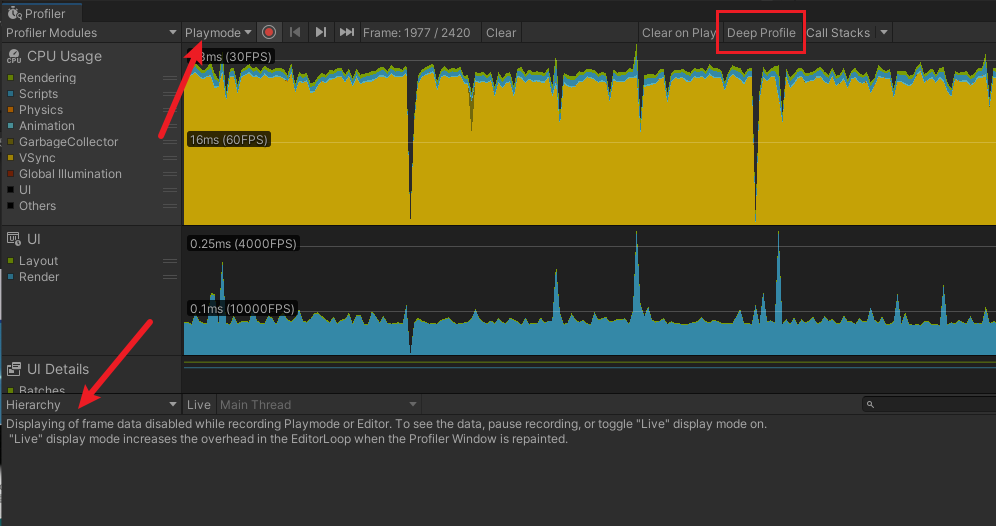
图 1-3 Profiler 界面常规设置
PlayModel :运行模式下 我们就用这个
Hierarchy: 表示浏览视图 选择这个 便于观察
DeepProfiler:表示深层次探测,选中此选项 会重新编译项目,而且堆栈信息比较全面,层次太深,不方便查看。一般不需要选中。
我们经常听说帧率:每秒 30Fps ,45FPS , 60FPS ,那么每帧的时间是多少? 1秒是1000ms,每帧的时间 = 1000 / 帧率 。如果游戏设定是30FPS ,那每帧的时间是 1000 / 30 = 33.3ms ,也就是说 留给CPU 每帧计算的时间只有 33.3ms.
可以通过API 强制设置帧率:Application.targetFrameRate = 30 ,设置-1为不限制帧率,同时 我们要关闭掉 垂直同步Vsync。垂直同步:应用程序的帧率会受监视器的帧率限制。
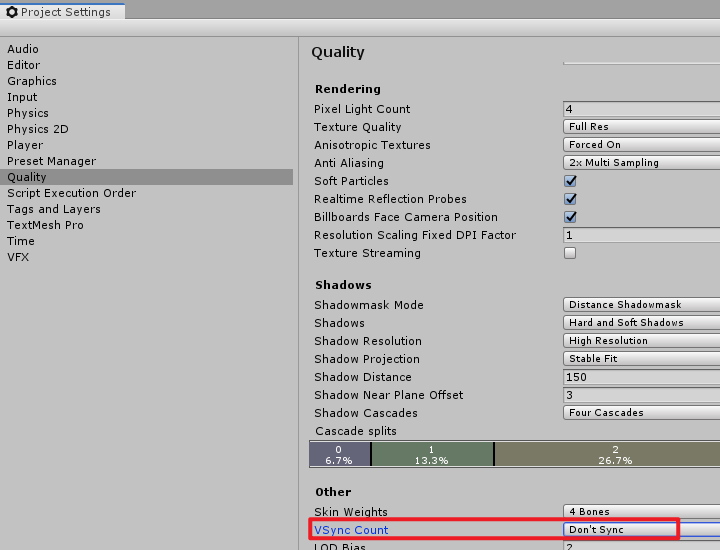
图 1- 4 关闭垂直同步
运行游戏 ,点击游戏中的球员管理,里面是有2000多张卡牌的 需要计算战力的,比较耗时。

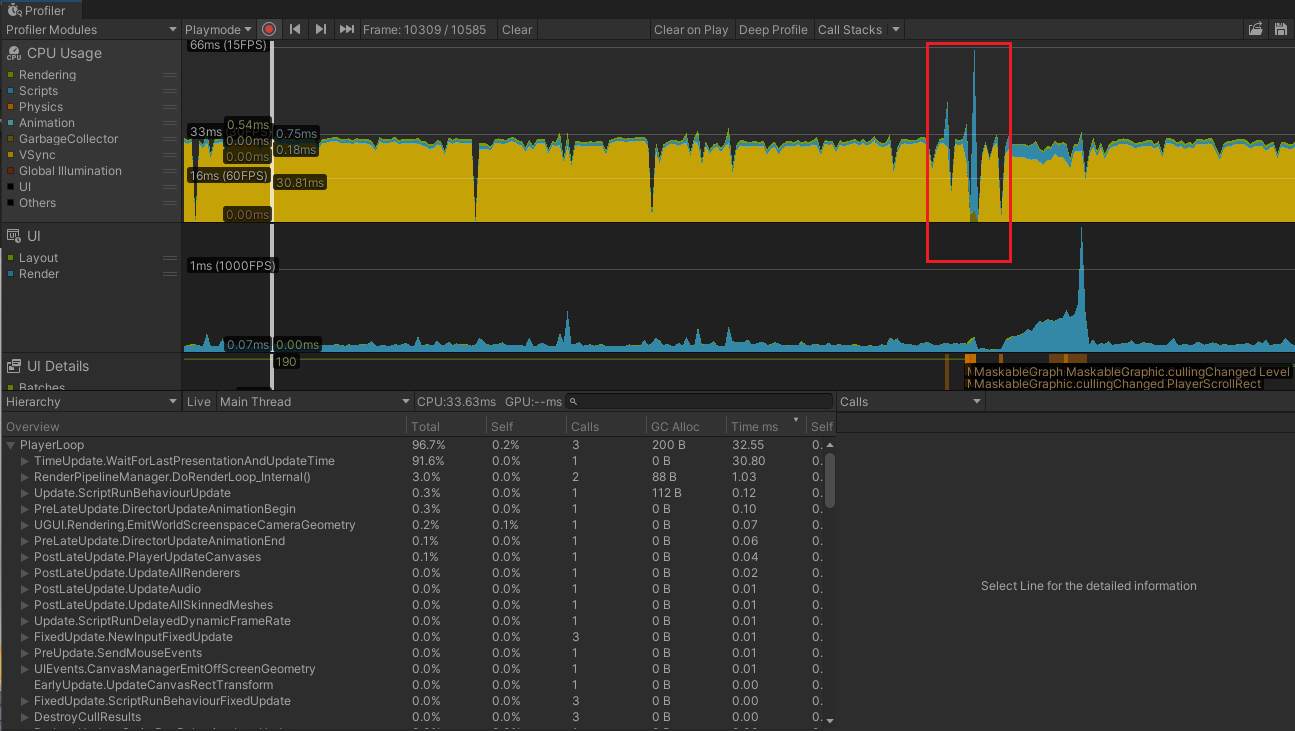
图 1-5 打开球员管理界面 有一个瞬间高峰
用鼠标选中高峰,查看此时的 GC及相应的耗时
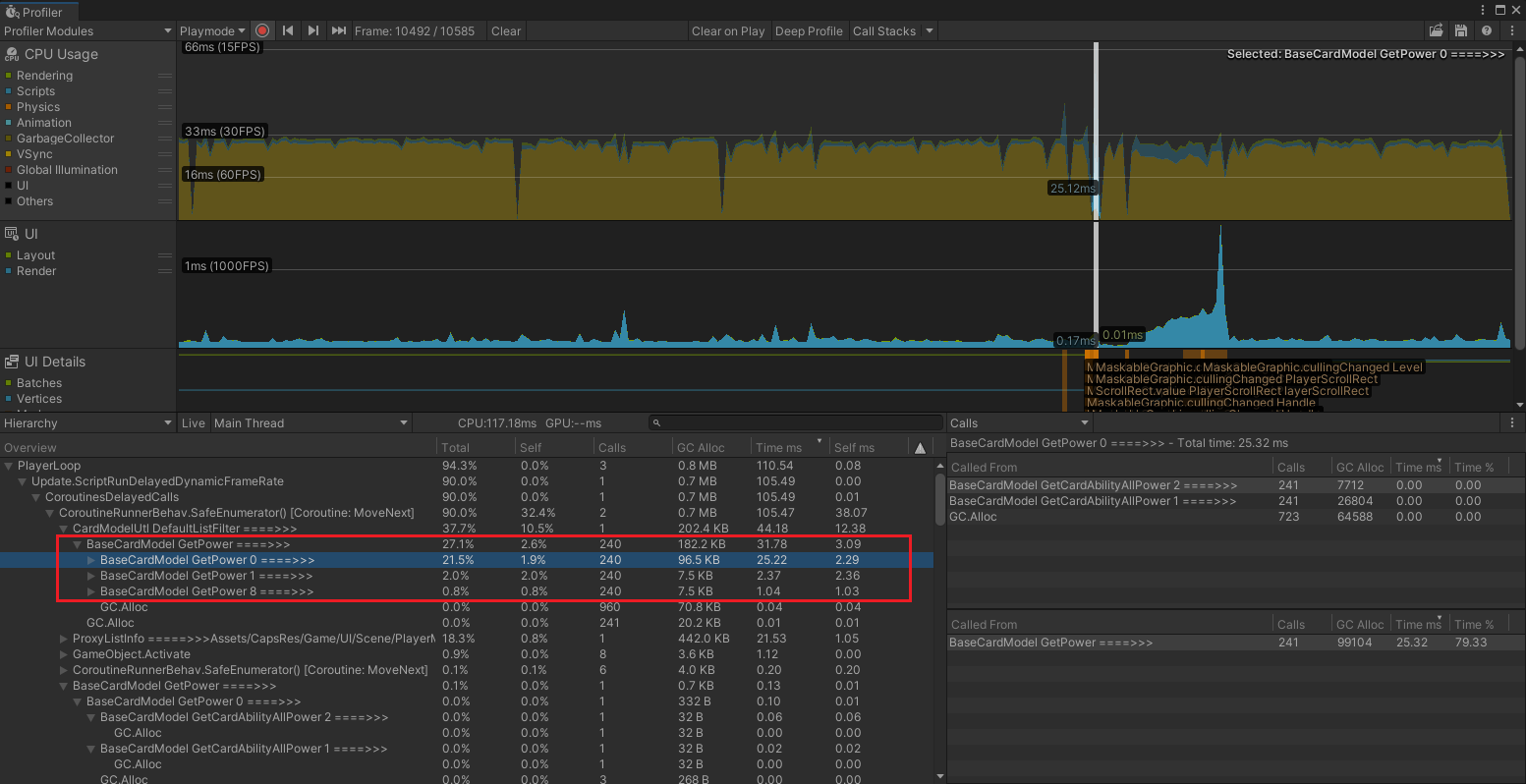
