一. lamda匿名函数
为了解决一些简单的需求而设计的一句话函数# 计算n的n次方
#先用之前的函数办法 def func(n): return n**2 print(func(9)) #用lambda方法: a = lambda n : n*n print(a(9))
lambda表示的是匿名函数 不需要用def声明
语法:
函数名 = lambda 参数 : 返回值
而匿名函数返回的是lambda,所有函数都叫lambda
注意:
1.函数可以参数可以有多个,多个参数用逗号隔开
2.匿名函数不管有多复杂,只能写一行,且逻辑结束后返回数据
3.返回值和函数一样,可是任意数据类型
匿名函数并不是说没有名字,这里前面的变量就是一个函数名,说他是匿名的原因是我们通过__name__查看的时候是没有名字的,统一叫做lambda,在调用的时候没有什么特别之处,和正常函数调用即可
#若传100个数,选出最大值 fn = lambda*arg :max(arg)
print(fn(let))
二.sorted()排序函数
语法:sorted(Iterable可迭代的,key = None,reverse翻转 = False)
key = 排序方案 sorted函数内部会把可迭代对象中的每一个元素拿出来交给后面的key 后面的key计算出一个数,作为这个元素的权重 整个函数根据权重来进行计算
lst= [{"褚熙":"大傻子"},{"刘伟":"牛"},{"王玉杰":"狗"},{"曾老师":"五行之外"}]
def func(x):
for i in x:
return len(x[i])
print(sorted(lst,key=func,reverse=True))
lst = [{"id": 1, "name": 'alex', "age": 18},
{"id": 2, "name": 'wusir', "age": 16},
{"id": 3, "name": 'taibai', "age": 17}]
按照年龄对学⽣信息进⾏排序
def func(x):
return x["age"]
a = lambda x : x["age"]
print(sorted(lst,key=lambda x : x["age"],reverse= True))
lis =[22,27,31,64,48,5,22,46,18]
print(sorted(list(filter(lambda age :age>=18 and age % 2 == 0,lis))))
三.filter() 过滤(筛选)函数
语法:filter(function,Iterable 可迭代对象)
function:用来筛选的函数,在filter中会自动把iterable中的元素传递给function 根据function返回的True或者FALSE来判断保留此数据
lst = [{"id": 1, "name": 'alex', "age": 18},
{"id": 2, "name": 'wusir', "age": 16},
{"id": 3, "name": 'taibai', "age": 17}]
print(list(filter(lambda x :x["age"] >17,lst)))
print([i for i in lst if i["age"]>17])
四.map 映射函数
语法:map(function,iterable)可以对可迭代对象中的每一个元素进行映射,分别取执行function
#用map计算列表的平方 返回一个新列表 def func(i): return i*i mp = map(func,[1,2,3,4,5] print(mp)#出来的是内存地址 print(list(mp))#强制转换成列表的形式 #写成lambda print(list(map(lambda x :x*x))) #将数字排序 lst = [1,5,9,3,5,7] print(sorted(list(map(lambda num : num +1,lst)),reverse = True))
五,递归
在函数中调用函数本身,就是递归
def func(): print("你开心吗?") func() func()
求递归的深度
def func(n): print(n) n += 1 func(n) func(1)
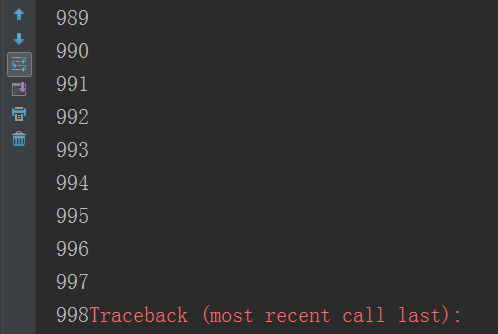
这里的默认值是1000 但是你要是改的话是可以的,引入一个模块
import sys
sys.setreursionlimit(5000) 但是一般不建议修改
import os def func(file_path,index=0):#file_path 路径 lst = os.listdir(file_path) #os.listdir()拿到指定路径下的文件名 for file_name in lst: #全局路径 path_abs = os.path.join(file_path,file_name)#在os模块下面拿到path(路径类)下的jion方法 if os.path.isdir(path_abs):#如果这个路径是一个文件夹的话 print(" "*index,file_name) func(path_abs,index+1) else: print(" "*index,file_name) func("f:KuGou")
六,二分法
# 二分法查找的效率特别高. # 缺点: 有序序列 # # lst = [1,8,16,32,55,78,89,1,5,4,7,5,9,6,8,5,4,5,44,5,2,1,4,5,1] # # [1, 1, 1, 1, 2, 4, 4, 4, 5, 5, 5, 5, 5, 5, 6, 7, 8, 8, 9, 16, 32, 44, 55, 78, 89] # lst = sorted(lst) # n = int(input("请输入一个数:")) # left = 0 # right = len(lst) - 1 # while left <= right: # mid = (left + right) // 2 # 索引只能是整数 if n > lst[mid]: left = mid + 1 elif n < lst[mid]: right = mid - 1 else: print("在这个列表中.所在的位置%s" % mid) break else: print("你要找的数. 不在这个序列中") # 递归的第一套方案 def func(n, lst): left = 0 right = len(lst) - 1 if left <= right: mid = (left + right)//2 if n > lst[mid]: new_lst = lst[mid+1:] return func(n, new_lst) elif n < lst[mid]: new_lst = lst[:mid] return func(n, new_lst) else: print("刚刚好, 在这里出现了") return True else: return False lst = [1, 1, 1, 1, 2, 4, 4, 4, 5, 5, 5, 5, 5, 5, 6, 7, 8, 8, 9, 16, 32, 44, 55, 78, 89] ret = func(2, lst) print(ret) # 第二套方案 def func(n, lst, left=0, right=None): if right == None: right = len(lst) - 1 if left <= right: mid = (left + right) // 2 if n > lst[mid]: left = mid + 1 elif n < lst[mid]: right = mid - 1 else: return True return func(n, lst, left, right) else: return False