图1- 6 打开球员管理 标记耗时操作
GetPower 耗时 31.78毫秒,其中 GetPower0 25.22毫秒
那么这些BaseCardModel xxx =====>>> 是怎么来的呢? 使我们在代码中写的,便于识别:
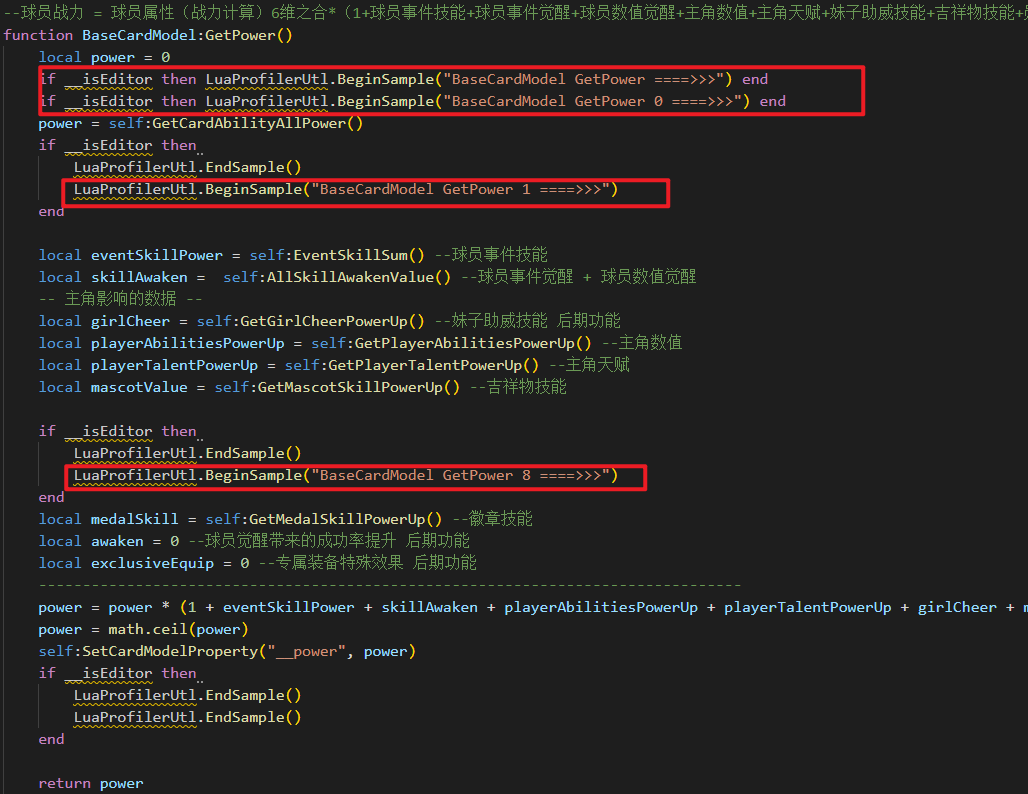
图 1-7 代码采样
代码中BeginSample 一层套一层,在Profiler窗口中也是如此展示,为了便于得知每一层的耗时是多少。

图 1-8 不同层次的耗时
打开发现 GetPower0 里面还有2层 , 这是因为:我们调用了GetCardAbilityAllPower() 方法

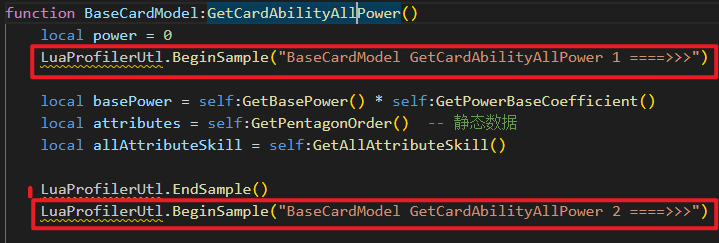
这里也是为了 弄清楚 耗时出现在一块,便于我们去优化。
LuaProfilerUtl 的代码 仅对 Profiler采样进行简单的封装,会了更加便于获知 耗时。代码如下:


1 local LuaProfilerUtl = {}
2 local _isOpen = Application.isEditor == true or is_show_profiler_log == true
3 local __profilerMap = {}
4
5 local function _getkey(...)
6 local par = { ... }
7 local key = ""
8 for _, value in pairs(par) do
9 if key == "" then
10 key = tostring(value)
11 else
12 key = key .."_"..tostring(value)
13 end
14 end
15 end
16
17 function LuaProfilerUtl.Begin(...)
18 if _isOpen == false then return end
19 local key = _getkey(...)
20 __profilerMap[key] = Time.realtimeSinceStartup
21 end
22
23
24 function LuaProfilerUtl.End(...)
25 if _isOpen == false then return end
26 local key = _getkey(...)
27 if type(__profilerMap[key]) ~= "number" then return end
28 if is_show_profiler_log then
29 print(key.. "======>" .. string.format("%.4f", Time.realtimeSinceStartup - __profilerMap[key] ))
30 else
31 print(key.. "======>" .. string.format("%.4f", Time.realtimeSinceStartup - __profilerMap[key] ))
32 end
33 end
34
35 function LuaProfilerUtl.BeginSample(...)
36 if _isOpen == false then return end
37 local key = _getkey(...)
38 Profiler.BeginSample(key)
39 end
40
41 function LuaProfilerUtl.EndSample(params)
42 if _isOpen == false then return end
43 Profiler.EndSample()
44 end
45
46 return LuaProfilerUtl
继前面说的FPS,我们切换到Timeline 视图,如图 1-5 ,高峰耗时达到73.87ms , 1000 / 73.87ms = 13.5FPS 。数据太多,cpu计算耗时,界面打开一瞬间FPS降低。 GPU 在未收到CPU的数据期间一直处于等待状态。


图1-9Timeline 视图
Gfx.WaitForGfxCommandsFormMainThread:GPU正在等待CPU完成计算,GPU处于空闲阶段。
由此我们可以得出:性能瓶颈是卡在CPU 还是GPU ,便于我们进一步的精准优化。